インテル® VTune™ プロファイラーの GPU 計算/メディア・ホットスポット・ビューポイントを使用して、GPU 依存のコードが GPU と CPU リソースをどのように利用しているか解析します。
GPU 計算/メディア・ホットスポット解析で選択したプロファイル・モードに応じて、GPU 上のコードのパフォーマンスをさまざまな観点から調査できます。
GPU にオフロードされたコードのパフォーマンス上の問題を明確にします。
GPU ハードウェア・イベントを使用してメモリーアクセスを解析。
最もコストがかかる操作のソースを解析して命令の実行を調査します。
メモリーアクセス解析
[GPU 計算/メディア・ホットスポット] モードでデフォルトで有効になっている [特性化] モードは、GPU に依存するアプリケーション向けのエントリーレベルの解析機能です。
[サマリー] ウィンドウの [最もホットな GPU 計算タスク] セクションには、最も時間を要する GPU タスクが表示されます。表示されるタスクをクリックして、[グラフィックス] タブを切り替えて、このホットスポットで収集された GPU ハードウェア・メトリック (デフォルトは概要メトリック) を調査します。
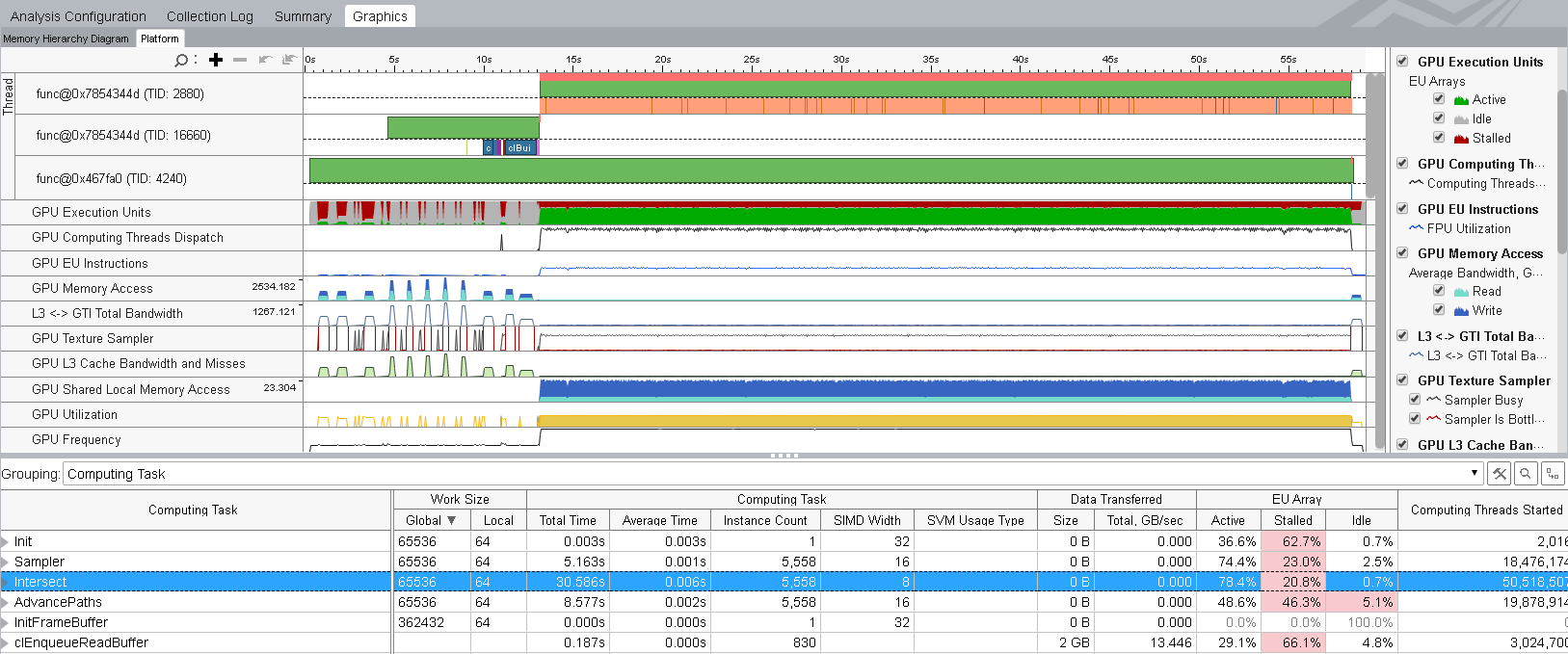
GPU 命令実行を解析
[特性化] 解析設定の [動的命令カウント] プリセットを有効にした場合、[グラフィックス] タブには、次のグループのカーネルで実行された命令の分類が表示されます。

[制御フロー] グループ |
ip レジスターを明示的に変更する if、else、endif、while、break、cont、call、calla、ret、goto、jmpi、brd、brc、join、halt および mov、add 命令 |
送信グループ |
send、sends、sendc、sendsc |
同期グループ |
待機 |
[Int16 & HP Float] | [Int32 & SP Float] | [Int64 & DP Float] グループ |
ビット操作 (整数型のみ): and、or、xor など 算術演算: mul、sub、avg、frc、mac、mach、mad、madm ベクトル算術演算: line、dp2、dp4 など 拡張数学操作: math.sin、math.cos、math.sqrt など。 |
[その他] グループ |
nop を含むほかのすべての操作 |
注
操作 (演算) のタイプはデスティネーション・オペランドのタイプにより決定されます。
[グラフィックス] タブには、SIMD 利用率メトリックも示されます。このメトリックは、スレッドの発散を引き起こす命令により、GPU を十分に活用できないカーネルを特定するのに役立ちます。スレッドがすべての実行パスを逐次実行し、他のスレッドがストールしている間にそれぞれのスレッドが 1 つのパスを実行するため、SIMD 利用率が低くなる原因としてカーネル内の条件分岐が上げられます。
追加の情報を得るには、注目する関数をダブルクリックして、[ソースビュー] を開きます。[ソース] と [アセンブリー] ペインの両方を有効にすると、ソースコードとアセンブリー・コードを並べて表示できます。SIMD 利用率の値が低いアセンブリー命令を特定し、命令をクリックすると対応するソースコード行に対応付けることができます。これにより、目的とする SIMD 利用率の基準を満たさないカーネルを検出して最適化できます。
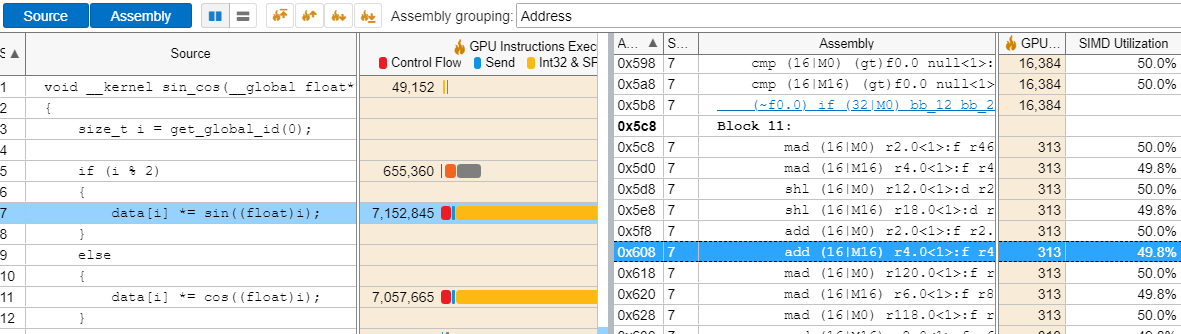
ソースを解析する
[GPU 計算/メディア・ホットスポット解析] で、[ソース解析] モードを選択すると、基本ブロックのレイテンシーまたはメモリー・レイテンシーの問題について対象とするカーネルを解析できます。これには、[グラフィックス] タブでカーネルノードを展開して関数名をダブルクリックします。インテル® VTune™ プロファイラーは、選択された関数の最もホットなソース行にジャンプします。
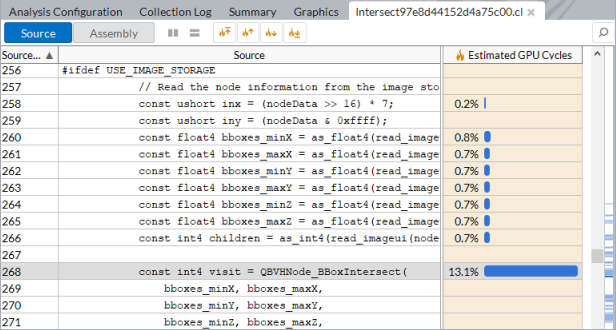
GPU 計算/メディア・ホットスポットは、カーネルソースのコード行ごとの完全な解析を可能にします。最もホットなカーネルコード行がデフォルトでハイライト表示されます。
カーネル・インスタンスごとに実行された GPU 命令のパフォーマンス統計を表示するには、[アセンブリー] ビューに切り替えます。
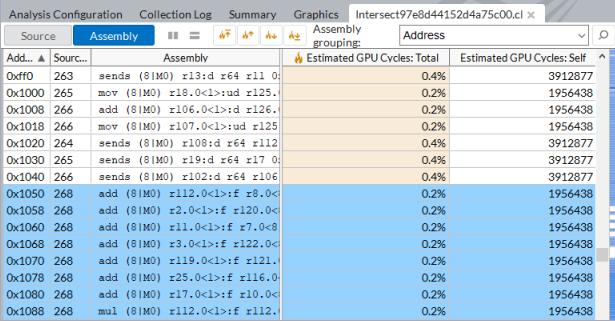
注
OpenCL* カーネルがインライン関数を使用している場合、関数ごとの GPU サイクルが正確に分類されるように、[フィルター] ツールバーの [インラインモード] が有効になっていることを確認してください。インラインモードの例。
GPU の電力消費量を調査
Linux* 環境で、ディスクリートのインテル® Iris® Xe MAX グラフィックス GPU で、GPU 計算/メディア・ホットスポット解析を実行すると、GPU デバイスで消費されるエネルギーに関連する情報を確認できます。この情報を収集するには、[解析の設定] で [電力使用を解析] オプションをオンにしてください。
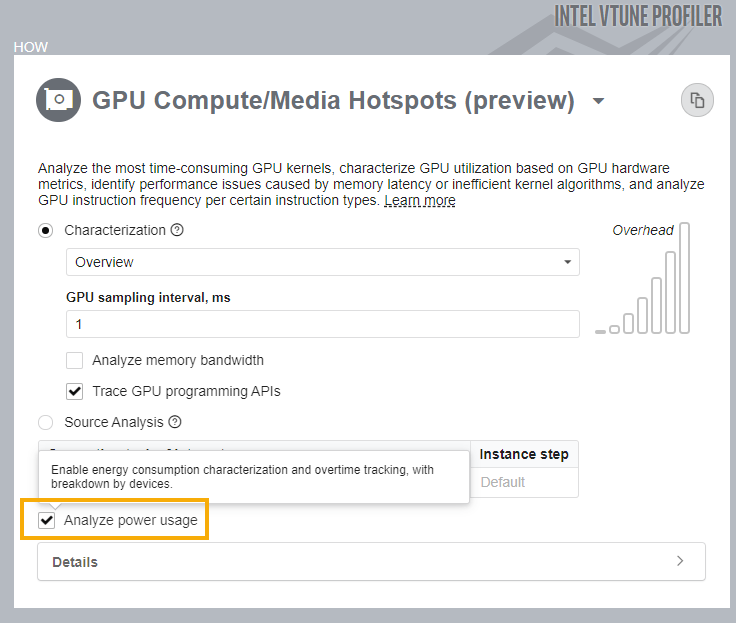
解析が完了したら、結果に示されるこれらの電力消費データを参照してください。
[グラフィックス] ウィンドウで、計算タスクごとにグループ化されたグリッドの [電力消費] カラムを確認します。このカラムをソートして、最も電力を消費した GPU カーネルを特定します。この情報は、タイムラインにもマッピングされていることを確認できます。
最も電力を消費する GPU カーネルを検出するには、適切な電力効率を得るため、上位のエネルギー・ホットスポットをチューニングすることから開始します。
GPU 処理時間も最適化を目的とする場合、カーネルごとの電力消費メトリックを確認して、パフォーマンス時間と電力使用量のトレードオフを観察します。
この比較を容易にするため、[合計時間] の隣にある [電飾消費] カラムに移動します。
電力使用量と処理時間には直接的な相互関係はないことに気づくかもしれません。最も高速に計算を行うカーネルは、エネルギー消費量が最小であるカーネルとは異なる場合があります。電力使用量の値が大きいほど、ストール/待機期間が長いかどうかを確認します。
注
電力消費メトリックは、Windows* マシンでインテル® Iris® Xe MAX グラフィックスをスキャンする GPU プロファイル解析では表示されません。例: 基本ブロック・レイテンシー・プロファイル
計算操作を行う OpenCL* カーネルをプロファイルします。
__kernel void viete_formula_comp(__global float* data)
{
int gid = get_global_id(0);
float c = 0, sum = 0;
for (unsigned i = 0; i < 50; ++i)
{
float t = 0;
float p = (i % 2 ? -1 : 1);
p /= i*2 + 1;
p /= pown(3.f, i);
p -=c;
t = sum + p;
c = (t - sum) - p;
sum = t;
}
data[gid] = sum * sqrt(12.f);
}これらの操作を比較するため、基本ブロック・レイテンシー・モードで GPU In-kernel プロファイルを実行し、グリッドでカーネルをダブルクリックしてソースビューを開きます。
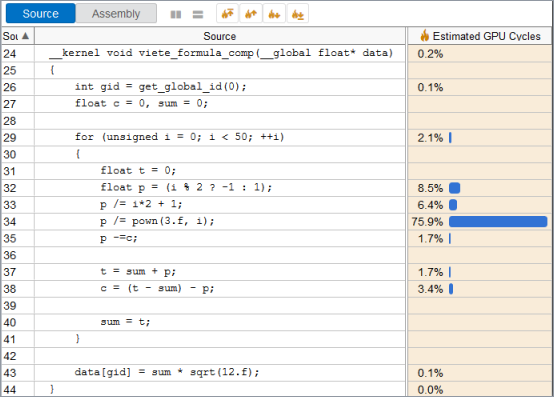
ソースビュー解析は、このカーネルで最も高価な操作として pown() 呼び出しをハイライト表示しています。
例: メモリー・レイテンシー・プロファイル
数回 (14、15 および 20 行目で) メモリーリードを行う OpenCL* カーネルをプロファイルします。
__kernel void viete_formula_mem(__global float* data)
{
int gid = get_global_id(0);
float c = 0;
for (unsigned i = 0; i < 50; ++i)
{
float t = 0;
float p = (i % 2 ? -1 : 1);
p /= i*2 + 1;
p /= pown(3.f, i);
p -=c;
t = data[gid] + p;
c = (t - data[gid]) - p;
data[gid] = t;
}
data[gid] *= sqrt(12.f);
}最も時間が長いリード命令を特定するため、メモリー・レイテンシー・モードで GPU In-kernel プロファイルを実行します。
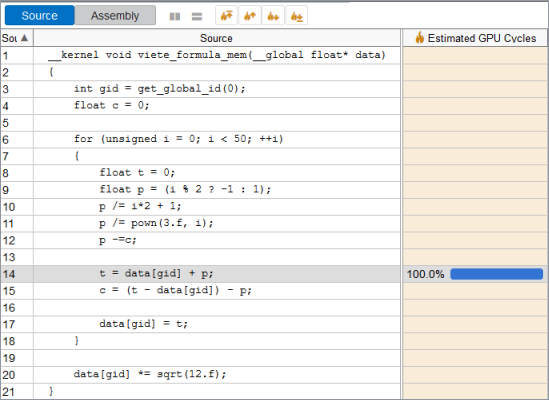
ソースビュー解析は、各スレッドが入力バッファーのそれぞれの要素のみを利用することをコンパイラーが理解して、リードを行うコードを一度だけ生成していることを示しています。入力バッファーの値はレジストリーに格納されてほかの操作で再利用されるため、コンパイラーは追加のリード命令を生成しません。