
遅延初期化#
問題
コストがかかる可能性のあるオブジェクトの作成をアクセスされるまで延期します。並列プログラミングでは、競合状態に対しても初期化を保護する必要があります。
コンテキスト
オブジェクトの初期化中に行われる操作のコストはかなり高くなる可能性があります。その場合、オブジェクトは必要なときにのみ初期化する必要があります。遅延初期化は、このようなアプローチを実現する一般的な手法です。
解決方法
oneapi::tbb::collaborative_call_once を oneapi::tbb::collaborative_once_flag を指定して使用すると、ユーザー・オブジェクトのスレッドセーフな遅延初期化を実装するのに役立ちます。
さらに、collaborative_call_once により、同じ collaborative_once_flag でブロックされている他のスレッドが、初期化関数内で呼び出された他の oneTBB 並列構造に参加できるようになります。
例
この例では、フィボナッチ数列の計算での遅延初期化の実装を示します。以下は、N = 4 のフィボナッチ再帰ツリーのグラフィカル表現です。
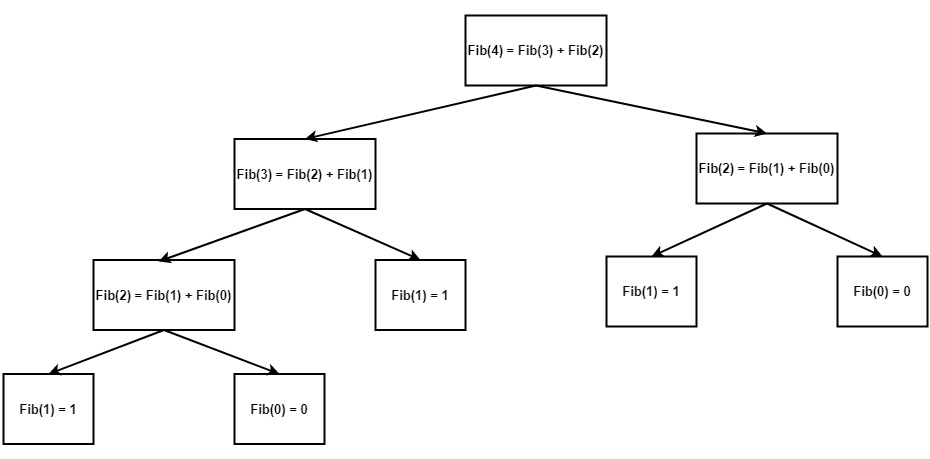
図に示されているように、一部の要素は複数回再計算されます。これらの操作は冗長であるため、遅延初期化されたフィボナッチ数がここでは関連します。
遅延初期化を使用しない実装では、再帰木全体の横断と値の再計算により、O(2^N) の時間複雑度になります。すべてのノードが 1 回ずつ横断されるため、木はリストに変換され、時間複雑度は O(N) となります。
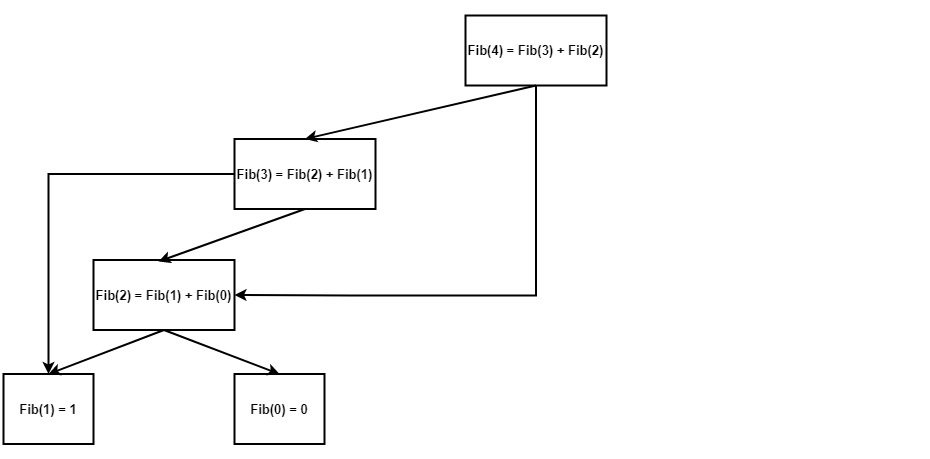
ここで実装コードを確認できます。すでに計算された値は、collaborative_once_flag とペアになったバッファーに保存され、初期化がすでに完了していると collaborative_call_once が呼び出されても再計算されません。
using FibBuffer = std::vector<std::pair<oneapi::tbb::collaborative_once_flag, std::uint64_t>>;
std::uint64_t LazyFibHelper(int n, FibBuffer& buffer) {
// ベースケース
if (n <= 1) {
return n;
}
// 値を 1 回だけ計算し、バッファに保存。
// 他のスレッドは、すでに取得されている collaborative_once_flag で
// ブロックされませんが、関数内で並列処理に参加します。
oneapi::tbb::collaborative_call_once(buffer[n].first, [&]() {
std::uint64_t a, b;
oneapi::tbb::parallel_invoke([&] { a = LazyFibHelper(n - 2, buffer); },
[&] { b = LazyFibHelper(n - 1, buffer); });
buffer[n].second = a + b;
});
return buffer[n].second;
}
std::uint64_t Fib(int n) {
FibBuffer buffer(n+1);
return LazyFibHelper(n, buffer);
}