精度レベル
Low (低)
有効となる解析
サーベイ + FLOP (特性化)
結果の解釈
ドットが最上部のルーフから離れるほど、改善の余地は大きくなります。アムダールの法則に従って、プログラムの合計実行時間の大半を占めるループを最適化することで、実行時間が短いループを最適化するよりも大幅な効果が期待できます。
注
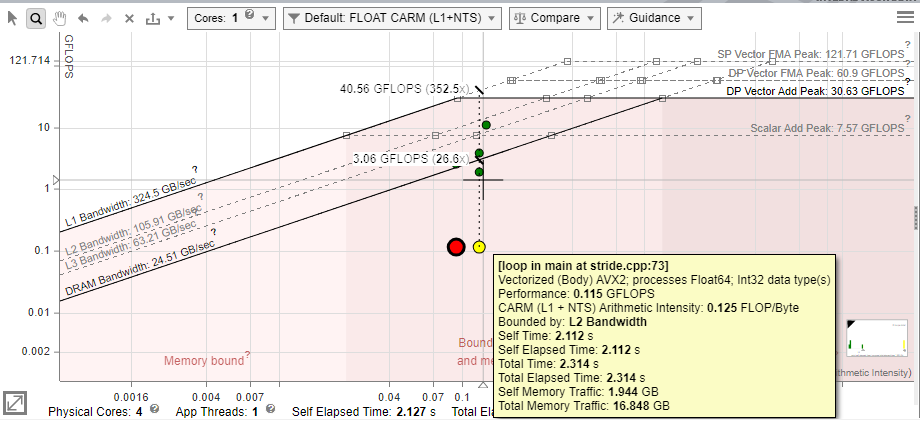
このトピックでは、インテル® Advisor GUI の CPU ルーフライン・レポートに示されるデータについて説明します。結果を HTML 形式で表示することもできますが、データの配置とペインが異なることがあります。- ドットの大きさと色で、プログラムの合計時間の大部分を占めるループや、グラフの低い位置にあるループを特定します。次に例を示します。
- 小さな緑のドットは消費時間が少ないため、最適化する必要はないと考えられます。
- 大きな赤いドットは最も時間がかかります。そのため、優先すべき最適化の候補は、それらと最上部のルーフ間にある赤いドットです。
注
右にある [ルーフビュー] メニューで、実行時間に対応するドットの色とタイプ (スカラーやベクトル) を切り替えることができます。 - ドットの位置に応じてループの制限を特定します。インテル® Advisor では、グラフ上のルーフライン・ゾーンにマークを付けて、ループが依存するルーフをを特定できます。
- ループはメモリールーフに依存します。
- ループは計算ルーフに依存します。
- ループはメモリーと計算の両方のルーフに依存します。
- [Recommendations (推奨事項)] タブで、選択したループ/関数の次の最適化ステップのヒントを示す [ルーフラインのガイド] セクションまでスクロールします。
ドット上のルーフは、より高いパフォーマンスの達成を制限する要因を示していますが、ドットの下にあるルーフもパフォーマンスの関連性を示します。それぞれのルーフは、上位にあるルーフに関連する特定の最適化を行わなくても達成可能な最大パフォーマンスを表わしています。ドットの位置に応じて次の最適化を試します。
注
さらに正確な最適なの推奨事項については、[コード解析] タブのルーフラインのガイドおよび [推奨事項] タブのルーフラインの結果を参照してください。ドットの位置 |
理由 |
最適化 |
|---|---|---|
メモリールーフの下 (DRAM 帯域幅、L1 帯域幅など) |
ループ/関すのメモリ使用は非効率です。 |
このループのメモリー・アクセス・パターン解析を実行します。
|
ベクトル加算ピーク以下 |
ループ/関数は命令セットを十分に活用していません。 |
サーベイレポートの [特性] カラムをチェックして、FMA 命令が使用されているか確認します。
|
スカラー加算ピークのすぐ上 |
ループ/関数はベクトル化されていません。 |
サーベイでベクトル化の効率とパフォーマンス問題を確認してください。低い値が示される場合、推奨事項に従って改善します。 |
スカラー加算ピーク以下 |
ループ/関数はスカラーです。 |
ループがベクトル化されている場合、サーベイレポートを確認します。ベクトル化されていなければ、可能な限りベクトル化してください。これには、依存関係解析を実行して、ベクトル化を強制しても安全であるか確認が必要な場合もあります。 |
次の [Roofline (ルーフライン)] グラフでは、ループ A と G (大きな赤いドット)、そして B (小さな黄のドット) が最適化の最良の候補となります。ループ C、D、E (小さな緑のドット) と H (黄色のドット) は、パフォーマンス向上の余地があまりないか、パフォーマンスに大きな影響を与えるには小さすぎるため候補にはなりません。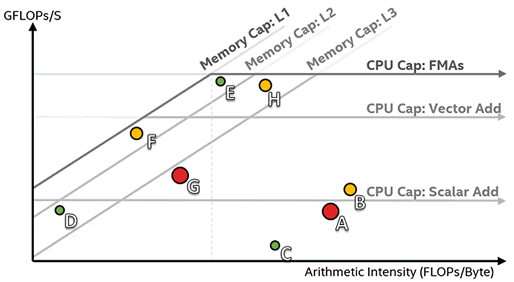
一部のアルゴリズムは特定のルーフを超えることができません。例えば、上記の例のループ A が依存関係のためにベクトル化できない場合、スカラー加算ピークを超えることはありません。
ヒント
メモリーのルーフを超えることができない場合、計算強度を高めるためアルゴリズムの改良を検討してください。これにより、メモリー帯域幅の上限に達する前に、右側に移動してパフォーマンスを向上させる余地が増えます。これは、例のループ F を最適化する適切なアプローチであり、キャッシュの使用を改善できない場合はループ G を最適化する適切なアプローチでもあります。特定のループを解析
グラフ上のドットを選択して、[Code Analytics (コード解析)] タブを開くと、選択したループに関連する詳細情報が表示されます。
- [Loop Information (ループ情報)] ペインを参照して、選択したループの合計時間、セルフ時間、使用された命令セット、および命令ミックスを調べます。インテル® Advisor は以下を提供します。
- コールスタック内の静的アセンブリー・コード解析に基づく静的命令ミックスデータ。静的命令ミックスを使用して、最内の関数/ループの命令セットを調査します。
- 動的アセンブリー・コード解析に基づいた動的な命令ミックス。このメトリックは、関数/ループで実行された命令の合計数を表わします。動的命令ミックスを使用して、最外のループおよび複雑なループの入れ子内の命令セットを調査します。
インテル® Advisor は、計算で使用されるデータタイプを自動的に決定します。命令ミックス内のカテゴリー別にグループ化された命令のクラスを表示します。
カテゴリー
命令タイプ
計算 (FLOP と INTOP) ADD、MUL、SUB、DIV、SAD、MIN、AVG、MAX、ABS、SIN、SQRT、FMA、RCCP、SCALE、FCOM、V4FMA、V4VNNI メモリー - スカラーとベクトル MOV 命令
- GATHER/SCATTER 命令
- VBMI2 圧縮/展開命令
混在 メモリーオペランド付き計算命令 その他 MOVE、CONTROL FLOW、SYNC、OTHER 注
インテル® Advisor は、使用されるデータタイプやベクトルレジスターのタイプとサイズに応じて、FMA および VNNI 命令を複数の計算としてカウントします。 - ループを制限する特定のルーフの詳細については、[Roofline (ルーフ)] ペインを参照してください。
- ループを実行するスレッド数、データタイプ、および命令ミックスを含むルーフが表示されます。
- 選択したループを制限する要因を正確に識別します (メモリー、計算、またはメモリーと計算)。
- ループを制限する正確なルーフを決定し、ルーフに対して最適化を行った場合の潜在的な高速化を推測します。
- 特性化解析で収集された操作数を表示するには、[Statistics for operations (操作の統計)] ペインを参照してください。必要な操作に応じて、ドロップダウン・リスから FLOP、INTOP、FLOP+INTOP または全ての操作を選択します。ペインの右上隅にあるトグルを使用して、セルフデータと合計データを切り替えます。
インテル® Advisor は、浮動小数点計算 (FLOP) を、次のカテゴリーの命令の合計とその反復回数の積として計算します: FMA、ADD、SUB、DIV、DP、MUL、ATAN、FPREM、TAN、SIN、COS、SQRT、SUB、RCP、RSQRT、EXP、VSCALE、MAX、MIN、ABS、IMUL、IDIV、FIDIVR、CMP、VREDUCE、VRND
整数操作 (INTOP) は 2 つのモードで計算されます。
- 厳密には計算ではないループカウント操作 (INC/DEC、シフト、ローテート操作など) を含む潜在的な INT 操作 (デフォルト)。INTOP は、次の命令の合計とその反復回数の積として計算されます: ADD、ADC、SUB、MUL、IMUL、DIV、IDIV、INC/DEC、shift、rotate
- 計算操作のみを含む厳密な INT 操作 (Python* API でのみ利用可能)。INTOP は、次の命令の合計とその反復回数の積として計算されます: ADD、MUL、IDIV、SUB