インテル® Advisor のオフロードのモデル化パースペクティブを使用すると、ターゲットのグラフィックス・プロセッシング・ユニット (GPU) デバイス上のアプリケーションのパフォーマンスをモデル化し、ターゲット GPU で実行すると最も収益性の高いコード領域を特定できます。
オフロードのモデル化パースペクティブには 2 つのワークフローがあります。
- CPU から GPU へのモデル化を使用すると、CPU 上で実行されているアプリケーションをプロファイルし、ターゲット GPU デバイス上でそのパフォーマンスをモデル化して、アプリケーションの一部を GPU にオフロードする必要があるかどうかを判断できます。
- GPU から GPU へのモデル化を使用すると、GPU 上で実行されているアプリケーションをプロファイルし、ターゲット GPU デバイス上でそのパフォーマンスをモデル化して、別のターゲットでアプリケーションを実行することで得られる潜在的なスピードアップを見積もることができます。
ここでは、CPU から GPU へのモデル化を使用して vector-add サンプルをプロファイルし、ターゲット GPU でのスピードアップを見積もる方法について説明します。
次の操作を行います。
必要条件
- GitHub* リポジトリーの oneAPI サンプルから vector-add サンプルコードをダウンロードします。
自身のアプリケーションを使用して、以下の手順に従うこともできます。
- インテル® Advisor は、スタンドアロン製品 (英語) またはインテル® oneAPI ベース・ツールキットの一部 (英語)としてインストールできます。インストール手順については、ユーザーガイドのインテル® Advisor のインストールを参照してください。
- インテル® oneAPI DPC++/C++ コンパイラーをスタンドアロン (英語) として、またはインテル® oneAPI ベース・ツールキットの一部 (英語) としてインストールします。インストール手順については、インテル® oneAPI ツールキットのインストール・ガイド (英語) を参照してください。
- インテル® Advisor およびインテル® oneAPI DPC++/C++ コンパイラーの環境変数を設定します。例えば、インストール・ディレクトリーで setvars スクリプトを実行します。
このドキュメントでは、ツールがデフォルトの場所にインストールされていることを前提としています。ツールを別の場所にインストールした場合は、以下のコマンドのデフォルトパスを必ず置き換えてください。
重要
環境変数を設定した後、ターミナルまたはコマンドプロンプトを閉じないでください。閉じると環境がリセットされます。
アプリケーションのビルド
Linux*
環境変数を設定したターミナルから:
- vector-add サンプル・ディレクトリーに移動します。
- 次のコマンドでアプリケーションをコンパイルします。
icpx -g -fiopenmp -fopenmp-targets=spir64 -fsycl src/vector-add-buffers - 次のように、ベクトルサイズ 100000000 でアプリケーションを実行し、ビルドを確認します。
./vector-add-buffers 100000000アプリケーションが正常にビルドされていると、次のような出力が表示されます。
Vector size: 100000000 [0]: 0 + 0 = 0 [1]: 1 + 1 = 2 [2]: 2 + 2 = 4 ... [99999999]: 99999999 + 99999999 = 199999998 Vector add successfully completed on device.
vector-add-buffers アプリケーションは SYCL* を使用し、デフォルトでは GPU 上で実行されます。トピックのワークフローでは、以下のセクションで説明するように、一時的に CPU にオフロードして解析する必要があります。
Windows*
環境変数を設定したコマンドプロンプトから:
- vector-add サンプル・ディレクトリーに移動します。
- 次のコマンドでアプリケーションをコンパイルします。
icx-cl -fsycl /O2 /EHsc /Zi -o vector-add-buffers.exe src/vector-add-buffers.cpp - 次のように、ベクトルサイズ 100000000 でアプリケーションを実行し、ビルドを確認します。
vector-add-buffers.exe 100000000アプリケーションが正常にビルドされていると、次のような出力が表示されます。
ベクトルサイズ: 100000000 [0]: 0 + 0 = 0 [1]: 1 + 1 = 2 [2]: 2 + 2 = 4 ...[99999999]: 99999999 + 99999999 = 199999998 デバイス上でベクトルの追加が正常に完了しました。
vector-add-buffers アプリケーションは SYCL* を使用し、デフォルトでは GPU 上で実行されます。トピックのワークフローでは、以下のセクションで説明するように、一時的に CPU にオフロードして解析する必要があります。
GPU 上で実行されるアプリケーションのパフォーマンスをモデル化します
グラフィカル・ユーザー・インターフェイス (GUI) からオフロードのモデル化を実行
- 環境変数を設定したターミナルまたはコマンドプロンプトから、インテル® Advisor GUI を起動します。
advisor-gui - vector-add-buffers アプリケーション用の vector-add プロジェクトを作成します。始める前にの指示に従ってください。プロジェクトを作成すると、[Project Properties (プロジェクトのプロパティー)] ダイアログボックスが開きます。
- [Analysis Target (解析ターゲット)] タブ > [Survey Analysis Types (サーベイ解析タイプ)] > [Survey Hotspots Analysis (サーベイ・ホットスポット解析)] に移動します。
- [Application (アプリケーション)] フィールドにある [Browse… (参照)] をクリックし、vector-add-buffers アプリケーションに移動します。[Open (開く)] をクリックします。
- ベクトルサイズを設定するには、[Application parameters (アプリケーション・パラメーター)] フィールドに 100000000 を入力します。
- アプリケーションを一時的に CPU にオフロードするには、[User-defined environment variables (ユーザー定義の環境変数)] フィールドの近くにある [Modify… (変更)] をクリックします。[User-defined Environment Variables (ユーザー定義環境変数)] ダイアログボックスが開きます。
- [Variable (変数)] カラムの空白行をクリックし、変数名 SYCL_DEVICE_FILTER を入力します。
- [Value (値)] カラムの空白行をクリックし、変数値 opencl:cpu を入力します。
- [OK] をクリックして変更を保存します。
- [Analysis Target (解析ターゲット)] タブ > [Survey Analysis Types (サーベイ解析タイプ)] > [Trip Counts and FLOP Analysis (トリップカウントと FLOPS 解析)] に移動し、[Inherit Settings from Survey Hotspots Analysis Type (サーベイ・ホットスポット解析タイプから設定を継承)] チェックボックスが選択されていることを確認します。
- [OK] をクリックして、プロジェクトを作成します。
- [Perspective Selector (パースペクティブ・セレクター)] ウィンドウで [Offload Modeling (オフロードのモデル化)] パースペクティブを選択します。
- [Analysis Workflow (解析ワークフロー)] ペインで以下のパラメーターを選択します。
- ベースライン・デバイスが CPU に設定されていることを確認します。
- 精度を [Medium (中)] に設定します。
- [Gen11 GT2] ターゲットデバイスを選択します。
 ボタンをクリックしてパースペクティブを実行します。
ボタンをクリックしてパースペクティブを実行します。中程度の精度でパースペクティブ実行中、インテル® Advisor は次のことを行います。
- サーベイ解析を使用して、アプリケーションの合計実行時間とループ/関数の実行時間を解析します。
- 特性解析を使用して、アプリケーション実行中に各サイクルが実行する反復回数をカウントします。
- パフォーマンスのモデル化解析を使用して、ターゲット GPU にオフロードできるコード領域の実行時間と、CPU からターゲット GPU にデータを転送する合計時間を推定します。
実行が完了すると、オフロードのモデル化の結果が自動的に開きます。
コマンドライン・インターフェイス (CLI) からオフロードのモデル化を実行
Linux* では
環境変数を設定したコマンドプロンプトから:
- vector-add サンプル・ディレクトリーに移動します。
- 次のように、SYCL_DEVICE_FILTER 環境変数を使用してアプリケーションを一時的に CPU にオフロードします。
export SYCL_DEVICE_FILTER=opencl:cpu - コマンドライン収集プリセットを使用して、中程度の精度レベルでオフロードのモデル化パースペクティブを実行します。
advisor --collect=offload --config=gen11_icl --project-dir=./vector-add -- vector-add-buffers 100000000このコマンドは、デフォルトの中精度レベルのオフロードのモデル化パースペクティブ解析を 1 つずつ実行します。パースペクティブ実行中、インテル® Advisor は次のことを行います。
- サーベイ解析を使用して、アプリケーションの合計実行時間とループ/関数の実行時間を解析します。
- 特性解析を使用して、アプリケーション実行中に各サイクルが実行する反復回数をカウントします。
- パフォーマンスのモデル化解析を使用して、ターゲット GPU にオフロードできるコード領域の実行時間と、CPU からターゲット GPU にデータを転送する合計時間を推定します。
実行が完了すると、オフロードのモデル化の結果を含む vector-add プロジェクトが自動的に作成されます。任意の方法で表示できます。
Windows* では
環境変数を設定したコマンドプロンプトから:
- vector-add サンプル・ディレクトリーに移動します。
- 次のように、SYCL_DEVICE_FILTER 環境変数を使用してアプリケーションを一時的に CPU にオフロードします。
set SYCL_DEVICE_FILTER=opencl:cpu - コマンドライン収集プリセットを使用して、中程度の精度レベルでオフロードのモデル化パースペクティブを実行します。
advisor --collect=offload --config=gen11_icl --project-dir=.\vector-add -- vector-add-buffers.exe 100000000このコマンドは、デフォルトの中精度レベルのオフロードのモデル化パースペクティブ解析を 1 つずつ実行します。パースペクティブ実行中、インテル® Advisor は次のことを行います。
- サーベイ解析を使用して、アプリケーションの合計実行時間とループ/関数の実行時間を解析します。
- 特性解析を使用して、アプリケーション実行中に各サイクルが実行する反復回数をカウントします。
- パフォーマンスのモデル化解析を使用して、ターゲット GPU にオフロードできるコード領域の実行時間と、CPU からターゲット GPU にデータを転送する合計時間を推定します。
実行が完了すると、オフロードのモデル化の結果を含む vector-add プロジェクトが自動的に作成されます。任意の方法で表示できます。
GPU 上で推測されるアプリケーションのパフォーマンスを調査します
GUI を使用してデータの収集が完了するとインテル® Advisor は結果を自動的に開きます。
CLI を使用してデータを収集したら、次のコマンドを使用して GUI で結果を開きます。
advisor-gui ./vector-add結果が自動的に開かない場合は、[Show Result (結果を表示)] をクリックします。
インタラクティブな HTML レポートで結果を表示することもできます。レポートのデータと構造は GUI の結果と類似しています。インテル® Advisor がインストールされていない場合でも、このレポートを共有したり、リモートシステムで開いたりできます。詳細については、インテル® Advisor ユーザーガイドのスタンドアロン HTML レポートの操作を参照してください。
注
レポートを開いたときに表示される結果は、ベースライン・デバイスまたはシステムの特性が異なるため、次のセクションに表示されるものとは異なる場合があります。結果解析ワークフロー全体を理解するため、セクションを確認することもできます。アプリケーション全体のパフォーマンスの見積もりを調査
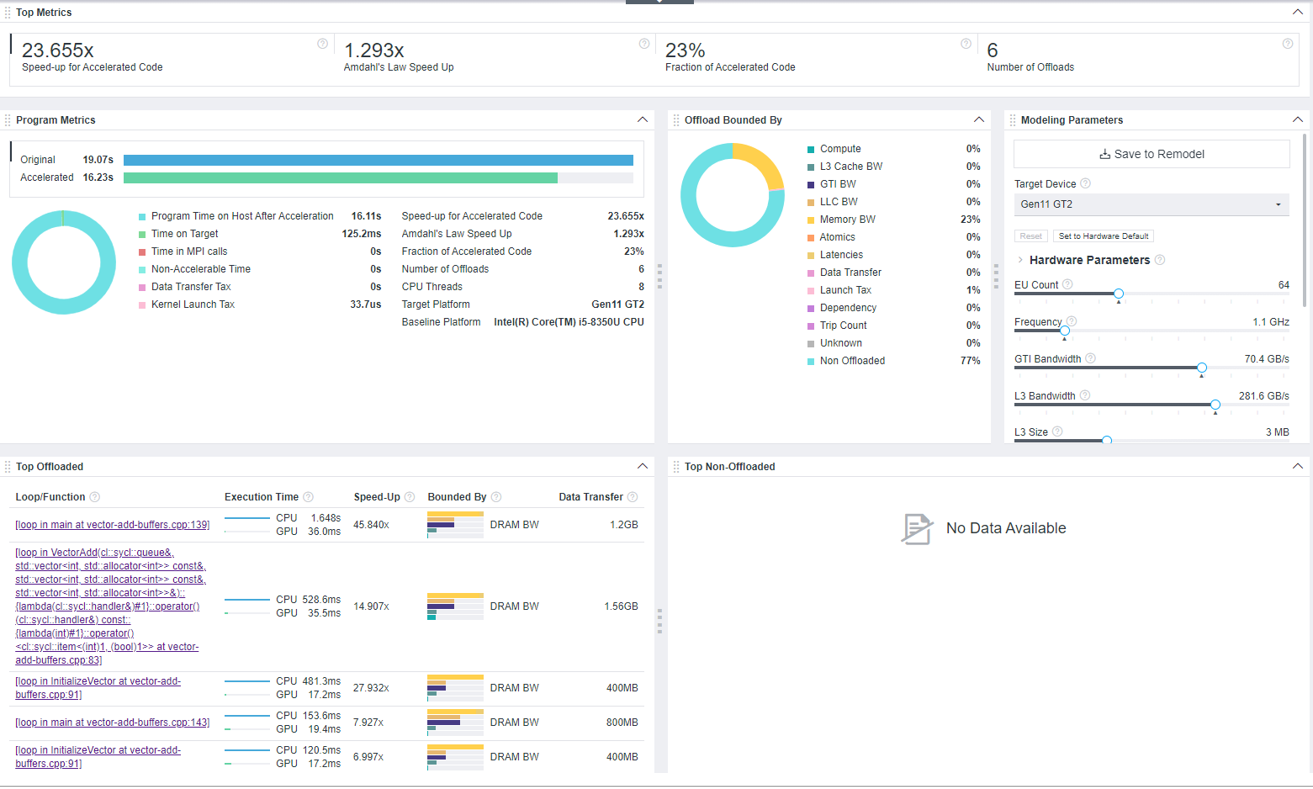
GUI でオフロードのモデル化の結果を開くと、インテル® Advisor は最初に [Summary (サマリー)] タブを表示します。このウィンドウは、ベースライン・デバイスで測定され、ターゲット GPU で推定されたアプリケーション実行、推定されるスピードアップなどに関する情報を含むダッシュボードです。
[Summary (サマリー)] ウィンドウでは、次の点に注意してください。
- [Top Metrics (上位メトリック)] ペインに示されているように、vector-add-buffers コードのオフロード部分のスピードアップの推定値は 23.655 倍ですが、アムダールの法則によって計算されたスピードアップ (アプリケーション全体) は 1.293 倍にすぎません。つまり、オフロードされたコード領域は GPU 上でより高速に実行できますが、アプリケーション全体のスピードアップには大きな影響はありません。コードの 23% のみがオフロードに推奨されていることが原因である可能性があります。
- [Program Metrics (プログラムメトリック)] ペインでアプリケーションごとのメトリックを調べます。ターゲット GPU での推定時間 (加速時間) は 16.23 秒で、これにはホストデバイスでの 16.11 秒とターゲットデバイスでの 125.2 ミリ秒が含まれます。
- [Offload Bounded By (オフロードの制限)] ペインで、オフロードされたコード領域を制限する要因を調査します。このペインには、計算、データ転送、レイテンシーなど、アプリケーション全体の潜在的なすべてのボトルネックが、影響を受けるコードの特性とともに表示されます。
vector-add-buffers アプリケーションでは、コードの 77% がオフロードされてません。オフロードされたコードは、主にホストメモリー帯域幅 (23%) によって制限されます。つまり、アプリケーションは、ホストデバイス上のメモリーリソースを十分に活用できていないため、オフロード後にメモリーの制限を受ける可能性があるということです。オフロード後にアプリケーションがメモリーを使用する方法を最適化したり、メモリー帯域幅を増加させたりすると、アプリケーションのパフォーマンスが向上する可能性があります。
[Bounded By (制限される要因)] カラムの図にマウスカーソルを移動すると、[Top Offloaded (上位オフロード)] ペインでコード領域ごとのボトルネックを確認できます。
- [Hardware Parameters (ハードウェア・パラメーター)] ペインで、モデル化された Gen11 GT2 デバイスのホストメモリー帯域幅が 48 GB/秒であることを確認します。
ペイン内の [Memory BW (メモリー BW)] スライダーを動かして値を増やし、コマンドラインからより高いメモリー帯域幅を持つカスタムデバイスのアプリケーション・パフォーマンスを再モデル化できます。より正確なパフォーマンス予測が得られる可能性があります。
このペインを使用して GPU パラメーターを調整し、カスタム・パラメーターを使用して別のデバイスでのパフォーマンスをモデル化できます。
- [Top Offloaded (上位オフロード)] ペインで、GPU へのオフロードによって最もスピードアップしたループ/関数を調べます。最上位のループ [loop in main at vector-add-buffers.cpp:139] は、ターゲット上で最も高いスピードアップが予測されます。ループをクリックすると、[Accelerated Regions (アクセラレート領域)] タブに切り替わり、ターゲット GPU 上のループのパフォーマンスをより詳しく調べることができます。
特定のループの推定パフォーマンスを解析する
[Accelerated Regions (アクセラレート領域)] タブでは、各ループの推定パフォーマンスを解析し、どのループをターゲット GPU にオフロードすべきか確認できます。
![オフロードのモデル化の [Accelerated Regions (アクセラレート領域)] ウィンドウを調査し、各ループの推定パフォーマンスを解析し、どのループをターゲット GPU にオフロードすべきか確認します。](GUID-45445FCC-0AD1-462B-9C12-80B71E86C515-low.png)
インテル® Advisor は、ターゲット GPU にオフロードすると潜在的に有益なループ/関数が 5 つあると報告しています。
- 下部のペインで、[Source (ソース)] タブに切り替えて、コード領域のソースを調べます。
- [Code Regions (コード領域)] ペインで各ループをクリックし、[Source (ソース)] タブでソースを調べて、コード領域の目的を理解します。
- [loop in main at vector-add-buffers.cpp:139] は、ホストデバイス上で実行され、メインループの実行結果と比較されるループです。
- [loop in VectorAdd(…)<…> at vector-add-buffers.cpp:83] は、ベクトルを加算するメイン ループです。これは SYCL* カーネルです。
- [loop in main at vector-add-buffers.cpp:143] は、ホストデバイス上で実行される [loop in VectorAdd(…)<…> at vector-add-buffers.cpp:83] と [loop in main at vector-add-buffers.cpp:139] の結果を比較するループです。
- [loop in VectorAdd(…)<…> at vector-add-buffers.cpp:91] は、データを初期化するループです。
- [loop in [TBB worker at private_server.cpp:265] は、下位の oneAPI スレッディング・ビルディング・ブロックのループです。
アプリケーションのソース解析によると、[loop in VectorAdd(…)<…> at vector-add-buffers.cpp:83] が唯一のオフロード候補です。
- [Code Regions (コード領域)] ペインの [loop in VectorAdd(…)<…> at vector-add-buffers.cpp:83] ループをクリックして、パフォーマンスを詳細に解析し、次のメトリックを調べます。
- ベースライン CPU デバイスで測定された元の時間は 528.6 ミリ秒 ([Measured (測定)] カラムグループ)、オフロード後のターゲット GPU での推定時間は 36 ミリ秒 ([Basic Estimates Metrics (基本推定メトリック)] カラムグループ) であり、これはターゲット GPU での合計推定時間の 14.907% です。これは、[Basic Estimates Metrics (基本推定メトリック)] の [Speed-Up (ピードアップ)] カラムで報告されているように、コード領域がターゲット上で 45.840 倍高速に実行できることを意味します。
- [Summary (サマリー)] ウィンドウでは、アプリケーションがターゲット GPU 上で主にメモリー依存であることがわかりました。[Bounded By (制限される)] カラム ([Basic Estimated Metrics (基本推定メトリック)]) に示されているように、選択されたコード領域は DRAM 帯域幅によって制限されています。
- 右にスクロールして、[Estimated Bounded By (推測される制限)] カラムグループに移動します。[Throughout (スループット)] カラムに示されているように、コード領域は DRAM メモリーからの読み取りと書き込みに 32.9 ミリ秒を費やしています。
- Estimated Data Transfer with Reuse (再利用による推定データ転送) までスクロールして、ホストとターゲットデバイス間でモデル化された推定データ・トラフィックを確認します。
- [Memory Estimations (メモリー推定)] カラムグループまで右にスクロールすると、キャッシュ・シミュレーション解析でモデル化されたターゲットデバイスのメモリーレベル間のトラフィックが表示されます。カラムグループには、L3 キャッシュ、ラストレベル・キャッシュ (LLC)、DRAM メモリー、GTI メモリーなど、ターゲット上の各メモリー・レベルのトラフィックが表示されます。
- 右側の [Details (詳細)] ペインで、選択したコード領域のパフォーマンスのサマリーを調べます。ペインに報告されているように、コード領域の合計推定時間は 36 ミリ秒で、これには次のものが含まれます。
- ベクトル加算の計算に 5.4 ミリ秒
- DRAM の読み取りと書き込みに 32.9 ミリ秒
- L3 キャッシュの読み取りと書き込みに 5.6 ミリ秒
- ラスト・レベル・キャッシュ (LLC) への書き込みに 16.8 ミリ秒
コード領域はメモリーの操作にほとんどの時間を費やしています。
- 選択したループに対する実用的な推奨事項を [Recommendations (推奨事項)] タブで表示します。インテル® Advisor は、推定スピードアップが高いことから、選択したループをターゲットにオフロードすることを推奨します。推奨事項には、SYCL* または OpenMP* を使用してループをオフロードするサンプルコードが含まれており、拡張すると詳細な構文を確認できます。
また、[Top-Down (トップダウン)] タブを使用して選択したループを表示し、アプリケーションの呼び出しツリー内でそのループを見つけて、他のループとどのように関連しているかを確認し、[Source (ソース)] タブでそのソースコードを調べることもできます。
アプリケーション内の他のコード領域のパフォーマンスを継続的に調査して、ターゲット上で推定されるパフォーマンスをより深く理解します。
次のステップ
- [Code Regions (コード領域)] ペインで、[loop in VectorAdd(…)<…> at vector-add-buffers.cpp:83] に Parallel (並列) があることを確認します: 明示的な依存関係タイプがありますが、並列化されている他の 3 つのループ/関数があります。想定される依存関係タイプが報告されました ([Measured (測定)] カラムグループ)。つまり、インテル® Advisor はこれらのコード領域の依存関係に関する情報を持っていませんが、依存関係がなく、ループ/関数を並列化できると推測しています。
ほとんどの場合、ループに依存関係があると、ループをターゲット GPU にオフロードすることは推奨されません。インテル® Advisor の依存関係解析を使用して、ループ伝達依存関係を解析できます。推奨されるワークフローについては、ユーザーガイドの想定される依存関係がモデル化に影響するか確認を参照してください。
- インテル® Advisor は、実際のループ伝達依存関係を検出すると、それらをシーケンシャル・カーネルとしてモデル化します。通常、このようなカーネルを GPU 上で実行してもメリットはありません。コードをターゲットにオフロードするには、依存関係を解決する必要があります。
- 異なるデータ転送シミュレーション・モードで特性解析を実行すると、アプリケーション内のデータ転送に関するより詳細なレポートを取得できます。メモリー・オブジェクトがどのように転送されるかを理解するには medium (中)、データの再利用によってアプリケーションのパフォーマンスが向上するかどうかを確認するには full (完全) を選択します。
vector-add-buffers サンプル・アプリケーションで報告されたデータに基づいて、それをターゲット GPU で実行してパフォーマンスを最適化したり、他の解析を実行してターゲット GPU でのアプリケーションの動作について詳しく調べたりすることができます。その後、GPU Roofline Insights perspective (GPU ルーフラインの調査パースペクティブ) を使用して、ターゲット GPU 上のアプリケーションの実際のパフォーマンスをプロファイルし、ハードウェア・リソースがどのように使用されているか確認できます。