
チャンク化の制御#
チャンク化はパーティショナーと粒度によって制御されます。チャンク化を最大限に制御するには、両方を指定します。
parallel_forの 3 番目の引数としてsimple_partitioner()を指定します。これにより自動チャンク化はオフになります。レンジを構築するときに粒度を指定します。コンストラクターのスレッド引数形式は、
blocked_range<T>(begin,end,grainsize)です。grainsize(粒度) のデフォルト値は 1 です。単位はチャンクあたりのループ反復回数です。
チャンクが小さすぎると、オーバーヘッドがパフォーマンス上の利点を上回る可能性があります。
次のコードは、明示的な粒度 G を使用するように変更された parallel_for の最後の例です。
#include "oneapi/tbb.h"
void ParallelApplyFoo( float a[], size_t n ) {
parallel_for(blocked_range<size_t>(0,n,G), ApplyFoo(a),
simple_partitioner());
}粒度は並列化の最小しきい値を設定します。この例の parallel_for は、異なるサイズの可能性があるチャンクに対して ApplyFoo::operator() を呼び出します。chunksize をチャンク内の反復回数とします。simple_partitioner を使用すると、[G/2] <= chunksize <= G が保証されます。
レンジの粒度を指定しますが、auto_partitioner と affinity_partitioner を使用する中間レベルの制御もあります。auto_partitioner はデフォルトのパーティショナーです。どちらのパーティショナーも、自動チャンク化で説明されている自動粒度ヒューリスティックを実装しています。後述の帯域幅とキャッシュのアフィニティー セクションで説明するように、affinity_partitioner には追加のヒントが暗黙的に含まれています。これらのパーティショナーはチャンクに G 回以上の反復を発生させる可能性がありますが、[G/2] 回未満の反復を持つチャンクを生成することはありません。明示的な粒度でレンジを指定すると、ヒューリスティックが失敗した場合にこれらのパーティショナーが無駄に小さなチャンクを生成するのを防ぐのに役立つことがあります。
粒度は並列ループに影響を与えるため、auto_partitioner と affinity_partitioner を使用して粒度を自動的に選択する場合でも、次の資料を読む価値があります。
|
|
|---|---|
ケース A |
ケース B |


上の図は、オーバーヘッドを表す茶色の境界線内の灰色の領域として有効なワークを表示して粒度の影響を示しています。ケース A とケース B の両方で、グレー領域の合計は同じです。ケース A は、粒度が小さすぎるとオーバーヘッドの割合が比較的高くなることを示しています。ケース B は、粒度を大きく指定したことにより、潜在的な並列性を犠牲にして、オーバーヘッドの割合が軽減する様子を示しています。有効なワークの割合としてのオーバーヘッドは、粒 (グレイン) の数ではなく、粒度に依存します。粒度を設定する際には、反復回数の合計やプロセッサー数ではなく、この関係を考慮してください。
経験則として、operator() の grainsize 反復の実行には少なくとも 100,000 クロックサイクル要すべきです。例えば、1 回の反復に 100 クロックかかる場合、grainsize は少なくとも 1000 反復である必要があります。疑問が残る場合は、次の検証を行ってください。
grainsizeパラメーターを必要以上に高く設定します。粒度はループ反復単位で指定します。反復にどのくらいのクロックサイクルがかかるか分からない場合は、grainsize=100,000 から始めてください。その理由は、各反復では通常、反復ごとに少なくとも 1 つのクロックが必要であるためです。ほとんどの場合、手順 3 ではるかに小さい値が得られます。アルゴリズムを実行します。
grainsizeパラメーターを繰り返し半分にし、値が減少するにつれてアルゴリズムの処理速度がどれだけ遅くなるか、または速くなるかを確認してください。
粒度を高く設定しすぎることの短所は、並列性が低下する可能性があることです。例えば、grainsize の値が 1000 でループに 2000 回の反復がある場合、parallel_for は、プロセッサーが 2 つ以上ある場合でも、ループを 2 つのプロセッサーにしか分配しません。ただし、確信がない場合には、低すぎる値よりも少し高い値を設定してください。値が低すぎるとシリアル・パフォーマンスが損なわれ、プログラムの上位で他の並列処理が利用可能な場合は、並列パフォーマンスにも影響します。
ヒント
粒度をあまり正確に設定する必要はありません。
次の図は、100万のインデックスに対する浮動小数点 a[i]=b[i]*c の計算に基づく、実行時間と粒度の典型的なバスタブ曲線を示しています。反復ごとのワークはわずかです。時間計測は、8 つのハードウェア・スレッドを備えた 4 ソケットのマシンで行いました。
ウォールクロック時間と粒度 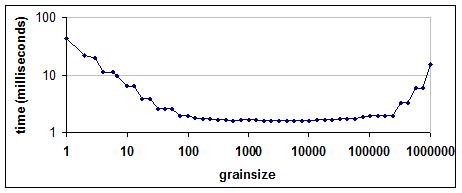
スケールは対数です。左側の下向きの傾斜は、粒度が 1 の場合、オーバーヘッドの大部分は並列スケジュールのオーバーヘッドであり、有効なワークではないことを示しています。粒度が大きくなると、比例して並列オーバーヘッドが減少します。その後、曲線は平坦化します。これは、粒径が十分に大きくなると、並列オーバーヘッドが無視できるほど小さくなるためです。右端では、チャンクが大きすぎて利用可能なハードウェア・スレッドよりもチャンクの数が少なくなるため、曲線は上昇しています。100 から 100,000 の広いレンジの粒度でうまく動作していることに注目してください。
ヒント
ネストしたループを並列化する一般的な経験則は、いちばん外側のループを可能な限り並列化することです。その理由は、外側のループの各反復では、内側のループの反復よりも大きな粒度のワークが行われる可能性が高いためです。
製品および性能に関する情報
性能は、使用状況、構成、およびその他の要因によって異なります。詳細については、www.intel.com/PerformanceIndex (英語) をご覧ください。