インテル® VTune™ Amplifier によって収集されたデータを、注目する領域でフィルター処理したり、データを特定のプログラムユニット (モジュール、関数、フレーム領域など) でグループ化して解析を行います。
フィルター処理
インテル® VTune™ Amplifier は、特定のオブジェクトや時間領域に注目するのに役立つ強力なフィルター処理を提供します。これは、注目する領域を絞り込んで小さなデータセットを処理することで、 GUI のレスポンスを向上させます。
オブジェクトによるフィルター処理
特定のプログラムユニットでフィルター処理を行うには、次のいずれかのオプションを使用します。
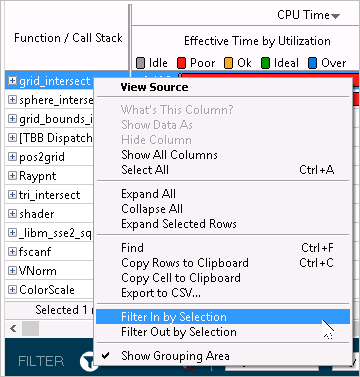
コンテキスト・メニュー・オプション: グリッドの注目するオブジェクトを選択して、右クリックし [Filter In by Selection (選択でフィルターイン)] コンテキスト・メニュー・オプションを選択することで、選択したオブジェクト以外をビューに表示しないようにします。逆に、[Filter Out by Selection (選択でフィルターアウト)] は選択したデータを表示しません。特定のメトリックの表示データのパーセント比率を示すため、ウィンドウ下部にあるフィルターバーが更新されます。例えば、最も時間を消費する関数 grid_intersect によってグリッドをフィルターインしたい場合次のようになります。
フィルター OFF:
フィルター ON:
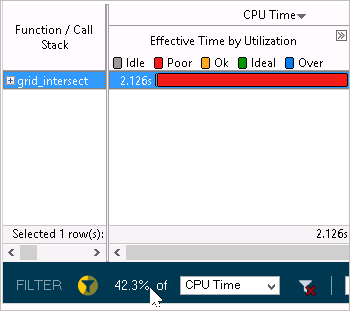
フィルター適用後のフィルターバーには、収集された CPU 時間データの 42.3% のみであることが示されています。
フィルター・ツールバー・オプション: フィルタリング・ドロップダウン・メニューからプログラムユニット (プロセス、モジュール、スレッド) を選択して、グリッドと特定のプログラムユニットのデータを表示するタイムライン・ビューをフィルターアウトします。例えば、クロックティック・イベント・カウントの 53.4% を示す analyze_locks プロセスを選択すると、結果データはこのモジュールのみの特性を表示し、フィルターバーにはクロックティック・データの 53.4% のみが表示されていることが通知されます。

時間領域によるフィルター処理
タイムライン上の特定の領域に解析を絞り込むことができます。例えば、GPU ホットスポット・ビューポイントのタイムライン・ペインで注目する領域を選択して右クリックし、[Zoom In by Selection (選択を拡大)] もしくは [Zoom In and Filter In by Selection (選択を拡大してフィルターイン)] コンテキスト・メニューを選びます。
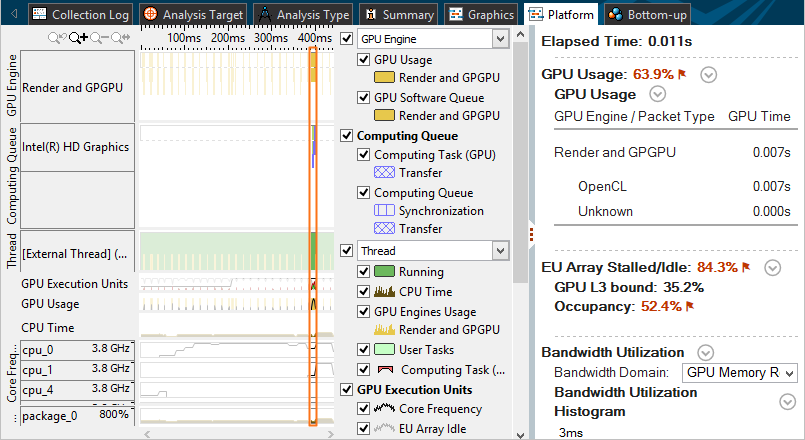
右にあるコンテキスト・サマリーは、選択された時間範囲データに対応して更新され、フィルターバーには表示されているデータ (このビューポイントのデフォルトのメトリックごと) のパーセント比率が示されます。
グループ化
グループ化メニューを使用して、注目するデータシーケンスを表示するためビューを編成することができます。利用可能なグループは解析タイプとビューポイントによって異なります。
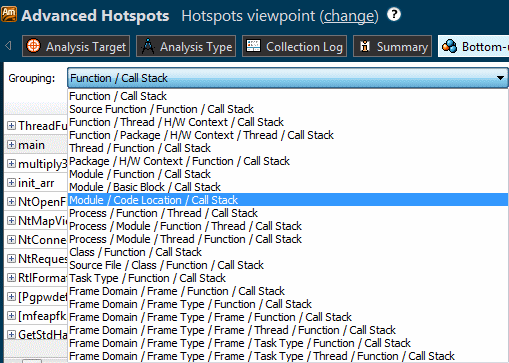
例えば、作成したモジュールに対応する収集データを表示したい場合、[Module/Function/Call Stack (モジュール/関数/コールスタック)] の粒度を選択して、モジュール内のホットスポットを特定した後、[Function/Thread/H/W Context/Call Stack (関数/スレッド/ハードウェア・コンテキスト/コールスタック)] の粒度に切り替えてホットな関数がどの CPU で動作しているか確認します。
インテル® VTune™ Amplifier は、意味的に次のように分類できる一連の事前設定されたグループ化の粒度を提供します。
グループ |
説明 |
例 |
|---|---|---|
基本 |
関数のホットスポットを特定し、コールスタックの問題を判別します。 ほとんどのビューポイントでは、関数レベルがデフォルトです。アプリケーション・モジュールにデバッグ情報がある場合は、ホットスポット関数が正しく表示されます。デバッグ情報が不完全であるか存在しない場合、<unknown> 関数として表示されるか、モジュールの内部関数で収集されたサンプルが隣接する外部関数の結果と認識される可能性があります。 |
[Function/Call Stack (関数/コールスタック)] [Source Function/Function/Call Stack (ソース関数/関数/コールスタック)] からインライン展開されたおよび JIT コンパイルされた関数のすべてのインスタンスを解析します |
マルチスレッド解析 |
関数、OS (スレッド) またはハードウェア (パッケージ、コア、スレッド) の観点からマルチスレッド化されたアプリケーションのホットスポットを解析します。 |
[Function/Thread/HW Context/Call Stack (関数/スレッド/ハードウェア・コンテキスト/コールスタック)] から異なるスレッド上で実行される関数を特定します [Function/Package/HW Context/Thread/Call Stack (関数/パッケージ/ハードウェア・コンテキスト/コールスタック)] からマルチプロセッサー・システム上のインターコネクトや NUMA の問題を特定します [Core/HW Context/Function/Call Stack (コア/ハードウェア・コンテキスト/関数/コールスタック)] からハイパースレッド固有の問題を特定します [Core/Thread/Function/Call Stack (コア/スレッド/関数/コールスタック)] と [Thread/Core/Function (スレッド/コア/関数)] からコア間を移動するスレッドによって引き起こされる問題を特定します |
フレーム解析 |
低速または高速なフレームを特定します。 |
[Frame Domain/Frame Duration Type/Function/Call Stack (フレームドメイン/フレーム期間タイプ/関数/コールスタック)] [Frame Domain/Frame Duration Type/Frame/Function/Call Stack (フレームドメイン/フレーム期間タイプ/フレーム/関数/コールスタック)] |
OpenMP* 解析 |
OpenMP* 領域から呼び出されるホットスポットを特定します。 |
[OpenMP Region/OpenMP Barrier-to-Barrier Segment/Function/Call Stack (OpenMP* 領域/OpenMP* バリアツーバリア・セグメント/関数/コールスタック)] から異なるセグメント間のロード・インバランスを特定します [OpenMP Region/OpenMP Region Duration Type/Function/Call Stack (OpenMP* 領域/OpenMP* 領域存続期間タイプ/関数/コールスタック)] から高速/低速な OpenMP* 領域のインスタンスを解析します |
GPU 解析 |
GPU がアイドルまたはコードを実行中の CPU アクティビティーを解析します。 |
[Render and GPGPU Packet Stage/Function/Call Stack (レンダーと GPGPU パケットステージ/関数/コールスタック)] [Render and GPGPU Packet Stage/Thread/Function/Call Stack (レンダーと GPGPU パケットステージ/スレッド/関数/コールスタック)] |
一般に、[Summary (サマリー)] ウィンドウから解析を開始し、注目するオブジェクトをクリックして、解析に最も適した方法で事前にグループ化されたグリッドを開きます。例えば、上位のタスクリストでタスクをクリックすると、タスクのタイプでグループ化されたグリッドが開きます。
[Summary] ウィンドウ: |
[Bottom-up (ボトムアップ)] ウィンドウ: |
|---|---|
|
|
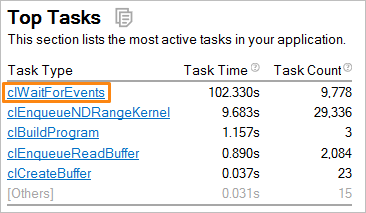
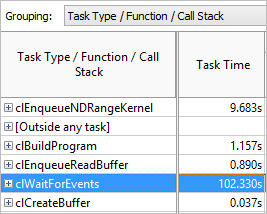
事前設定されたグループ化レベルが解析の目的にそぐわない場合、 [Customize Grouping (グループ化のカスタマイズ)] ボタンをクリックして、[Custom Grouping] ダイアログボックスで独自のグループ化レベルを作成できます。
[Customize Grouping (グループ化のカスタマイズ)] ボタンをクリックして、[Custom Grouping] ダイアログボックスで独自のグループ化レベルを作成できます。