スレッド化パースペクティブを使用すると、並列化に向けた最適な候補を特定し、スレッド化を設定するプロトタイプを作成して、特定の関数/ループの並列処理を妨げるデータ依存関係を確認できます。
ここでは、nqueens アプリケーションをプロファイルし、スレッドによる並列化に最適な候補を選択する方法を説明します。自身のアプリケーションを使用して、以下の手順に従うこともできます。
次の操作を行います。
必要条件
- インテル® Advisor は、スタンドアロン製品 (英語) またはインテル® oneAPI ベース・ツールキットの一部 (英語) としてインストールできます。インストール手順については、ユーザーガイドのインテル® Advisor のインストールを参照してください。
- インテル® C++ コンパイラー・クラシックを、スタンドアロン製品 (英語) またはインテル® HPC ツールキットの一部 (英語) としてインストールします。インストール手順については、インテル® oneAPI ツールキットのインストール・ガイド (英語) を参照してください。
- インテル® Advisor およびインテル® C++ コンパイラー・クラシックの環境変数を設定します。例えば、インストール・ディレクトリーで setvars スクリプトを実行します。
このドキュメントでは、ツールがデフォルトの場所にインストールされていることを前提としています。ツールを別の場所にインストールした場合は、以下のコマンドのデフォルトパスを必ず置き換えてください。
重要
環境変数を設定した後、ターミナルまたはコマンドプロンプトを閉じないでください。閉じると環境がリセットされます。
アプリケーションを展開してビルドします
Linux*
環境変数を設定したターミナルから:
- /opt/intel/oneapi/advisor/latest/samples/en/C++ ディレクトリーに移動します。
- nqueens_Advisor.tgz ファイルをシステム上の書き込み可能なディレクトリーまたは共有ディレクトリーにコピーします。
- .tgz ファイルからサンプルを展開します。
- 展開した場所にある nqueens_Advisor/ ディレクトリーに移動します。
- サンプル・アプリケーションをビルドします。
make 1_nqueens_serial - アプリケーションを実行してビルドを確認します。
./1_nqueens_serialアプリケーションの出力には、ボードサイズ 14 とターゲットの実行にかかった合計時間が表示されます。
Windows* (コマンドライン)
- 使用する Visual Studio* と OS バージョン用の Visual Studio Tools を見つけて、コマンドプロンプトのショートカットのいずれかを選択します。例えば、Microsoft Windows* 10 の [スタート] ペインから、[Visual Studio 2019] > [x64 Native Tools Command Prompt for VS2019] を選択します。
- C:\Program Files (x86)\Intel\oneAPI\advisor\latest\samples\en\C++ ディレクトリーに移動します。
- nqueens_Advisor.zip ファイルをシステム上の書き込み可能なディレクトリーまたは共有ディレクトリーにコピーします。
- サンプルを .zip ファイルから展開します。
- 展開した場所にある nqueens_Advisor/ ディレクトリーに移動します。
- リリースモードでターゲットをビルドします。
devenv nqueens_Advisor.sln /build release /project 1_nqueens_serial - Release ディレクトリーに移動します。
- アプリケーションを実行してビルドを確認します。
1_nqueens_serial.exeアプリケーションの出力には、ボードサイズ 14 とターゲットの実行にかかった合計時間が表示されます。
Windows* の場合 (Microsoft Visual Studio* から)
- C:\Program Files (x86)\Intel\oneAPI\advisor\latest\samples\en\C++ ディレクトリーに移動します。
- nqueens_Advisor.zip ファイルをシステム上の書き込み可能なディレクトリーまたは共有ディレクトリーにコピーします。
- サンプルを .zip ファイルから展開します。
- Microsoft Visual Studio* IDE を起動します。
- [ファイル] > [開く] > [プロジェクト/ソリューション] を選択します。
- [プロジェクトを開く] ダイアログボックスで、展開された場所にある nqueens_Advisor/ ディレクトリーに移動し、nqueens_Advisor.sln ファイルを開きます。
注
アプリケーションの再ターゲットを提案するダイアログウィンドウが表示されたら、[OK] をクリックします。 - Visual Studio* のツールバーで [ソリューション構成] ドロップダウンが [Debug] に設定されている場合は、[Release] に変更します。
- ソリューション エクスプローラーで [1_nqueens_serial] プロジェクトを右クリックし、[スタートアップ プロジェクトの構成...] を選択します。
- インテル® C++ コンパイラー・クラシックを使用する場合は、[1_nqueens_serial] プロジェクトを右クリックし、[Intel Compiler] > [Use Intel C++ Compiler Classic] をクリックします。
- [1_nqueens_serial] プロジェクトを右クリックし、[プロパティ] を選択して、サンプル コードがリリースビルド構成を使用していることを確認します。
推奨されるビルド設定の詳細については、ターゲット・アプリケーションのビルドを参照してください。
- [OK] ボタンをクリックして、[プロパティ] ダイアログボックスを閉じます。
- [ビルド] > [ソリューションのクリーン] を選択します。
- [ビルド] > [1_nqueens_serial のビルド] を選択してターゲットをビルドします。
アプリケーションの出力には、ボードサイズ 14 とターゲットの実行にかかった合計時間が表示されます。
- プロジェクトが古くなっていると Visual Studio* IDE が応答した場合は、[いいえ] をクリックしてビルドしません。
ベースラインのパフォーマンス・データを収集します
グラフィカル・ユーザー・インターフェイス (GUI) からスレッド化パースペクティブを実行
- 環境変数を設定したターミナルまたはコマンドプロンプトから、インテル® Advisor GUI を起動します。
advisor-gui - 先ほどビルドした vec_samples アプリケーションのプロジェクトを作成します。詳細は、始める前にを参照してください。
[Project Properties (プロジェクトのプロパティー)] ダイアログボックスで、Trip Counts and FLOP Analysis (トリップカウントと FLOP 解析)、Dependencies Analysis (依存関係解析)、およびMemory Access Patterns Analysis (メモリー・アクセス・パターン解析) の各タイプで [Inherit settings from Survey Hotspots Analysis Type (調査ホットスポット分析タイプから設定を継承する)] チェックボックスが選択されていることを確認します。
注
Microsoft Visual Studio* IDE で作業する場合は、インテル® Advisor GUI を初めて開いたときにインテル® Advisor によってプロジェクトが自動的に作成されるため、新たに作成する必要はありません。 - [Perspective Selector (パースペクティブ・セレクター)] ペインで [Threading (スレッド化)] パースペクティブを選択します。
- [Analysis Workflow (解析ワークフロー)] ペインで、データ収集の精度レベルを [Low (低)] に設定し、
 ボタンをクリックしてパースペクティブを実行します。
ボタンをクリックしてパースペクティブを実行します。この精度レベルでは、インテル® Advisor は Survey (サーベイ) 解析を実行してアプリケーションをプロファイルします。
Linux* のコマンドライン・インターフェイス (CLI) からスレッドを実行する
Survey (サーベイ) 解析を実行してパフォーマンス・メトリックを収集し、合計時間が最も長いループ/関数を特定します。
advisor --collect=survey --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial注
スレッド化パースペクティブでは、--search-dir オプションを使用してソース検索ディレクトリーを指定する必要があります。解析が完了すると、ベクトル化とコード調査の結果を含む 1_nqueens_serial プロジェクトが自動的に作成されます。結果は、インテル® Advisor GUI で表示できます。
Windows* 上の CLI からスレッドを実行する
Survey (サーベイ) 解析を実行してパフォーマンス・メトリックを収集し、合計時間が最も長いループ/関数を特定します。
advisor --collect=survey --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial.exe注
スレッド化パースペクティブでは、--search-dir オプションを使用してソース検索ディレクトリーを指定する必要があります。解析が完了すると、ベクトル化とコード調査の結果を含む 1_nqueens_serial プロジェクトが自動的に作成されます。結果は、インテル® Advisor GUI で表示できます。
結果を調べて並列化の可能性を見つけます
GUI を使用してデータの収集が完了するとインテル® Advisor は結果を自動的に開きます。
CLI を使用してデータを収集したら、次のコマンドを使用して GUI で結果を開きます。
advisor-gui ./1_nqueens_serial結果が自動的に開かない場合は、[Show Result (結果を表示)] をクリックします。
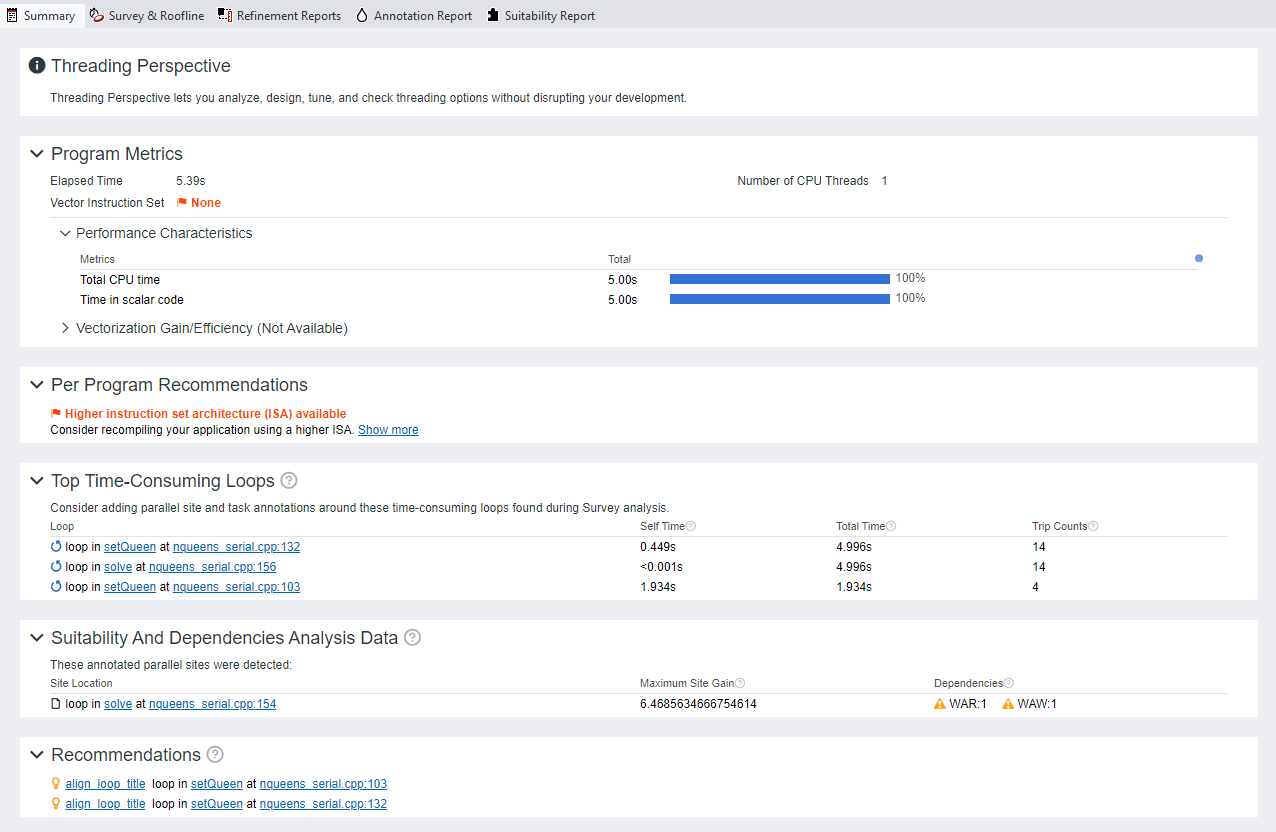
GUI でベクトル化とコードの調査の結果を開くと、インテル® Advisor は最初に [Summary (サマリー)] タブを表示します。このウィンドウは、アプリケーションの実行、パフォーマンスのヒント、アプリケーションのベクトル化の問題に関する主要な情報を含むダッシュボードです。
[Survey & Roofline (サーベイとルーフライン)] に切り替えて、各ループ/関数のパフォーマンス・メトリックを調べ、並列化の候補を見つけます。
![並列化の可能性を見つけるには、スレッド化レポートの [Survey & Roofline (サーベイとルーフライン)] タブを参照してください。](GUID-C70F6ECD-AE87-4C51-9045-C30C21B0B6D3-low.png)
Survey & Roofline (サーベイとルーフライン) レポートの下部ペインで、ナビゲーション・ツールバーの [Top Down (トップダウン)] をクリックして、階層内の関数/ループを調査します。
- [Total Time (合計時間)] カラムには、関数またはループに費やされた時間と、そこから呼び出されたすべての関数が表示されます。[Total Time (合計時間) %] が大きい項目と、合計時間がより短い複数の呼び出し先は、並列処理の候補となる可能性があります。
- [Self Time (セルフ時間)] カラムには、各関数またはループが呼び出されるたびに費やされた時間が表示されます。突出したセルフ時間値を持つループまたは関数は、ワークを分散する候補となります。
- アプリケーションは setQueen() 関数に最も多くの時間を費やし、自身を再帰的に呼び出します。この関数は並列化の候補となります。
最良の並行化の候補をアノテーションでマークします
アノテーションは、プログラムのシリアル領域で、インテル® Advisor がプログラムの並列実行と同期が行われると想定される場所をマークするサブルーチン呼び出しまたはマクロです。アノテーションによってプログラムの計算は変更されないため、正常に実行されます。
- エディターでアプリケーションのソースコード nqueens_serial.cpp を開きます。
- ADVISOR SUITABILITY EDIT を検索し、サンプルコードの指示に従います。コードにアノテーションを挿入するには、合計 4 箇所の編集を行います。
- #include <advisor-annotate.h> のコメントを解除します。このファイルは、アノテーションを定義するインクルード・ファイルです。
- ANNOTATE_SITE_BEGIN(solve); のコメントを解除します。このアノテーションは、ループ内に単一のタスクを含む並列サイトの開始を示します。
- ANNOTATE_ITERATION_TASK(setQueen); のコメントを解除します。このアノテーションは、ループ内の反復的な並列タスクをマークします。
- ANNOTATE_SITE_END(); のコメントを解除します。このアノテーションは、並列サイトの終了を示します。
- 編集内容を保存し、エディターを閉じます。
- ターゲットを再ビルドします。
注
インクルード・ファイルが見つからず、識別子が未定義であるためビルドが失敗した場合:- [プロジェクト] > [1_nqueens_setial プロパティ] に移動します。
- [C/C++] > [Additional Include Directories]で、インテル® Advisor の year バージョンを、マシンにインストールされているバージョンに変更します。例: ADVISOR_2022_DIR。
スレッド並列処理をモデル化
追加の解析でスレッド化パースペクティブを再実行します。次のいずれかを行います。
GUI からスレッド化を実行
- [Analysis Workflow (解析ワークフロー)] ペインで、[Medium (中)] 精度レベルを選択して、パースペクティブを自動的に構成します。
- ボタンをクリックしてパースペクティブを実行します。
この精度レベルでは、インテル® Advisor はサーベイ、トリップカウントによる特性化、適合性、依存関係の解析を実行します。
重要
Your configuration might be incomplete (構成が不完全である可能性があります) というメッセージが表示された場合は、[Continue (続行)] をクリックします。この警告メッセージは、ソースコードにアノテーションが追加されていることを確認することを促しています。これは、アノテーションなしでは適合性と依存関係の解析を実行できないためです。
Linux* 上の CLI からスレッド化を実行する
- Survey (サーベイ) 解析を実行してパフォーマンスを解析します。
advisor --collect=survey --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial - トリップカウント・データを収集します。
advisor --collect=tripcounts --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial - 適合性解析を使用して、アノテーション付き関数/ループのスレッド設計をモデル化します。
advisor --collect=suitability --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial - 依存関係解析を使用して、アノテーション付き関数/ループの並列化を妨げる可能性のあるデータ共有の問題を特定します。
advisor --collect=dependencies --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial
Windows* 上の CLI からスレッド化を実行する
- Survey (サーベイ) 解析を実行してパフォーマンスを解析します。
advisor --collect=survey --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial.exe - トリップカウント・データを収集します。
advisor --collect=tripcounts --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial.exe - 適合性解析を使用して、アノテーション付き関数/ループのスレッド設計をモデル化します。
advisor --collect=suitability --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial.exe - 依存関係解析を使用して、アノテーション付き関数/ループの並列化を妨げる可能性のあるデータ共有の問題を特定します。
advisor --collect=dependencies --project-dir=./1_nqueens_serial --search-dir src:r=./1_nqueens_serial -- 1_nqueens_serial.exe
結果を調査します
GUI を使用してデータの収集が完了するとインテル® Advisor は結果を自動的に開きます。
CLI を使用してデータを収集したら、次のコマンドを使用して GUI で結果を開きます。
advisor-gui ./1_nqueens_serial結果が自動的に開かない場合は、[Show Result (結果を表示)] をクリックします。
スレッド化レポートが開いたら、並列処理でモデル化されたアプリケーションのパフォーマンスを調べます。
- [Suitability (適合性)] レポートタブに移動して、並列化によってパフォーマンスがどのように向上するかを調べます。
- nqueens_serial.cpp:154 のアノテーション付きループの場合、インテル® Advisor はデフォルトの構成パラメーターでパフォーマンスが約 1.80 倍向上すると予測しています。
- 最大サイトゲインのスケーラビリティー図が示すように、CPU 数が 2 から 16 の場合、パフォーマンスのスピードアップが向上します。CPU 数が 16 を超える場合、対応する標的ドットが同じ線上にあるため、パフォーマンスの高速化は同一です。図の点のほとんどは緑色のゾーンにありますが、CPU 数が 16 から増加するほど、黄色のゾーンに近づきます。つまり、最大 16 個の CPU でループを並列化すれば、予測されるスピードアップは努力する価値があるということです。ループを並列化して 16 個を超える CPU で実行すると、より多くの時間や労力を要する可能性がありますが、スピードアップは同様に向上します。しかし、パフォーマンスの問題が発生する可能性があります。
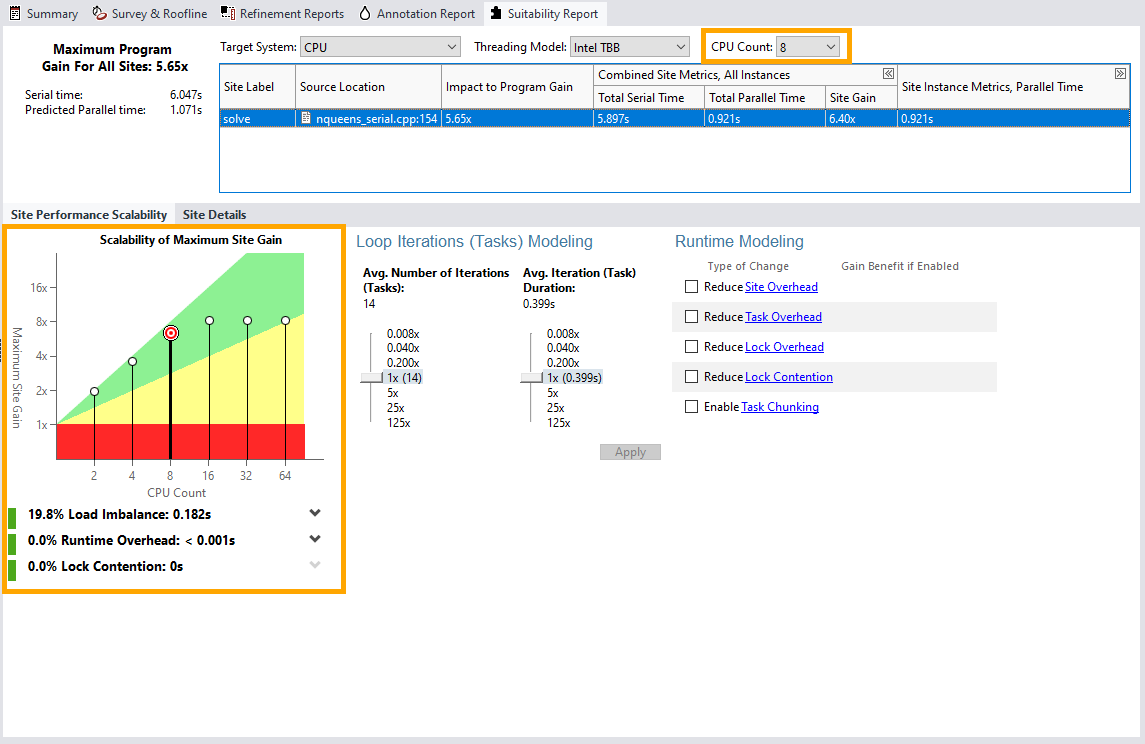
- 図の下の 3 つのパーセンテージ・メトリックを調べます。デフォルトの CPU 数が 8 の場合、メトリックはすべて緑色であり、パフォーマンスの問題がないことを意味します。最適なパフォーマンスを実現するには、最大 8 個の CPU でループを並列化することを推奨します。
- この場合、予測パフォーマンスの詳細を表示するには、[CPU Count (CPU 数)] を 16 に変更します。対応するドットが、左側のドットよりも黄色のゾーンに近い位置に配置されていることに注意してください。Load Imbalance (負荷不均衡) メトリックは黄色で、約 44% です負荷の不均衡が大きいと、予測される最大スピードアップは、アプリケーションの再構成に必要な労力を正当化するのに十分ではありません。最適化の方法を理解するため調査することを検討してください。
- CPU 数、スレッド化モデル、その他のパラメーターを試して、パフォーマンスにどのような影響があるかを確認します。
- アノテーション付きループに並列処理を妨げる依存関係があるか確認するには、[Refinement (リファインメント)] レポートタブに移動します。
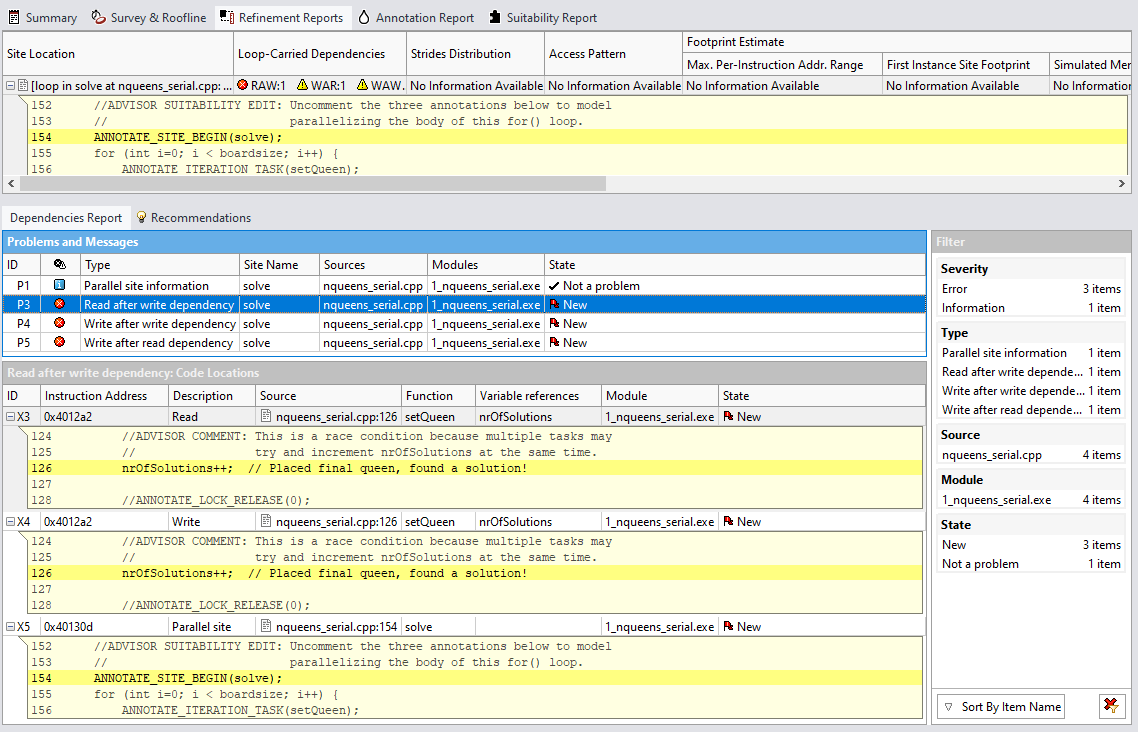
- [Refinement Report (リファインメント・レポート)] の上部ペインで、nqueens_serial.cpp:154 の solve ループ内の RAW (書き込み後の読み取り)、WAR (読み取り後の書き込み)、および WAW (書き込み後の書き込み) の依存関係に注目してください。
- 上部のペインから、nqueens_serial.cpp:154 の solve のループを選択します。
- [Problems and Messages (問題とメッセージ)] ペインで、ループ内で見つかった依存関係の問題を詳しく調べます。詳細情報を表示するには、問題の 1 つを選択します。例えば、Read after write (書き込み後の読み取り) 依存関係を選択します。
- [Code Locations (コードの場所)] ペインで、書き込み後の読み取り依存関係のソースを調べます: 手順では、[Variable Reference (変数参照)] カラム表示するように、nrOfSolutions 変数を参照します。つまり、複数のタスクが同時に同じ変数をインクリメントする可能性があるため、競合状態が発生します。
アプリケーションにスレッドを適用する前に依存関係を修正する必要があります。
次のステップ
- アノテーション付きループで見つかった依存関係を修正します。サンプル・アプリケーションのソースコードから、ADVISOR CORRECTNESS EDIT を検索し、サンプルコードの指示に従って問題を修正します (合計 6 箇所の編集を行います)。
- アプリケーションを再ビルドし、Medium (中) 精度でスレッド化パースペクティブを再実行します (サーベイ、トリップカウント、適合性、依存関係の解析を実行)。
- 依存関係が見つからず、修正によって予測される最大スピードアップに悪影響が及ばなかったことを確認します。予測されるスピードアップが高く、負荷の不均衡が緑色で、CPU 数が 8 までの推定パフォーマンスに影響を与えていないことに注目してください。
- 予測される最大スピードアップの利点が、ターゲットを並列化する労力に見合うならば、そのアノテーションを並列実行をサポートする並列フレームワークに置き換えます。
このサンプル・アプリケーションには、アノテーションが並列フレームワーク・コードに置き換えられたバージョンがすでに含まれています。次のファイルを調べます。
並列フレームワーク
ファイル
インテル® Cilk™ Plus
3_nqueens_cilk.cpp
OpenMP*
3_nqueens_omp.cpp
インテル® スレッディング・ビルディング・ブロック (インテル® TBB)
3_nqueens_tbb.cpp
- サンプルの並列バージョンをビルドします。
- 生成された並列アプリケーションの正確性をテストし、他のインテル® Advisor パースペクティブ、インテル® Inspector、およびインテル® VTune™ プロファイラーを使用して実際の並列パフォーマンスを検証します。