計算集約型またはスループット・アプリケーションの CPU 利用率、メモリー効率、および浮動小数点利用率を予測するには、HPC パフォーマンス特性を使用します。計算集約型やスループット・アプリケーションでは、経過時間の持続期間でハードウェア・リソースを効率的に使用する必要があります。アプリケーションのパフォーマンスとランタイムを最適化する出発点として、HPC パフォーマンス特性解析を使用します。
HPC パフォーマンス特性ビューポイントで示されるパフォーマンス・データを解釈するには、次のステップに従います。
ヒント
ハイブリッド・アプリケーションをチューニングする基本ステップを検討するには、「OpenMP* と MPI アプリケーション解析」チュートリアルを利用してください。インテル® デベロッパー・ゾーン (https://software.intel.com/en-us/itac-vtune-mpi-openmp-tutorial-lin (英語)) でチュートリアルを入手できます。https://software.intel.com/en-us/videos/hpc-applications-need-high-performance-analysis (英語) で、HPC パフォーマンス特性解析に関するウェビナーをご覧いただけます。
1. パフォーマンスのベースラインを定義する
アプリケーションの実行に関する一般的な情報を提供する [サマリー] ウィンドウから調査を始めます。最適化の主な対象には、経過時間と 1 秒あたりの浮動小数点操作数 (単精度、倍精度、および従来の x87) が含まれます。赤文字で示される部分が最適化の対象となる可能性があります。コードの改善に関する詳細を確認するには、フラグにカーソルを移動します。
最適化前後のバージョンを比較するベースラインとして経過時間と GFLOPS 値を使用します。

2. 最適化の可能性を決定する
[サマリー] ウィンドウを確認して、アプリケーションの最適化の可能性を見つけます。改善の可能性があるパフォーマンス・メトリックは赤く表示されます。特定される問題には、有効な物理コア利用率、メモリー依存、ベクトル化、およびこれらの組み合わせが含まれます。以降のセクションでは、それぞれのパフォーマンスで推奨される次のステップを説明します。
CPU 利用率
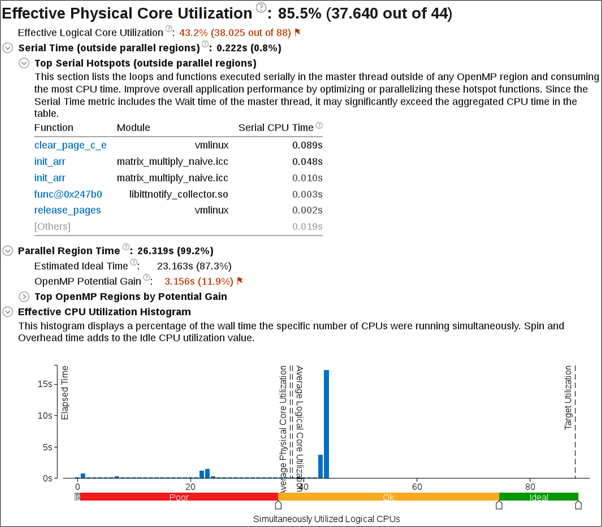
アプリケーションの並列化効率の基準として、[有効な物理コア利用率] メトリックを調査します。100% の値は、アプリケーション・コードの実行で利用可能なすべての物理コアが利用されていることを意味します。値が 100% 未満である場合、非効率な並列処理の原因を特定するため、第 2 レベルのメトリックを検討する必要があります。
論理コアの活用の可能性を理解します。状況によっては、論理コアを利用するとアプリケーションの並行性が向上し、全体のパフォーマンスを改善できます。
インテル® Xeon Phi™ プロセッサーや Intel Atom® プロセッサーなど一部のインテル® プロセッサーや、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) が無効またはサポートされないシステムでは、物理コアと論理コアの利用率メトリックの内訳は表示されません。そのような場合、単一の [効率的な CPU 利用率] メトリックが表示され、並列実行の効率が示されます。
OpenMP* や MPI ランタイム・ライブラリーを使用しないアプリケーションの場合:
アプリケーションの経過時間を CPU 利用率レベルまで細分化した [効率良い CPU 利用率の分布図] が表示されます。
[ボトムアップ] と [トップダウン・ツリー] ウィンドウを使用して、アプリケーションで CPU 利用率の時間が最も高い関数を特定します。最適化 (並列化など) の候補として、CPU 時間が最大で CPU 利用率が低い関数に注目します。
インテルの OpenMP* を使用するアプリケーション:
シリアル時間と並列領域の実行時間を比較します。シリアル領域が長い場合、さらに並列処理を導入するか、並列化が困難なシリアル領域ではアルゴリズムやマイクロアーキテクチャーのチューニングを行って、シリアル実行を短縮することを検討してください。スレッド数の多いマシンのシリアル領域は、潜在的なスケーリングに深刻な悪影響を与えるため (アムダールの法則)、可能な限り最小にすべきです。さらに並列化の候補を検出するためシリアル・ホットスポットを調査します。
[OpenMP* 潜在的なゲイン] を調査して、コードの並列領域での OpenMP* の並列化効率を予測します。[潜在的なゲイン] メトリックは、並列領域の実測された経過時間と理想化された経過時間 (スレッドのバランスが完璧で OpenMP* ランタイムのオーバーヘッドがゼロであると仮定) の差を予測します。このデータを使用して、OpenMP* 並列処理を改善することで短縮できる最大時間を見積ることができます。領域の潜在的なゲインが顕著である場合、領域名のリンクをクリックして [ボトムアップ] ウィンドウに移動し、[OpenMP* 領域] グループ化と注目する領域の選択を使用します。
並列領域内で複数のロックが使用されている場合、特定のロックのパフォーマンスへの影響を特定するためスレッド化解析を行うことを検討してください。
MPI アプリケーション:
MPI インバランス・メトリックは、プロファイルしたノードのランク数で正規化された、通信操作の待機でスピンするランクによって費やされた CPU 時間を示します。メトリックの問題検出の説明は、ランクごとの最小 MPI ビジー待機時間を基にしています。ランクごとの最小 MPI ビジー待機時間が顕著ではない場合、最小時間のランクはアプリケーション実行のクリティカル・パス上にある可能性が高いです。この場合、このランクの CPU 利用率メトリックを調査します。

MPI + OpenMP* ハイブリッド・アプリケーション:
サブセクションの [クリティカル・パス上の MPI ランク] には、シリアル時間 (OpenMP* 領域外)、並列領域時間、および OpenMP* 潜在的なゲインなどの OpenMP* 効率メトリックが表示されます。最小 MPI ビジー待機時間が顕著である場合、それはランク間の通信スキーマが最適ではない、またはほかのノードで引き起こされるインバランスが原因の可能性があります。この場合、通信スキーマの詳細な解析にインテル® Trace Analyzer & Collector を使用します。
GPU 利用率
GPU 利用率は次の場合に表示されます。
アプリケーションが GPU を使用する場合。
システムが GPU データを収集するように設定されている場合。GPU 解析向けにシステムを設定をご覧ください。
[経過時間] の下にある [GPU] セクションには、アプリケーションのオフロードが GPU でどのように機能するか、その概要が表示されます。
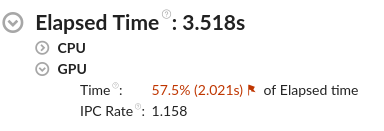
[時間] メトリックは、データ収集中の任意の時点で GPU がアイドル状態であったかを示します。100% の値は、データ収集中にアプリケーションがワークを GPU にオフロードしたことを意味します。100% 以下の場合、GPU 利用率を改善できる可能性があります。
IPC レートのメトリックは、 インテル® 統合グラフィックスの 2 つの FPU パイプラインで処理されるサイクルあたりの平均命令数を示します。ワークロードが GPU の浮動小数点機能を十分に活用するには、IPC レートを 2 に近づける必要があります。
次に、ビジー時の GPU 利用率を調査します。このセクションは、ワークロードが GPU をさらに効率良く利用できるか理解するのに役立ちます。
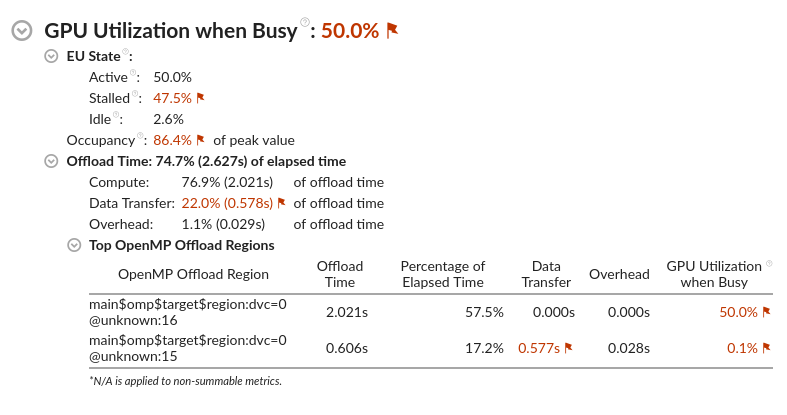
理想的には、GPU 利用率は 100% であるべきです。ビジー時の GPU 利用率 が <100% の場合、, GPU がストールまたはアイドル状態であるサイクルがあったことを意味します。
EU ステートは、GPU 実行ユニットのアクティビティーを分類します。このメトリックから、ワークロード処理中に GPU がストールまたはアイドル状態になっていないか確認します。
占有率は、GPU スレッドのスケジュール効率を示します。値が100% 未満の場合、ワークロード内のワーク項目のサイズを調整することを推奨します。GPU オフロード解析を行ってみてください。これにより、GPU で実行される計算タスクと、GPU に関連するパフォーマンス・メトリックの情報が得られます。
アプリケーションが OpenMP* オフロードを使用している場合、オフロード時間のセクションを確認してください。
オフロード時間のメトリックは、ワークロード内の OpenMP* オフロード領域の合計経過時間を示します。オフロード時間が 100% 未満の場合、GPU へオフロードするコードを増やすことを検討してください。
計算、データ転送、およびオーバーヘッドのメトリックは、 オフロード時間の内訳を理解するのに役立ちます。理想的には、計算メトリックは 100% であるべきです。データ転送コンポーネントが多い場合、ホストと GPU 間で転送するデータ量を減らしてください。
上位の OpenMP* オフロード領域のセクションは、OpenMP* オフロード領域ごとのオフロードおよび GPU メトリックの内訳を示しています。オフロード時間に占める割合が高い領域に注目します。
OpenMP* オフロード領域は、次の形式で示されます。
<func_name>$omp$target$region:dvc=<device_number>@<file_name>:<line_number>説明:
- func_name は、OpenMP* target ディレクティブが宣言されているソース関数の名前です。
- device_number は、オフロードのターゲットとなった内部 OpenMP* デバイス番号です。
- file_name と line_number は、OpenMP* target ディレクティブがあるファイルと行番号を示します。
OpenMP* アプリケーションをコンパイルする場合、func_name、file_name、および line_number フィールドで、インテル® コンパイラーにデバッグ情報オプションを渡す必要があります。デバッグ情報がない場合、これらのフィールドはデフォルト値を取得します。
| フィールド | コンパイラー・オプション | デフォルト値 | |
|---|---|---|---|
Linux* |
Windows* |
||
| line_number | -g |
/Zi |
0 |
| func_name | -g |
/Zi |
不明 |
| file_name | -g -mllvm -parallel-source-info=2 |
/Zi -mllvm -parallel-source-info=2 |
不明 |
OpenMP* オフロードを使用するアプリケーションでは、[ボトムアップ] ウィンドウに追加情報が表示されます。
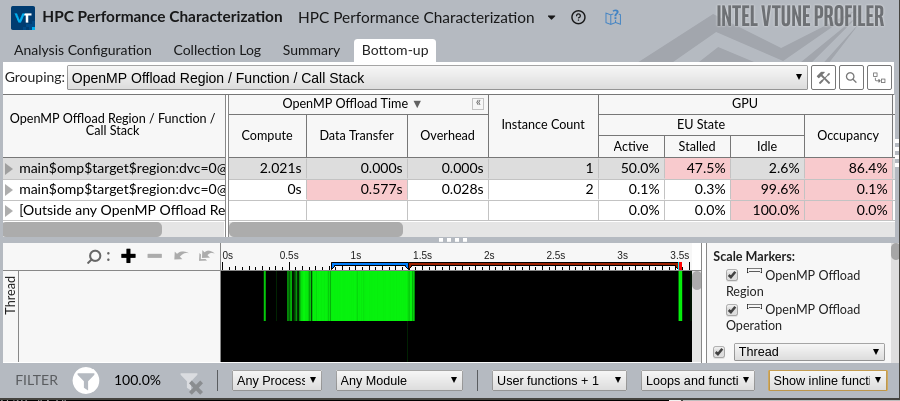
OpenMP* オフロード領域でグループ化します。このグループでは次のグリッドが表示されます。
- OpenMP* オフロード時間メトリック
- インスタンス数
- GPU トリック
タイムラインには、OpenMP* オフロード領域の範囲とその領域内の OpenMP* オフロード操作を示すスケールマーカーが表示されます。
メモリー依存
高いメモリー依存値は、データのフェッチにより実行時間の大部分が費やされていることを示します。ここでは、異なるキャッシュ階層レベル (L1、L2、L3) で処理される、または DRAM からのデータフェッチのストールによって失われたサイクルの割合を示します。DRAM アクセスに直結するラスト・レベル・キャッシュ・ミスでは、レイテンシー依存のストールと比較する際に特定の最適化手法が必要になるため、ストールがメモリー帯域幅の制限によるものであるか区別することが重要です。インテル® VTune™ プロファイラーは、DRAM 依存メトリックの問題の説明でこの問題を特定するヒントを示します。このセクションではまた、メモリーストールが NUMA の問題に関連しているか確認するため、ローカルソケットと比較したリモートソケットへのアクセスのパーセンテージを示します。

インテル® Xeon Phi™ プロセッサー開発コード名 Knights Landing では、メモリーアクセスの効率を評価する基準となるメモリーストールを測定する方法がありません。そのため、高レベルの特性メトリックとしてメモリー関連のストールを含むバックエンド依存のストールが代わりに示されます。第 2 レベルのメトリックは、特にメモリーアクセス効率に注目します。
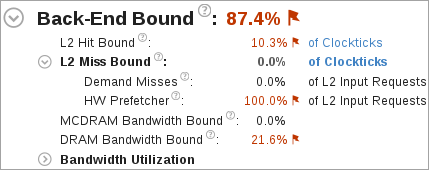
高い [L2 ヒット依存] や [L2 ミス依存] 値は、L2 ヒットやミスの処理に高い割合のサイクルが費やされたことを示します。
[L2 ミス依存] メトリックは、ハードウェア・プリフェッチャーが L2 キャッシュに取り込んだデータを考慮しません。ただし、ハードウェア・プリフェッチャーによる大量の DRAM/MCDRAM トラフィックが発生すると、帯域幅が飽和する場合があります。[要求ミス] と [HW プリフェッチャー] メトリックは、要求ロードやハードウェア・プリフェッチャーによるすべての L2 キャッシュ入力要求のパーセンテージを示します。
高い [DRAM 帯域幅依存] や [MCDRAM 帯域幅依存] 値は、経過時間の大部分が高い帯域幅利用率で費やされていることを示します。高い [DRAM 帯域幅依存] 値は、メモリーアクセス解析を実行して、高帯域幅メモリー (MCDRAM) に割り当て可能なデータ構造を識別します。
[帯域幅利用率分布図] は、システム帯域幅が特定の値 (帯域幅ドメイン) で使用された時間を表し、帯域幅利用率を、高、中、低、に分類するしきい値を提供します。しきい値は、最大値を求めるベンチマークに基づいて計算されます。しきい値を変更するには、分布図の下部のスライドバーを使用します。変更された値は、プロジェクトの以降のすべての結果に適用されます。
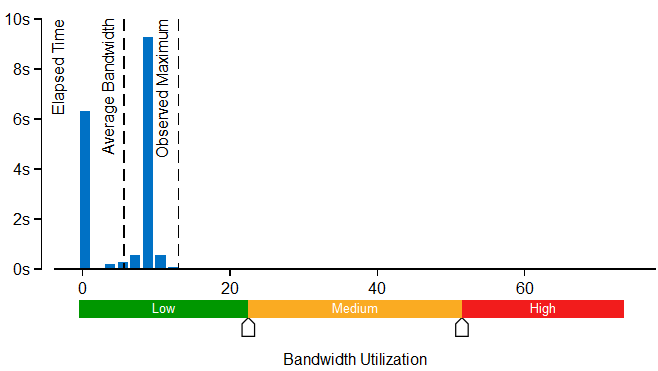
[ボトムアップ] ウィンドウに切り替えて、グリッド内の [メモリー依存] カラムを確認し最適化の可能性を判断します。
アプリケーションがメモリー依存である場合、さらに深いメトリックを取得し、それらをメモリー・オブジェクトに関連付けるため、メモリーアクセス解析を行うことを検討してください。
ベクトル化
注
ベクトル化メトリックと GFLOPS メトリックは、インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge、Broadwell、および Skylake でサポートされます。インテル® Xeon Phi™ プロセッサー (開発コード名 Knights Landing) では機能が制限されます。メトリックは、第 4 世代のインテル® プロセッサーでは利用できません。システムで利用可能なプロセッサー・ファミリーを表示するには、[解析の設定] ウィンドウの [どのように] ペインの [詳細] セクションを展開します。
ベクトル化メトリックは、パックド (ベクトル化された) 浮動小数点操作のパーセンテージを表します。0% はコードが完全にスカラーであることを意味し、100% はコードが完全にベクトル化されていることを意味します。このメトリックはベクトル命令でコードにより使用された実際のベクトル長を考慮しません。そのため、コードが完全にベクトル化されていてベクトル長の半分のみロードする従来の命令セットを使用している場合でも、ベクトル化メトリックは 100% で表示されます。
低いベクトル化は浮動小数点操作のかなりの部分がベクトル化されていないことを意味します。コードがベクトル化されなかった理由を知るには、インテル® Advisor を使用します。
第 2 レベルのメトリックで特定の精度の浮動小数点ワークのサイズの概算を予測して、特定の精度のベクトル命令の実際のベクトル長を確認します。部分ベクトル長は、従来の命令セットの使用に関する情報を提供し、追加のパフォーマンス向上につながる最新の命令セットでコードを再コンパイルする機会を示します。関連するメトリックには以下があります。
命令ミックス
メモリーリードまたはライトごとの FP 算術演算命令。
[CPU 時間による FPU を使用する上位のループ/関数] は、CPU 時間でソートされた浮動小数点演算を含む上位の関数を示し、ベクトル化されたコードの割合、ループ/関数で使用されたベクトル命令セット、ループタイプを簡単に予測できます。
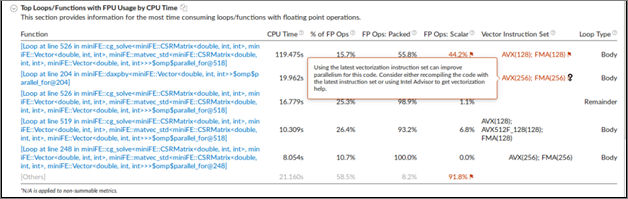
インテル® Xeon Phi™ プロセッサー開発コード名 Knights Landing では、FLOP カウンターの代わりに次の FPU メトリックが利用できます。
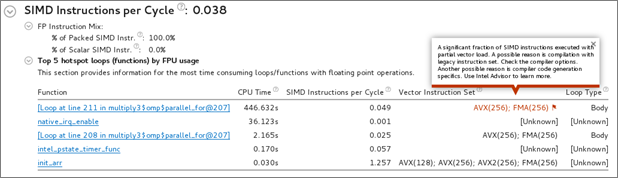
サイクルごとの SIMD 命令
サイクルあたりのパックド SIMD 命令とスカラー SIMD 命令の割合
静的解析に基づくループセットのベクトル命令
インテル® Omni-Path ファブリックの使用
インテル® Omni-Path ファブリック (インテル® OP ファブリック) メトリックは、インテル® OP ファブリック・インターコネクトを搭載した計算ノードの解析に利用できます。MPI 通信が、インターコネクト・ハードウェアの上限に達することでボトルネックになっているか確認するのに役立ちます。ここでは、インターコネクトの使用に関する、帯域幅とパケットレートについて説明します。インターコネクトは双方向であるため、帯域幅とパケットレートはどちらもデータを送信と受信に分割します。ボトルネックはどちらかの方向に関連している可能性があります。
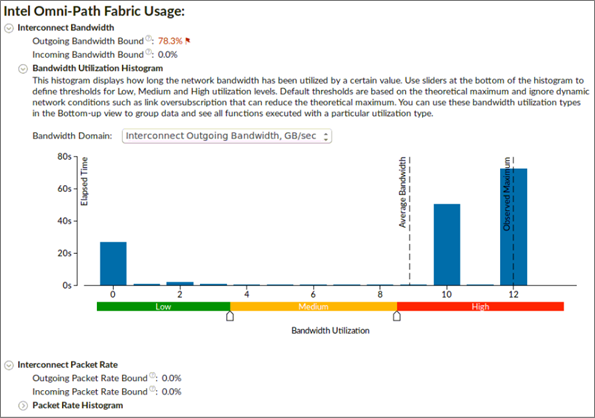
[送信帯域幅依存] と [受信帯域幅依存] メトリックは、アプリケーションがインターコネクト帯域幅の上限に接近または到達した通信に費やした経過時間のパーセンテージを示します。
[帯域幅利用率分布図] は、インターコネクト帯域幅が特定の値 (帯域幅ドメイン) で使用された時間を表し、帯域幅利用率を、高、中、低、に分類するしきい値を提供します。
[送信パケットレート] と [受信パケットレート] メトリックは、アプリケーションがインターコネクトのパケットレートの上限に接近または到達した通信に費やした経過時間のパーセンテージを示します。
[パケットレート分布図] は、インターコネクトのパケットレートが特定の値で使用された時間を表し、 帯域幅利用率を、高、中、低、に分類するしきい値を提供します。
3. ソースを解析する
最適化する関数をダブルクリックして、関連するソースコード・ファイルを [ソース/アセンブリー] ウィンドウに表示します。インテル® VTune™ プロファイラーから直接コードエディターを開いてコードを編集できます (例えば、ホットスポット関数の呼び出し回数を最小限に抑えるなど)。
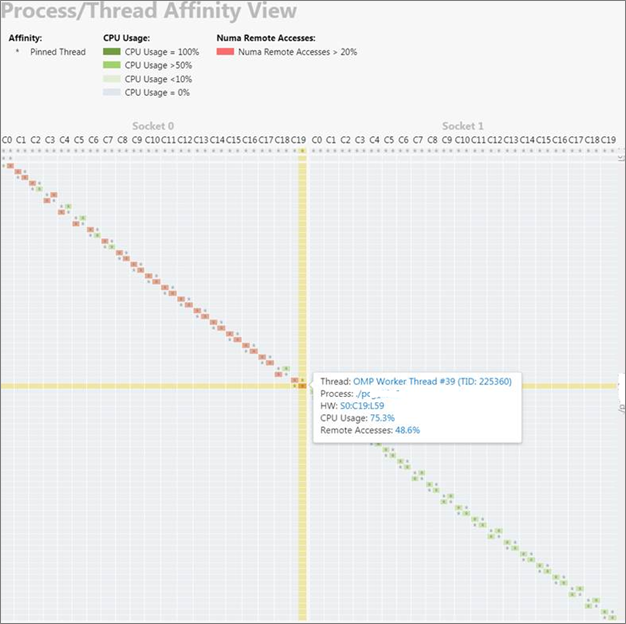
4. プロセス/スレッド・アフィニティーを解析する
結果が非効率なコア利用率や NUMA の影響を示す場合、スレッドがプロセッサー・コアにピニング (固定) されているか、またはその方法を理解することが役立ちます。
スレッド・ピニング・アフィニティーは、MPI などの並列ランタイム、環境変数、または並列ランタイムやオペレーティング・システムが提供する API を使用して適用できます。HPC パフォーマンス特性解析のアフィニティー収集を有効にするには、インテル® VTune™ プロファイラーの GUI の [スレッド・アフィニティーを収集] やコマンドラインで -knob collect-affinity=true を使用します。このオプションを有効にすると、ソケット、物理コア、および論理コアへのスレッドのピニングを示すスレッド・アフィニティー・コマンドライン・レポートを生成できます。アフィニティー情報は、スレッドのライフタイムの最後に収集されるため、結果として得られるデータは、スレッドのライフタイム中に変更された動的なアフィニティーの問題全体を示すものではありません。
HTML レポート (プレビュー機能) は、スレッドの CPU 実行およびリモートアクセス情報とともに、プロセス/スレッド・アフィニティーをレポートします。HTML レポート (プレビュー機能) を生成するには、次のコマンドを使用します。
vtune -report affinity -format=html -r <result_dir>
注
これは、プレビュー機能です。プレビュー機能は、正式リリースに含まれるかどうかは未定です。有用性に関する皆さんからのフィードバックが、将来の採用決定の判断に役立ちます。プレビュー機能で収集されたデータは、将来のリリースで下位互換性が保証されません。
5. その他の解析タイプを調査する
アプリケーションのパフォーマンスに影響するキャッシュ依存およびメモリー依存問題の詳細を確認するには、メモリーアクセス解析を実行します。
インテル® Advisor を使用して、ベクトル処理の最適化のためアプリケーションを解析します。