インテル® Advisor は、ハイパフォーマンス Fortran、C、C++、SYCL*、OpenMP*、および OpenCL* コードの設計と最適化支援し、最新のコンピューター・アーキテクチャーから潜在的なパフォーマンスを最大限に引き出します。アプリケーションのパフォーマンスを測定し、必要なデータを収集して、目的に応じたさまざまなパースペクティブ (観点) からコードを確認することで、視点を掘り下げ最適化のヒントを得ることができます。
ルーフライン・グラフでパフォーマンスのボトルネックを視覚化
C、C++、SYCL* または Fortran アプリケーションを最適化する場合、CPU または GPU で実行されるターゲット・プラットフォームのメモリー帯域幅や計算能力など、ハードウェアによって課される制限に関連するアプリケーションの現在のパフォーマンスと潜在的なパフォーマンスを理解するのに役立ちます。
インテル® Advisor のルーフライン・モデルは、ハードウェアによって課せられるパフォーマンスの上限に対して実際のパフォーマンスを可視化し、潜在的な最適化ステップの理想的なロードマップを示す主な制限の要因 (メモリー帯域幅や計算能力) を決定するのに役立ちます。この解析では、改善の余地が最も大きいループに注目します。これにより、最大限にパフォーマンスの利点をもたらす領域に集中できます。
ルーフライン・レポートを生成するため、インテル® Advisor は以下を行います。
- ループ/関数 (CPU) または OpenCL* カーネル (GPU) のタイミングとメモリーデータを収集します。
- ハードウェアの制限を測定し、浮動小数点と整数操作のデータを収集します。
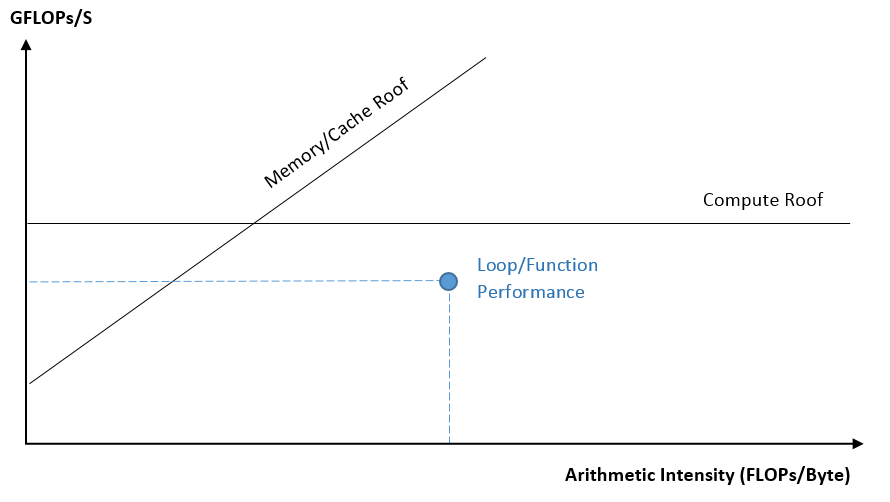
ルーフライン・グラフは、マシンが達成可能な最大パフォーマンスと、アプリケーションの達成可能なパフォーマンスと演算強度を表示します。
- 演算強度 (x 軸) - CPU/VPU/GPU とメモリー間で転送された、ループ/関数アルゴリズムに基づく 1 バイトあたりの浮動小数点操作 (FLOP) の数、または 1 バイトあたりの整数操作 (INTOP) の数です。
- パフォーマンス (y 軸) - 1 秒あたりのギガ単位の浮動小数点操作の数 (GFLOPS)、または 1 秒あたりのギガ単位の整数操作の数 (GINTOPS) です。
収集されたデータを基に、インテル® Advisor はルーフライン・グラフを表示します。
- それぞれのループ/関数/カーネルの実行時間は、ドットのサイズと色で区別できます。GPU ルーフラインのグラフのドットは OpenCL* カーネルに対応し、CPU ルーフラインのドットはループ/関数に対応します。
- メモリー帯域幅の限界は対角線として表示されます。
- 計算能力の限界は水平線として表示されます。
ルーフラインを取得して解釈する方法の詳細は、CPU / メモリー・ルーフラインの調査パースペクティブ または GPU ルーフラインの調査パースペクティブ を参照してください。
アクセラレーターへのオフロードをモデル化
アクセラレーターへオフロードするようにアプリケーションを設計するには、最初に以下を行う必要があります。
オリジナルの C++ または Fortran コードのループ/関数をオフロードする利点とオーバーヘッドを見積もり、コードのどの領域をオフロードするか決定します。
異なるアクセラレーターにオフロードする場合、SYCL*、OpenCL*、または OpenMP* アプリケーションのパフォーマンスが向上することを確認します。
インテル® Advisor のオフロードのモデル化パースペクティブから、ターゲット・プラットフォーム (GPU など) にオフロードする利点が大きいコード領域と、オフロードが有益ではないコード領域を特定できます。また、ターゲット・プラットフォームで実行したコードのパフォーマンスを推測することで、アクセラレーターの構成パラメーターを調整する可能性を示します。
オフロードのモデル化は、測定されたベースライン・メトリックとアプリケーション特性を入力として受け取り、解析モデルを適用することでターゲット・プラットフォーム上の実行時間と特性を推測します。
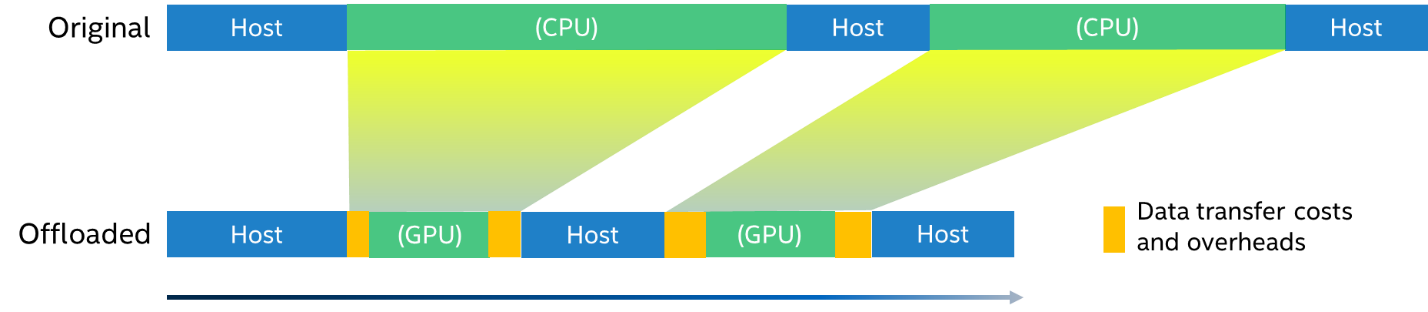
オフロードのモデル化は次の 3 つのモデルをベースにしています。
- 計算スループットモデルは、ベースライン・プラットフォーム上の領域での算術操作をカウントし、計算エンジンにのみ依存すると想定して、同じ算術操作の組み合わせを実現するのに必要なターゲット・プラットフォームでの実行時間を推測します。
- メモリー・サブシステムのスループット・モデルは、ベースライン・プラットフォーム上の領域内のメモリーアクセスをトレースし、同量のメモリーを転送するのに必要なターゲット・プラットフォームの実行時間を予測します。メモリー・トラフィックは、ターゲット・プラットフォームのメモリー構成を反映するキャッシュ・シミュレーターを使用して測定されます。
- オフロードデータ転送解析は、領域から読み書きされるメモリーアクセスを測定し、その領域がターゲット・プラットフォームにオフロードされる場合は PCIe* を介して送信する必要があります。
オフロードのモデル化パースペクティブを実行して結果を解釈する詳細は、オフロードのモデル化パースペクティブ を参照してください。
ベクトル化の効率をチェック
現代のインテル® プロセッサーは、インテル® ストリーミング SIMD エクステンション (インテル® SSE)、インテル© アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2)、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) により、SIMD (単一命令複数データ) 並列処理をサポートする拡張機能を備えています。ベクトル幅が拡張された SIMD 命令を利用して、より高いパフォーマンスを実現するには、アプリケーションをベクトル化する必要があります。
インテル® Fortran コンパイラー・クラシック、インテル® oneAPI DPC++/C++ コンパイラー、GNU コンパイラー・コレクション (GCC*) など多くのコンパイラーは自動ベクトル化機能をサポートしますが、プログラミング言語のシリアル制限によりベクトル化が制限されることがあります。リダクションをサポートするためベクトル化機能を拡張し、明示的なベクトル化プログラミング手法が必要になりました。
- 外部ループ
- ユーザー定義関数を含むループ
- コンパイラーがデータの依存関係を想定するループ
ベクトル処理ユニットを搭載する現代のプロセッサーで CPU 依存のアプリケーションのパフォーマンスを向上するには、明示的なベクトル・プログラミングによりスレッドレベルの並列処理と SIMD レベルの並列処理の構造を変更します。
インテル® Advisor のベクトル化とコードの調査パースペクティブを使用してアプリケーション実行時の動作を解析し、ベクトル化により最も恩恵が得られるアプリケーションの領域を特定します。ベクトル化とコードの調査パースペクティブは、ベクトル化により最高のパフォーマンスを達成するため、以下を特定するのに役立ちます。
- ベクトル化またはスレッドによる並列化が最も有効な場所を特定します
- ループのベクトル化による利点と、ベクトル化できない場合はその理由
- ベクトル化されないループとその理由
- 一般的なパフォーマンスの問題
パースペクティブを実行してレポートを解釈する詳細は、ベクトル化とコードの調査パースペクティブ を参照してください。
スレッド化のプロトタイプ設計
コアが大部分の時間を有益なワークの実行に費やしてビジーである場合、プログラムに並列実行 (並列処理) を加えることでパフォーマンス向上を期待できます。これを達成するには、解析と知識そしてテストが必要です。
シリアルプログラムが並列実行を許容するように設計されていない場合、プログラムの一部を並列実行するように変換すると、並列実行時にのみ予期しないエラーに遭遇することがあります。CPU 時間を消費しないプログラム領域に労力を費やすよりも、ホットスポットおよびメインのエントリーポイントとそれぞれのホットスポット間の機能に注目する必要があります。
十分な準備をせず不用意にプログラムに並列処理を加えると、並列タスクの相互作用から生じる予期しないクラッシュ、プログラムのハングアップ、または誤った結果に遭遇することになります。例えば、誤った並列タスクの相互作用を回避するには同期を追加する必要がありますが、ロックのオーバーヘッドとシリアル同期は並列実行の利点を損ねる可能性があるため、注意深く実装する必要があります。
インテル® Advisor のスレッド化パースペクティブは、複数の選択肢からスレッド化のプロトタイプをすばやく作成し、大規模なシステムにプロジェクトをスケールして、より迅速に最適化し、実装の信頼性を高めるのに役立ちます。
- 並列処理を実装する前に、問題を特定して解決
- C/C++ および Fortran コードにスレッド処理を追加
- 開発や実装作業を中断することなく、大規模コア数のシステムにおけるスレッドの設計とプロジェクトのスケーリングに関するパフォーマンスへの影響をプロトタイプ化します。
- 設計中のデータ共有の問題を検出して解決します (解決にコストが生じなければ)。
それぞれのプログラミング言語で使用可能な高レベルの並列フレームワークは、次のとおりです。
言語 |
利用可能な高レベルの並列フレームワーク |
|---|---|
C |
OpenMP* |
C++ |
インテル® oneAPI スレッディング・ビルディング・ブロック (oneTBB) OpenMP* |
Fortran |
OpenMP* |
注
インテル® Advisor 2021.1 以降では C# と .NET のサポートが非推奨となりました。パースペクティブを実行してレポートを解釈する詳細は、スレッド化パースペクティブ を参照してください。
アムダールの法則を使用してプログラムを測定
並列プログラミングに適用される 2 つの最適化規則があります。
最も多くの時間を費やすプログラムのコード領域に注目します。
仮定ではなく実測します。
アムダールの法則
並列プログラミングに関して、ジーン・アムダール氏は、「プログラムの一部分の並列化から得られるスピードアップは、シリアル実行されるプログラム領域によって制限される」という、アムダールの法則を定義しました。
その結果は驚愕に値するかもしれません。80% の実行時間を費やすプログラム領域を並列化しても、どれほど多くのコアで実行しても 5 倍以上のスピードアップは得られません。
そのため、プログラムの並列化から最大限の利点を得るには、アムダールの法則で示されるように、プログラムのすべての場所を並列化する必要があるでしょう。しかし、多くの時間を費やす場所を特定して、そこから最大限の利点を得られるように注力することが、より現実的です。
仮定ではなく実測する
これはもう 1 つの最適化規則である、「仮定ではなく実測します」につながります。プログラマーの直感によりプログラムが時間を費やす場所を見つけることは、信頼性がなく不正確です。インテル® Advisor に含まれる サーベイツール は、プログラムの実行をプロファイルして、時間を消費する場所を特定できます。
並列コード領域の可能性をマークするため、プログラムにインテル® Advisor のアノテーションを追加し、スータビリティー・ツールを実行してプログラムとアノテーション・サイトの最大パフォーマンス・ゲインを予測します。このパフォーマンス・ゲインの予測値は、アムダールの法則の影響を反映した並列実行モデルに基づいています。このパフォーマンス・ゲインの予測値は、アムダールの法則の影響を反映した並列実行モデルに基づいています。