
移行されたコードのデバッグ: ランタイムの動作#
注
CodePin 機能は実験的なものであり、将来のリリースで完成する予定です。
状況によって、移行された SYCL* プログラムの実行時の動作が元の CUDA* プログラムと異なることがあります。これには、以下のような原因が考えられます。
ハードウェア間の演算精度の違い
CUDA* API と SYCL* API のセマンティクスの違い
自動移行中に発生したエラー
CodePin は、実行時の動作のこのような不一致のデバッグ労力を軽減するインテル® DPC++ 互換性ツールの機能です。CodePin が有効である場合、インテル® DPC++ 互換性ツールは CUDA* プログラムを SYCL* に移行しますが、CUDA* プログラムをインストルメントしたバージョンも生成します。
このインストルメント化されたコードは、選択された API またはカーネル呼び出しの前後の関連する変数のデータをレポートにダンプします。CUDA* プログラムと SYCL* プログラムから生成されたレポートを比較して、実行時の動作の相違となる原因を特定します。
CodePin を有効にする#
CodePin を有効にするには、–enable-codepin オプションを使用します。インストルメントされたプログラムは、dpct_output_codepin_cuda および dpct_output_codepin_sycl フォルダーに配置されます。
例#
次の CUDA* コードの例には、vectorAdd カーネル呼び出しの前の cudaMemcpy() に問題があります。コピーされるサイズが vectorSize * sizeof(int3) ではなく vectorSize * 12 としてハードコードされているため、移行された SYCL* プログラムは正しく機能しません。これは、int3 は sycl::int3 に移行されますが、sycl::int3 のサイズが 12 バイトではなく 16 バイトであるためです。
//example.cu
#include <iostream>
__global__ void vectorAdd(int3 *a, int3 *result) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
result[tid].x = a[tid].x + 1;
result[tid].y = a[tid].y + 1;
result[tid].z = a[tid].z + 1;
}
int main() {
const int vectorSize = 4;
int3 h_a[vectorSize], h_result[vectorSize];
int3 *d_a, *d_result;
for (int i = 0; i < vectorSize; ++i)
h_a[i] = make_int3(1, 2, 3);
cudaMalloc((void **)&d_a, vectorSize * sizeof(int3));
cudaMalloc((void **)&d_result, vectorSize * sizeof(int3));
// ホストベクトルをデバイスにコピー
// !! "sizeof(int3)" の代わりに 12 を使用
cudaMemcpy(d_a, h_a, vectorSize * 12, cudaMemcpyHostToDevice);
// CUDA カーネルを起動
vectorAdd<<<1, 4>>>(d_a, d_result);
// デバイスからホストに結果をコピー
cudaMemcpy(h_result, d_result, vectorSize * sizeof(int3),
cudaMemcpyDeviceToHost);
// 結果をプリント
for (int i = 0; i < vectorSize; ++i) {
std::cout << "Result[" << i << "]: ("
<< h_result[i].x << ", " << h_result[i].y << ", " << h_result[i].z << ")\n";
}
}
/*
Execution Result:
Result[0]: (2, 3, 4)
Result[1]: (2, 3, 4)
Result[2]: (2, 3, 4)
Result[3]: (2, 3, 4)
*/この問題をデバッグするには、CodePin を有効にして CUDA* プログラムを移行します。
dpct example.cu --enable-codepin移行後、次の 2 つのファイルが作成されます。dpct_output_codepin_sycl/example.dp.cpp と dpct_output_codepin_cuda/example.cu を使用します。
workspace
├── example.cu
├── dpct_output_codepin_sycl
│ ├── example.dp.cpp
│ ├── generated_schema.hpp
│ └── MainSourceFiles.yaml
├── dpct_output_codepin_cuda
│ ├── example.cu
│ └── generated_schema.hppdpct_output_codepin_sycl/example.dp.cpp は移行され、インストルメントされた SYCL* プログラムです。
//dpct_output_codepin_sycl/example.dp.cpp
#include <dpct/dpct.hpp>
#include <sycl/sycl.hpp>
#include "generated_schema.hpp"
#include <dpct/codepin/codepin.hpp>
#include <iostream>
void vectorAdd(sycl::int3 *a, sycl::int3 *result,
const sycl::nd_item<3> &item_ct1) {
int tid = item_ct1.get_group(2) * item_ct1.get_local_range(2) +
item_ct1.get_local_id(2);
result[tid].x() = a[tid].x() + 1;
result[tid].y() = a[tid].y() + 1;
result[tid].z() = a[tid].z() + 1;
}
int main() {
sycl::device dev_ct1;
sycl::queue q_ct1(dev_ct1,
sycl::property_list{sycl::property::queue::in_order()});
const int vectorSize = 4;
sycl::int3 h_a[vectorSize], h_result[vectorSize];
sycl::int3 *d_a, *d_result;
for (int i = 0; i < vectorSize; ++i)
h_a[i] = sycl::int3(1, 2, 3);
d_a = sycl::malloc_device<sycl::int3>(vectorSize, q_ct1);
dpct::experimental::get_ptr_size_map()[*((void **)&d_a)] =
vectorSize * sizeof(sycl::int3);
d_result = sycl::malloc_device<sycl::int3>(vectorSize, q_ct1);
dpct::experimental::get_ptr_size_map()[*((void **)&d_result)] =
vectorSize * sizeof(sycl::int3);
// ホストベクトルをデバイスにコピー
q_ct1.memcpy(d_a, h_a, vectorSize * 12);
// CUDA カーネルを起動
dpctexp::codepin::gen_prolog_API_CP(
"vectorAdd:example.cu:24:9",
&q_ct1, "d_a", d_a, "d_result", d_result);
q_ct1.parallel_for(
sycl::nd_range<3>(sycl::range<3>(1, 1, 4), sycl::range<3>(1, 1, 4)),
[=](sycl::nd_item<3> item_ct1) { vectorAdd(d_a, d_result, item_ct1); });
// デバイスからホストに結果をコピー
dpctexp::codepin::gen_epilog_API_CP(
"vectorAdd:example.cu:24:9",
&q_ct1, "d_a", d_a, "d_result", d_result);
q_ct1.memcpy(h_result, d_result, vectorSize * sizeof(sycl::int3)).wait();
// 結果をプリント
for (int i = 0; i < vectorSize; ++i) {
std::cout << "Result[" << i << "]: (" << h_result[i].x() << ", " <<
h_result[i].y() << ", " << h_result[i].z() << ")\n";
}
}
/*
Execution Result:
Result[0]: (2, 3, 4)
Result[1]: (2, 3, 4)
Result[2]: (2, 3, 4)
Result[3]: (1, 1, 1) <--- incorrect result
*/dpct_output_codepin_cuda/example.cu は移行され、インストルメントされた CUDA* プログラムです。
//dpct_output_codepin_cuda/example.cu
#include "generated_schema.hpp"
#include <dpct/codepin/codepin.hpp>
#include <iostream>
__global__ void vectorAdd(int3 *a, int3 *result) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
result[tid].x = a[tid].x + 1;
result[tid].y = a[tid].y + 1;
result[tid].z = a[tid].z + 1;
}
int main() {
const int vectorSize = 4;
int3 h_a[vectorSize], h_result[vectorSize];
int3 *d_a, *d_result;
for (int i = 0; i < vectorSize; ++i)
h_a[i] = make_int3(1, 2, 3);
cudaMalloc((void **)&d_a, vectorSize * sizeof(int3));
dpct::experimental::get_ptr_size_map()[*((void **)&d_a)] =
vectorSize * sizeof(int3);
cudaMalloc((void **)&d_result, vectorSize * sizeof(int3));
dpct::experimental::get_ptr_size_map()[*((void **)&d_result)] =
vectorSize * sizeof(int3);
// ホストんベクトルをデバイスにコピー
cudaMemcpy(d_a, h_a, vectorSize * 12, cudaMemcpyHostToDevice);
// CUDA カーネルを起動
dpctexp::codepin::gen_prolog_API_CP(
"vectorAdd:example.cu:24:9", 0,
"d_a", d_a, "d_result", d_result);
vectorAdd<<<1, 4>>>(d_a, d_result);
// デバイスからホストに結果をコピー
dpctexp::codepin::gen_epilog_API_CP(
"vectorAdd:example.cu:24:9", 0,
"d_a", d_a, "d_result", d_result);
cudaMemcpy(h_result, d_result, vectorSize * sizeof(int3),
cudaMemcpyDeviceToHost);
// 結果をプリント
for (int i = 0; i < vectorSize; ++i) {
std::cout << "Result[" << i << "]: ("
<< h_result[i].x << ", " << h_result[i].y << ", " << h_result[i].z << ")\n";
}
}
/*
Execution Result:
Result[0]: (2, 3, 4)
Result[1]: (2, 3, 4)
Result[2]: (2, 3, 4)
Result[3]: (2, 3, 4)
*/dpct_output_codepin_sycl/example.dp.cpp と dpct_output_codepin_cuda/example.cu をビルドし、ビルドされたバイナリーを実行すると、次の実行ログファイルが生成されます。
インストルメントされた CUDA* プログラムのレポート |
インストルメントされた移行後の SYCL* プログラムのレポート |
|---|---|
1[
2 {
3 "ID": "example.cu:26:3:prolog",
4 "Device Name": "GPU",
5 "Device ID": "0",
6 "Stream Address": "0xe4bb30",
7 "Free Device Memory": "16374562816",
8 "Total Device Memory": "16882663424",
9 "Elapse Time(ms)": "0",
10 "CheckPoint": {
11 "d_a": {
12 "Type": "Pointer",
13 "Data": [
14 {
15 "Type": "int3",
16 "Data": [
17 {
18 "x": {
19 "Type": "int",
20 "Data": [
21 1
22 ]
23 }
24 },
25 {
26 "y": {
27 "Type": "int",
28 "Data": [
29 2
30 ]
31 }
32 },
33 ... |
1[
2 {
3 "ID": "example.cu:26:3:prolog",
4 "Device Name": "GPU",
5 "Device ID": "0",
6 "Stream Address": "0x3fea40",
7 "Free Device Memory": "0",
8 "Total Device Memory": "31023112192",
9 "Elapse Time(ms)": "0",
10 "CheckPoint": {
11 "d_a": {
12 "Type": "Pointer",
13 "Data": [
14 {
15 "Type": "sycl::int3",
16 "Data": [
17 {
18 "x": {
19 "Type": "int",
20 "Data": [
21 1
22 ]
23 }
24 },
25 {
26 "y": {
27 "Type": "int",
28 "Data": [
29 2
30 ]
31 }
32 },
33 ... |
このレポートは、CUDA* プログラムと SYCL* プログラムの実行時の動作がどこで相違するか特定するのに役立ちます。
CodePin の結果を解析#
CodePin レポート#
codepin-report.py (dpct/c2s –codepin-report でもトリガー可能) は、CUDA* と SYCL* コードの両方から実行ログファイルを入力し、自動解析を行う互換性ツールの機能です。codepin-report.py は、データ値の不一致を識別し、実行の統計データを報告できます。
ユーザーは、次の形式で浮動小数点の比較許容値を指定できます。
{
"bf16_abs_tol": 9.77E-04,,
"fp16_abs_tol": 9.77E-04,,
"float_abs_tol": 1.19E-04,,
"double_abs_tol": 2.22E-04,,
"rel_tol": 1e-3
}最初の 4 つの項目 “bf16_abs_tol”、“bf16_abs_tol”、“bf16_abs_tol” および “bf16_abs_tol” は、対応するタイプの絶対許容範囲です。最後の “rel_tol” は、比率値で表される相対許容範囲です。
codepin-report.py は、次のコマンドラインで CUDA* および SYCL* コードの両方から生成された実行ログファイルを使用します。
codepin-report.py [-h] --instrumented-cuda-log <file path> --instrumented-sycl-log <file path> [--floating-point-comparison-epsilon <file path>]
以下は解析レポートの例です。
CodePin Summary
Total API count, 2
Consistent API count, 0
Most Time-consuming Kernel(CUDA), vectorAdd:example.cu:24:5:epilog, time:16.8069
Most Time-consuming Kernel(SYCL), vectorAdd:example.cu:24:5:prolog, time:18.3240
Peak Device Memory Used(CUDA), 445644800
Peak Device Memory Used(SYCL), 540689534976
CUDA Meta Data ID, SYCL Meta Data ID, Type, Detail
vectorAdd:example.cu:24:5:epilog,vectorAdd:example.cu:24:5:epilog,Data value,The location of failed ID Errors occurred during comparison: d_a->"Data"->[3]->"Data"->[0]->"x"->"Data"->[0] and [ERROR: DATA VALUE MISMATCH] the CUDA value 1 differs from the SYCL value 26518016.; d_result->"Data"->[3]->"Data"->[0]->"x"->"Data"->[0] and [ERROR: DATA VALUE MISMATCH] the CUDA value 2 differs from the SYCL value 26518017.
vectorAdd:example.cu:24:5:prolog,vectorAdd:example.cu:24:5:prolog,Data value,[WARNING: METADATA MISMATCH] The pair of prolog data vectorAdd:example.cu:24:5:prolog are mismatched, and the corresponding pair of epilog data matches. This mismatch may be caused by the initialized memory or argument used in the API vectorAdd.データ・フロー・グラフ#
codepin-report.py は、--generate-data-flow-graph オプションを使用してカーネルのデータ・フロー・グラフを生成できます。データ・フロー・グラフはカーネル実行の視覚化し、CUDA と SYCL の結果を比較して、CUDA コードと SYCL コード間の実行の不一致を強調表示します。データ・フロー・グラフでは、各カーネル実行とその入力と出力引数がレイヤーにグループ化され、カーネル実行の実行ステータスが表示されます。入力と出力引数の値には、“V<num>” 形式でバージョン情報がタグ付けされます。たとえば、初期バージョンは V0 としてタグ付けされ、引数の値が更新されると、バージョン番号が増加します。特定のカーネル実行で、CUDA と SYCL の結果が一致しない場合、一致しない引数ノードは赤色で表示されます。
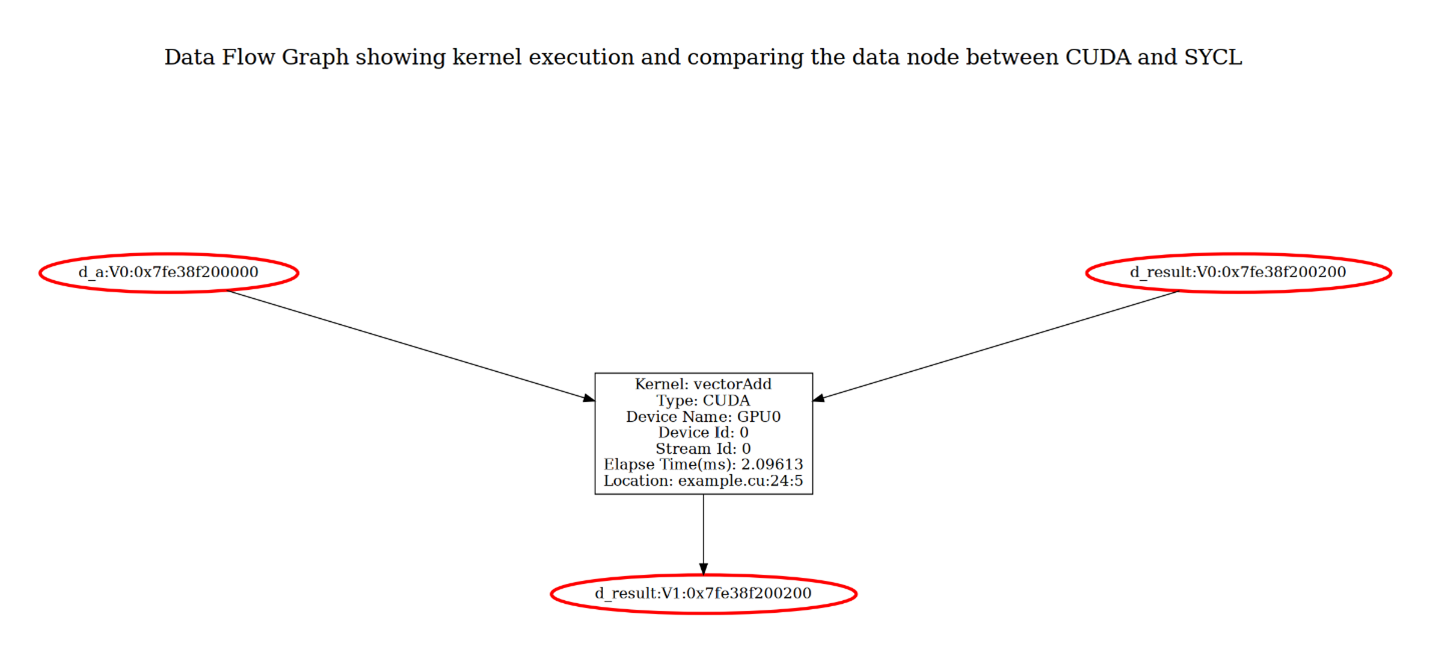
上の図は、タイトルレイヤーと実行レイヤーで構成された vectorAdd の例のデータ・フロー・グラフを示しています。実行レイヤーはカーネル実行とその入力および出力を表します。カーネルノードには、カーネル vectorAdd が GPU0 デバイスのストリーム上で実行されていることが示され、カーネルの実行時間とソースの場所も表示されます。すべての入力引数 (d_a ノードと最上位の d_result ノード) には、初期値を示す V0 がタグ付けされます。d_result は入力引数と出力引数の両方であり、その値はカーネル内で変化するため、出力引数 (下部の d_result ノード) には V1 がタグが付けされます。
ノード d_a:V0、d_result:V0、および d_result:V1 は赤色で表示され、CUDA 実行と SYCL 実行の間で値が一致しないことを示しています。この場合、結果の不一致は入力引数値によって発生し、入力引数値間の不一致はレポートに記載されているように、CUDA と SYCL 間のメモリー初期化の動作の違いによって発生する可能性があります。
このデータ・フロー・グラフのターゲットは、実行プロセスを明確に表示し、矛盾を識別したり、実行全体にわたる変数の変更を追跡することを容易にします。