最も時間のかかる GPU カーネルを解析し、GPU ハードウェア・メトリックをベースに GPU の使用状況を特徴付け、メモリー・レイテンシーや非効率なカーネル・アルゴリズムによって引き起こされるパフォーマンスの問題を特定して、命令タイプごとの GPU 命令周波数を解析します。
注
これは、プレビュー機能です。プレビュー機能は、正式リリースに含まれるかどうかは未定です。有用性に関する皆さんからのフィードバックが、将来の採用決定の判断に役立ちます。プレビュー機能で収集されたデータは、将来のリリースで下位互換性が保証されません。
GPU 計算/メディア・ホットスポット解析を使用して以下を行います。
GPU 利用率の高い GPU カーネルを調査し、この利用率の有効性を予測してストールまたは低占有率の原因を特定します。
選択した GPU メトリックで時間経過ごとにアプリケーションのパフォーマンスを調査します。
最も効率の悪い DPC++ または OpenCL* カーネルを解析して、非効率なカーネルコードのアルゴリズムや不適切なワーク項目の構成を特定します。
GPU 計算/メディア・ホットスポット解析は、GPU オフロード解析を行った後の次のステップとして実行すると良いでしょう。
パフォーマンスが重要なカーネルを解析し、最適化します。
パフォーマンスが重要なカーネルは、プログラムの別のカーネルと密接に関連し、それらのパフォーマンスを低下させる可能性があります。
仕組み: インテル® グラフィックスのレンダーエンジンとハードウェア・メトリック
GPU とは、小さなコアの配列 (実行ユニット (EU)) でグラフィックスや計算処理を行う高度な並列マシンです。各 EU は、複数の軽量なスレッドを同時に実行します。スレッドの 1 つが実行されると、ほかのスレッドがメモリーなどからのデータを待機するためストールしていても、そのストールを隠蔽することができます。
GPU の性能を最大限に利用するため、アプリケーションはできるだけ多くのスレッドをスケジュールして、アイドルサイクルを最小限に抑えようとします。グラフィックスと汎用計算 GPU アプリケーションでは、ストールを最小限にすることも非常に重要です。
インテル® VTune™ プロファイラーは、インテル® グラフィックスのハードウェア・イベントを監視し、サンプリング期間の GPU リソースの使用状況に関するメトリックを表示します。例えば、EU がアイドル状態、ストール状態、アクティブ状態であったサイクルの比率や、メモリーアクセスとほかの機能ユニットに関する統計情報などが分かります。インテル® VTune™ プロファイラーで GPU カーネルの実行をトレースすると、GPU メトリックで各カーネルをアノテート (注釈) できます。
以下のスキームは、インテル® グラフィックス Gen9 (英語) のさまざまな処理においてインテル® VTune™ プロファイラーによって収集されるメトリックを示します。
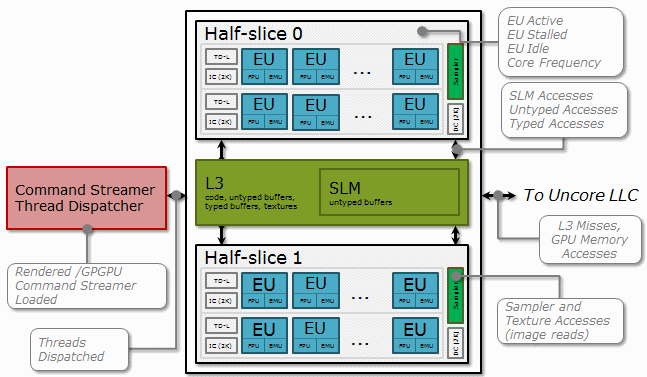
GPU メトリックは、GPU ハードウェアがどの程度効率的に利用されているか、そしてパフォーマンス向上のため改善の余地があるか特定するのに役立ちます。メトリックの多くは、サンプリング中のすべてのサイクルに対して GPU 機能ユニットが特定の状態であったサイクルの比率で表されます。
解析の設定
システムを設定し、GPU 解析に必要な権限が有効であることを確認してください。
DPC++ アプリケーション: -gline-tables-only と -fdebug-info-for-profiling オプションを指定して DPC++ コードをコンパイルします。
プロジェクトを作成して、 解析システムおよびターゲットを指定します。
解析を実行
ツールバーの
 (スタンドアロン GUI)/
(スタンドアロン GUI)/ (Visual Studio* IDE) [解析の設定] ボタンをクリックして、[解析の設定] ウィンドウを開きます。
(Visual Studio* IDE) [解析の設定] ボタンをクリックして、[解析の設定] ウィンドウを開きます。[どのように] ペインのタイトルバーをクリックします。[解析] ツリーを開き、[アクセラレーター] グループから [GPU 計算/メディア・ホットスポット (プレビュー)] 解析を選択します。この解析は、GPU 使用データを収集し、GPU タスクのスケジュールを解析して、アプリケーションが CPU 依存であるか GPU 依存であるかを識別するように事前設定されています。
注
システムに複数のインテル製 GPU が接続されている場合、選択した GPU または接続されているすべての GPU で解析を実行します。詳細については、複数の GPU の解析を参照してください。
解析モードの選択と設定:
- オプションで、GPU オフロード解析でパフォーマンスが重要 (ストールまたは時間がかかる) と特定したカーネルに解析を集中し、プロファイルの対象となる計算タスクとして指定します。必要であれば、それぞれのカーネルのサンプリング間隔 (カーネル数単位) である [注目する計算タスク] の [インスタンス・ステップ] を変更します。このオプションは、プロファイルのオーバーヘッドを軽減するのに有効です。
- (オプション) 電力解析でデータを収集するには、[電力使用を解析] オプションをオンにします。この機能は、Linux* 環境でアプリケーションをプロファイルし、ディスクリートのインテル® Iris® X e MAX グラフィックス GPU を使用する場合に利用できます。
[開始] をクリックして解析を実行します。
コマンドラインから実行
コマンドラインから GPU 計算/メディア・ホットスポット解析を実行するには、次のコマンドを入力します。
vtune -collect gpu-hotspots [-knob <knob_name=knob_option>] -- <target> [target_options]
注
下部の [コマンドライン] ボタンを使用して、この設定のコマンドラインを生成できます。
複数 GPU の解析
システムに複数のインテル製 GPU が接続されている場合、インテル® VTune™ プロファイラーは接続されているすべてのアダプターを [ターゲット GPU] プルダウンメニューで識別します。次のガイドラインに従ってください。
- [ターゲット GPU] プルダウンメニューを使用して、プロファイルを行うデバイスを指定します。
- インテル® VTune™ プロファイラーがシステムで複数のインテル製 GPU を検出した場合にのみ、[ターゲット GPU] プルダウンメニューが表示されます。メニューには利用可能な GPU アダプターの [バス/デバイス/関数 (BDF)] が示されます。この情報は、Windows* (タスク・マネージャーを参照) または Linux* (lspci を実行) でも確認できます。
- ユーザーが GPU を選択していない場合、インテル® VTune™ プロファイラーはデフォルトで最も新しいデバイスファミリーを選択します。
- [すべてのデバイス] を選択すると、システムに接続されているすべての GPU で解析が実行されます。
- 特性化モードの完全な計算セットは、 複数アダプターおよび複数タイル解析では利用できません。
解析が完了すると、インテル® VTune™ プロファイラーは [サマリー] ウィンドウにタイル情報を含む GPU ごとのサマリー結果を表示します。
解析結果
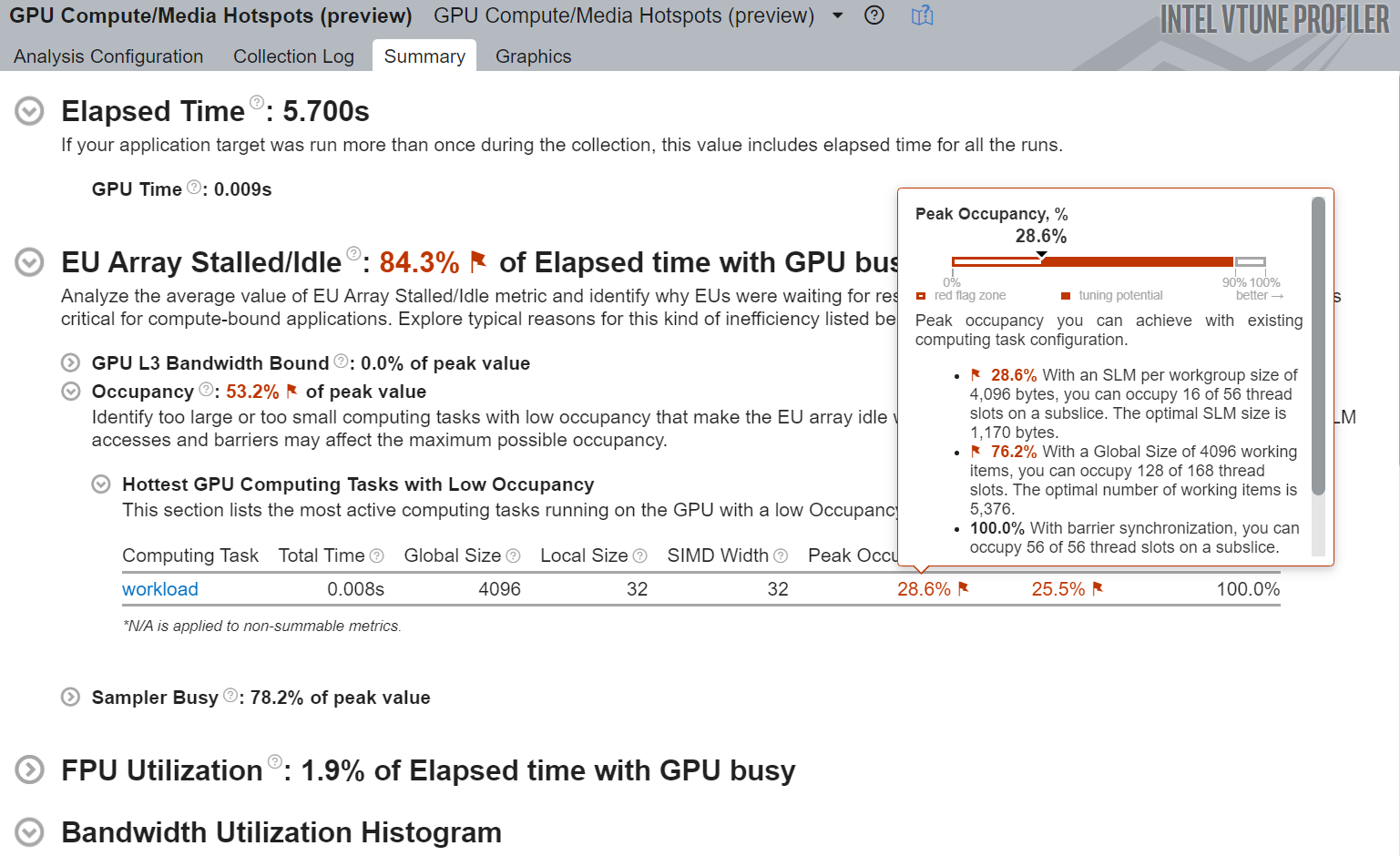
GPU 計算/メディア・ホットスポット解析がデータ収集を完了すると、[サマリー] ウィンドウにメトリックが表示されます。
- GPU 時間
- 占有率
- 既存の計算タスク構成で期待できるピーク占有率
- GPU で実行された最もアクティブな計算タスク
特性化解析の設定
特性化設定オプションを使用して、次のことを行います。
- レンダーと GPGPU エンジン利用量をモニターします (インテル® グラフィックスのみ)
- エンジンのどの部分がロードされているか特定します
- GPU と CPU データを関連付け
[特性化] ラジオボタンを選択すると、設定セクションが展開され、追加オプションが表示されます。
概要メトリックには、メモリーリード/ライト帯域幅などの GPU メモリーアクセス、GPU L3 ミス、サンプラービジー、サンプラー・ボトルネック、および GPU メモリーのテクスチャー・リード/ライト帯域幅を含むメトリックが含まれます。これらのメトリックは、グラフィックスと計算集約型の両方のアプリケーションに役立ちます。
基本計算 (グローバル/ローカル・メモリー・アクセスを含む) メトリックグループは、GPU 上の異なるタイプのデータアクセスを区別するメトリック (型なしメモリーリード/ライト帯域幅、型ありメモリーリード/ライト・トランザクション、SLM リード/ライト帯域幅、ロードされたレンダー/GPGPU コマンド・ストリーマー、および GPU EU アレイ使用) を含みます。これらのメトリックは、GPU 上の計算集約型のワークロードに役立ちます。
計算拡張メトリックグループは、インテル® プロセッサー開発コード名 Broadwell 以降の GPU 解析のみをターゲットとする追加メトリックを含みます。その他のシステムでは、この事前定義は利用できません。
完全な計算メトリックグループは、概要と基本計算イベントセットの組み合わせです。
動的命令カウントメトリックグループは、 特定の命令クラスの実行頻度をカウントします。このメトリックグループを使用すると、各カーネルの SIMD 利用率に関する情報も得られます。
[特性化] ドロップダウン・メニューには、プラットフォーム固有の事前定義された GPU メトリックが用意されています。動的命令数を除くすべての事前定義メトリックは、実行ユニット (EU) のアクティビティーに関する次のデータを収集します: EU アレイアクティブ、EU アレイストール、EU アレイアイドル、計算スレッドの開始、コア周波数、およびそれぞれの追加メトリック。
注
GPU 計算/メディア・ホットスポット解析は、Windows*、Linux* および Android* ターゲットの特性化モードで実行できます。このモードで解析を実行するには、root/管理者権限が必要です。特性化解析では、追加のデータを収集することもできます。
トレース GPU プログラミング API オプションを使用すると、インテル® プロセッサー・グラフィックスで実行されている DPC++、OpenCL*、またはインテル® メディア SDK プログラムを解析できます。このオプションは、CPU 側でアプリケーションのパフォーマンスに影響する可能性があります。
DPC++ または OpenCL* アプリケーションでは、最もホットなカーネルを特定し、パフォーマンスの問題が検出された GPU アーキテクチャー・ブロックを特定できます。
インテル® メディア SDK プログラムでは、タイムラインでインテル® メディア SDK タスクの実行を調査し、このデータをそれぞれの時間軸で GPU の利用状況と関連付けることができます。
サポートの制限
OpenCL* カーネル解析は、インテル® グラフィックス上で動作する Windows* と Linux* ターゲットで利用できます。
インテル® メディア SDK プログラム解析は、インテル® グラフィックス上で動作する Windows* と Linux* ターゲットで利用できます。
[アプリケーションを起動] または [プロセスにアタッチ] ターゲットタイプのみがサポートされます。
注
[プロセスにアタッチ] モードでは、計算キューがすでに作成されているプロセスにアタッチすると、インテル® VTune™ プロファイラーはこのキューの OpenCL* カーネルのデータを表示しません。
メモリー帯域幅の計算に必要なデータを収集するには、[メモリー帯域幅の解析] オプションを使用します。このタイプの解析には、インテル・サンプリング・ドライバーがインストールされている必要があります。
GPU ハードウェア・メトリック収集の GPU サンプルの間隔を指定する、[GPU サンプリング間隔 (ミリ秒)] オプションを使用します。デフォルトで、インテル® VTune™ プロファイラーは 1ミリ秒のインターバルを使用します。
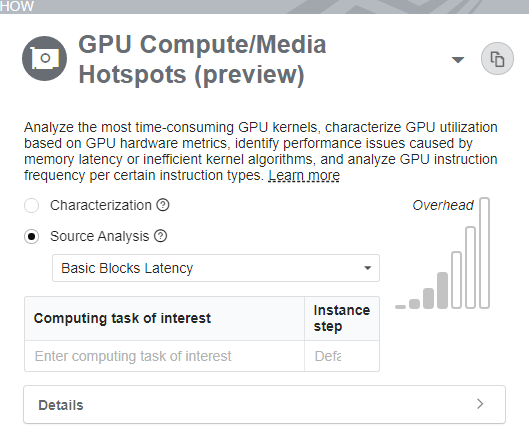
ソース解析の設定
ソース解析では、インテル® VTune™ プロファイラーは、GPU カーネルのメモリーアクセスによって引き起こされる、パフォーマンスが重要な基本ブロックを特定するのを支援します。
[ソース解析] ラジオボタンを選択すると、[設定] ペインにドロップダウン・メニューが表示され、解析する問題のタイプを指定するプロファイル・モードを選択できます。
- [基本ブロックレイテンシー] オプションは、非効率なアルゴリズムによって引き起こされる問題を特定するのに役立ちます。このモードでは、インテル® VTune™ プロファイラーはすべての基本ブロックの実行時間を測定します。基本ブロックは、シーケンスの先頭に 1 つの開始点があり、シーケンスの最後に 1 つの終了点がある直線的なコードシーケンスです。後処理中に、インテル® VTune™ プロファイラーは基本ブロックの各命令の実行時間を計算します。そのため、このモードはどの操作が高価であるか理解するのに役立ちます。
- [メモリー・レイテンシー] オプションは、メモリーアクセスによって生じるレイテンシーの問題を特定するのに役立ちます。このモードでは、インテル® VTune™ プロファイラーはメモリーリード/同期命令がカーネルの実行時間に与える影響を予測するため、これらの命令をプロファイルします。特性化モードで、GPU 計算/メディア・ホットスポット解析を実行して、GPU カーネルがスループットやメモリー依存であることを特定して、同じ基本ブロックのどのメモリーリード/同期命令に時間がかかっているか調査する場合、このオプションの適用を検討してください。
[基本ブロック・レイテンシー] または [メモリー・レイテンシー] プロファイル・モードでは、GPU 計算/メディア・ホットスポット解析は次のメトリックを使用します。
予測 GPU サイクル: GPU がプロファイルされた命令を実行するのに要した平均サイクル数。
平均レイテンシー: サイクルごとのメモリーリードおよび同期命令の平均レイテンシー。
インスタンスごとに実行された GPU 命令: カーネル・インスタンスごとの平均 GPU 命令実行数。
スレッドごとに実行された GPU 命令: カーネル・インスタンスごとに 1 つのスレッドで実行された平均 GPU 命令数。
[命令数] プロファイル・モードを有効にすると、インテル® VTune™ プロファイラーはカーネルにより実行された命令の内訳を次のグループで表示します。
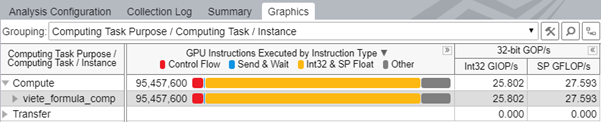
[制御フロー] グループ |
ip レジスターを明示的に変更する if、else、endif、while、break、cont、call、calla、ret、goto、jmpi、brd、brc、join、halt および mov、add 命令 |
[送信 & 待機] グループ |
send、sends、sendc、sendsc、wait |
[Int16 & HP Float] | [Int32 & SP Float] | [Int64 & DP Float] グループ |
ビット操作 (整数型のみ): and、or、xor など 算術演算: mul、sub、avg、frc、mac、mach、mad、madm ベクトル算術演算: line、dp2、dp4 など 拡張数学演算 |
[その他] グループ |
nop を含むほかのすべての操作 |
[命令数] モードでは、インテル® VTune™ プロファイラーは、次の実行された命令のウェイトを合計して計算された、[1 秒あたりの操作数] メトリックも提供します。
ビット操作 (整数型のみ):
- and、not、or、xor、asr、shr、shl、bfrev、bfe、bfi1、bfi2、ror、rol - ウェイト 1
算術演算:
add、addc、cmp、cmpn、mul、rndu、rndd、rnde、rndz、sub - ウェイト 1
avg、frc、mac、mach、mad、madm - ウェイト 2
ベクトル算術演算:
- line - ウェイト 2
- dp2、sad2 - ウェイト 3
- lrp、pln、sada2 - ウェイト 4
- dp3 - ウェイト 5
- dph - ウェイト 6
- dp4 - ウェイト 7
- dp4a - ウェイト 8
拡張数学演算:
math.inv、math.log、math.exp、math.sqrt、math.rsq、math.sin、math.cos - ウェイト 4
math.fdiv、math.pow - ウェイト 8
注
操作 (演算) のタイプはデスティネーション・オペランドのタイプにより決定されます。
データを表示
インテル® VTune™ プロファイラーは解析を実行して、[GPU 計算/メディア・ホットスポット] ビューポイントでデータを開き、次のウィンドウにさまざまなプラットフォーム・データを表示します。
[サマリー] ウィンドウは、エンジン全体とエンジンごとの GPU 利用率、EU ストールまたはアイドル時間のパーセンテージとその原因、および最もホットな GPU 計算タスクを表示します。
[グラフィックス] ウィンドウは、スレッドごとの CPU と GPU 利用率データを表示して、さまざまなタイプの GPU メモリーへのアクセスを解析するのに役立つ GPU ハードウェア・メトリックの拡張リストを示します。グリッドのカラム名にカーソルを移動するか、右クリックして [このカラムの意味は?] コンテキスト・メニューを選択すると、GPU メトリックの説明を見ることができます。
oneAPI レベルゼロ API を使用する DPC++ アプリケーションのサポート
このセクションでは、GPU 計算/メディア・ホットスポット解析のバックエンドで OpenCL* または oneAPI レベルゼロ API (英語) を実行する DPC++ アプリケーションのサポートについて説明します。インテル® VTune™ プロファイラーは、oneAPI レベルゼロ API のバージョン 0.91.10 をサポートします。
サポート対象 |
バックエンドで OpenCL* を使用する DPC++ アプリケーション |
バックエンドでレベルゼロを使用する DPC++ アプリケーション |
|---|---|---|
オペレーティング・システム |
Linux* Windows* |
Linux* Windows* |
データ収集 |
インテル® VTune™ プロファイラーは、GPU 計算タスクと GPU 計算キューを収集して表示します。 |
インテル® VTune™ プロファイラーは、GPU 計算タスクと GPU 計算キューを収集して表示します。 |
データ表示 |
インテル® VTune™ プロファイラーは、収集された GPU HW トリックを特定のカーネルにマップし、それらを図に表示しま。 |
インテル® VTune™ プロファイラーは、収集された GPU HW トリックを特定のカーネルにマップし、それらを図に表示しま。 |
ホスト側の API 呼び出しを表示 |
はい |
はい |
計算タスクのソース・アセンブラー |
はい |
はい |
GPU コードのインストルメント ([ソース解析] オプション、または [動的命令カウント] 特性化オプション) |
はい |
はい |
注
DPC++ GPU プロファイルの利用例については、クックブックのレシピ「GPU 上で実行する DPC++ アプリケーションのプロファイル」(英語) をご覧ください。
DirectX* アプリケーションのサポート
このセクションでは、CPU ホストで動作する Microsoft® DirectX* アプリケーションをトレースする GPU 解析で利用可能なサポートについて説明します。このサポートは、アプリケーションを起動モードでのみ利用できます。
| サポート対象 | DirectX* アプリケーション |
|---|---|
オペレーティング・システム |
Windows* |
API のバージョン |
DXGI、Direct3D 11、Direct3D 12、Direct3D 12 上の 11 |
ホスト側の API 呼び出しを表示 |
はい |
デバイス側の計算タスク |
いいえ |
計算タスクのソース・アセンブラー |
いいえ |