CPU / メモリーのルーフライン調査パースペクティブは、ハードウェアによって制限されるパフォーマンスの上限に対して、制限の主な要因 (メモリー帯域幅や計算能力) を検証し実際のパフォーマンスを可視化するのを可能にします。
CPU / メモリーのルーフライン調査パースペクティブを実行するには、インテル® Advisor GUI と CLI からの 2 つの方法があります。両方の方法で収集された結果は、インテル® Advisor GUI で開くことができます。
インテル® Advisor GUI から CPU / メモリー・ルーフラインの調査パースペクティブを実行
[Analysis Workflow (解析のワークフロー)] ペインで、ドロップダウン・メニューから [CPU / Memory Roofline Insights (ベクトル化とコードの調査)] パースペクティブを選択し、データ収集の精度レベルを [Low (低)] に設定して、 ボタンをクリックします。この精度レベルでは、インテル® Advisor は次のことを行います。
ボタンをクリックします。この精度レベルでは、インテル® Advisor は次のことを行います。
- Survey analysis (サーベイ解析)を実行して、マシンのハードウェアの制限を測定し、ループ/関数のタイミングを収集します。
- Characterization analysis (特性化解析)を実行して、浮動小数点と整数操作のデータおよびメモリーデータを収集します。
データ収集精度のプリセットの詳細については、インテル® Advisor ユーザーガイドの CPU ルーフライン精度のプリセットを参照してください。完了すると、インテル® Advisor は [Roofline (ルーフライン)] グラフを表示します。
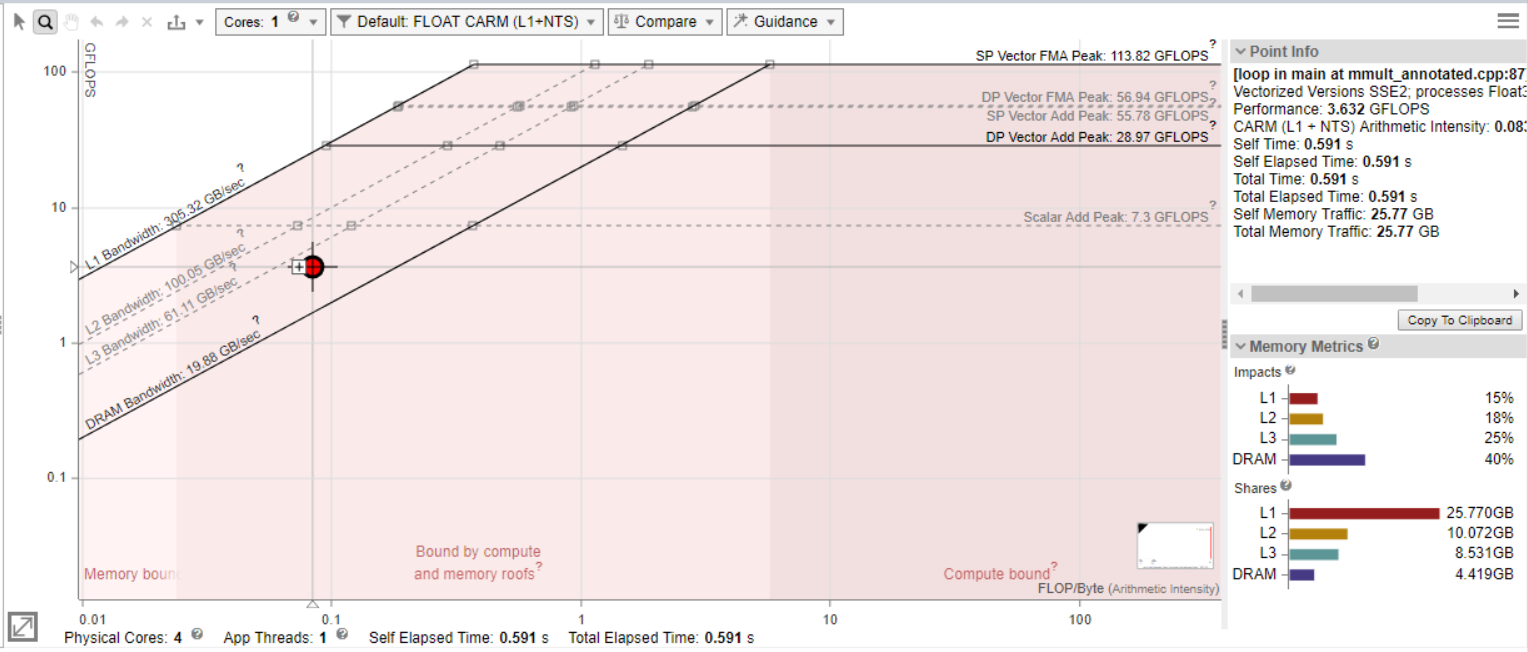
[Roofline (ルーフライン)] グラフは、マシンの達成可能な最大パフォーマンスに対して、アプリケーションのパフォーマンスと演算強度を表示します。
- 演算強度 (x 軸) - CPU/VPU とメモリー間で転送された、ループ/関数アルゴリズムに基づく 1 バイトあたりの浮動小数点操作 (FLOP) の数、または 1 バイトあたりの整数操作 (INTOP) の数です。
- パフォーマンス (y 軸) - 1 秒あたりのギガ単位の浮動小数点操作の数 (GFLOPS)、または 1 秒あたりのギガ単位の整数操作の数 (GINTOPS) です。
一般に次のことが言えます。
- 異なる色とサイズのドットは関数/ループを表します。ドットのサイズと色は、アプリケーションの合計実行時間に占めるこのループ/関数の実行時間を表します。大きな赤いドットは実行時間が最も長いため、最適化する効果があります。小さな緑のドットは実行時間が短いため、最適化の労力が無駄になるかもしれません。
- ルーフライン・グラフの斜めのラインはメモリー帯域幅の上限を示しており、最適化なしではこれ以上のパフォーマンスを達成することはできません。例えば、[L1 Bandwidth] ルーフラインは、ループが常に L1 キャッシュにヒットする場合に演算強度で実行できる最大ワーク量を示します。データセットによって L1 キャッシュが頻繁にミスする場合、ループは L1 キャッシュ速度のメリットを受けられません。この場合、アクセスする低速 L2 キャッシュの制限の影響を受けます。そのため、L1 キャッシュを頻繁にミスし、L2 キャッシュにはヒットするループを示すドットは、[L2 Bandwidth] ルーフライン下に表示されます。
- ルーフライン・グラフの水平ライン (ルーフライン) は、計算能力の上限を示しており、最適化なしではループ/関数のパフォーマンスをこれ以上向上することはできません。例えば、[Scalar Add Peak] は、この状況下でスカラーループが実行可能な加算命令の最大数を示します。[Vector Add Peak] は、この状況下でベクトルループが実行可能な加算命令の最大数を示します。そのため、ベクトル化されていないループのドットは、[Scalar Add Peak] ルーフラインの下に表示されます。
- 最上部のルーフラインはマシンの最大能力を示すため、ドットはこれを超えることはできません。そして、すべてのループがマシンの最大能力を利用できるわけではありません。
ドットと最上部の達成可能なルーフラインの間の距離が大きいほど、関数/ループの最適化の可能性が高くなります。
コマンドライン から CPU / メモリー・ルーフラインの調査パースペクティブを実行インターフェイス
Advisor のコマンドライン・インターフェイスを使用して CPU / メモリー・ルーフラインの調査パースペクティブを実行するには、次のコマンドを使用します。
advisor --collect=roofline --project-dir=./advi --search-dir src:p=./advi –- myApplication
このコマンドは、2 つの解析を 1 つずつ実行するバッチモードです。
- ループ/関数の実行時間データを収集するサーベイ解析。
- AVX-512 プラットフォームの浮動小数点操作と整数操作、メモリー・トラフィック、マスク使用率メトリックを収集し、アプリケーションの演算強度とパフォーマンス、およびハードウェアの計算能力を測定する特性解析。
インタラクティブなルーフライン・グラフで、ハードウェアによって課せられたパフォーマンス上限に対するアプリケーションが達成しているパフォーマンスを表示するには、収集された結果をインテル® Advisor GUI で開くか、次のコマンドでインタラクティブな HTML ルーフライン・レポートを生成します。
advisor --report=roofline --report-output=./advi/advisor-roofline.html --project-dir=./advi
ここで、report-output オプションは、インテル® Advisor が生成したレポートを保存するディレクトリーと HTML ファイルを指定します。
CLI レポートの生成の詳細については、インテル® Advisor ユーザーガイドの該当するセクションを参照するか、ターミナルで次のコマンドを実行してください。
advisor --help report
インテル® Advisor は、次のコマンドで読み取り専用の結果スナップショットを作成できます。
advisor --snapshot --project-dir=./advi --pack --cache-sources --cache-binaries -- /tmp/my_proj_snapshot
次にすることは?
いくつかのループがベクトル化されず、パフォーマンス目標に到達していない場合は、以下を考慮してください。
- ルーフライン・グラフに示されている最も時間のかかる関数/ループに対して作業することを検討してください。
- [Code Analytics (コード分析)] タブで、選択した関数/ループの主な情報を調べます。関数/ループが計算依存かメモリー依存かを識別するには、[Roofline (ルーフライン)] ペインを参照してください。
- [Recommendations (推奨事項)] タブを使用して、[Roofline Guidance (ルーフライン・ガイド)] セクションで選択した関数/ループで可能な最適化手順に関するヒントを表示します。
- ループが計算依存である場合:
- [Survey (サーベイ)] レポートの [Vectorized Loops/Efficiency (ベクトル化されたループ/効率)] カラムをチェックします。
- コンパイラーが依存関係を想定し、選択した関数/ループをベクトル化しなかった理由を見つけるには、Dependencies (依存関係) 解析を実行することを検討してください。
- コストのかかるメモリー命令を識別するには、Memory Access Patterns (メモリー・アクセス・パターンMAP)) 解析を実行することを検討してください。
- ループがメモリー依存である場合:
関連情報
- インテル® Advisor クックブックに記載されている一般的なユースケースを調べてみましょう:
- インテル® Advisor ユーザー向けルーフライン・リソースを参照。