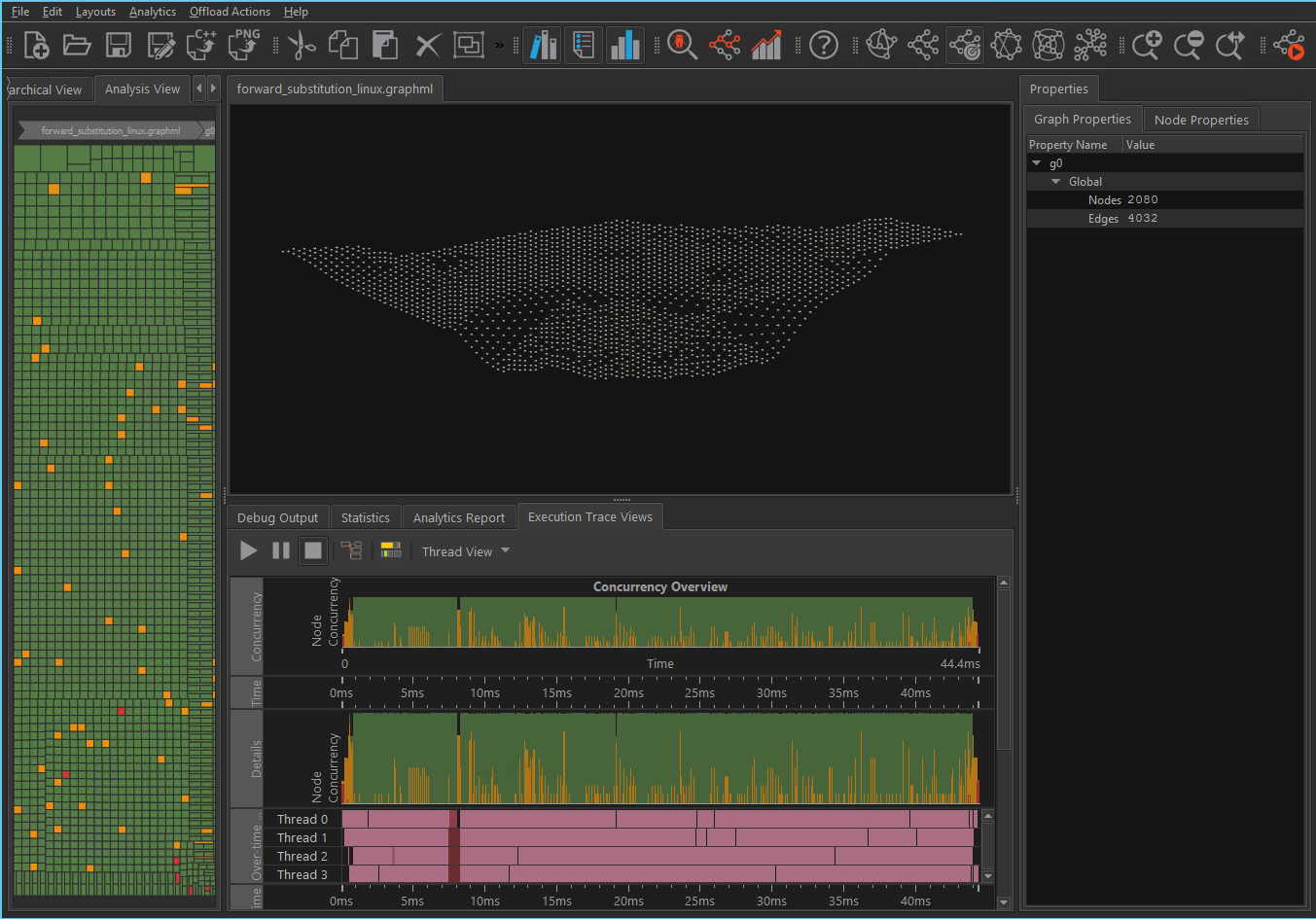
トレースによる前方置換
forward_substitution.graphml サンプルは、下三角行列での前方置換の実装を提供するインテル® oneAPI スレッディング・ビルディング・ブロック (oneTBB) のフローグラフ・アプリケーションのトポロジーと動作を示しています。提供されるトレースは、ブロックサイズが 128 の 8192x8192 行列に 4 つのスレッドを使用してグラフを 1 度実行したものです。アプリケーションのランタイムトレースは、対応する forward_substitution.traceml ファイルに含まれます。この一致するファイルは、フローグラフ・アナライザーによって自動的に読み込まれます。
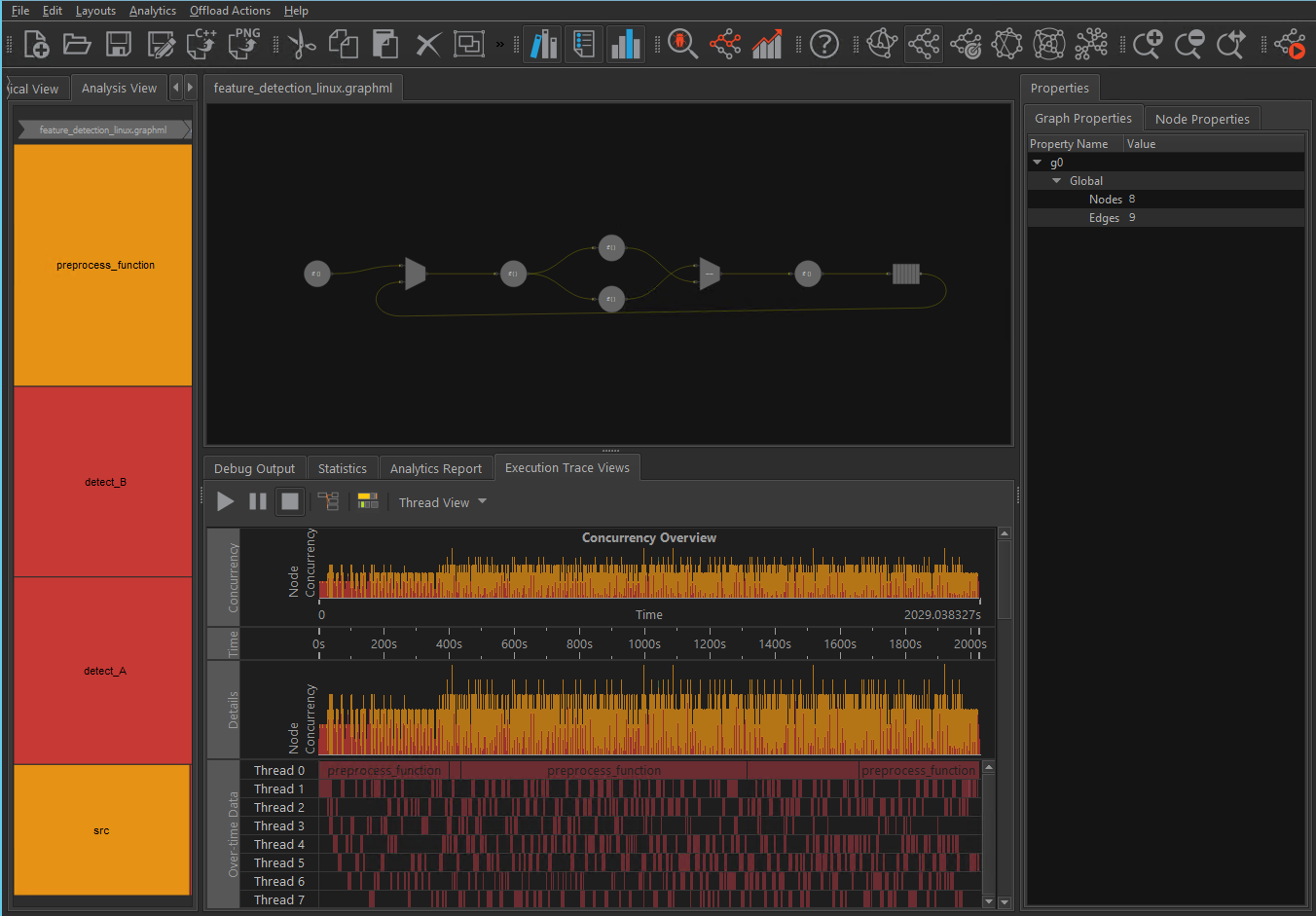
トレースによる特徴検出
feature_detection.graphml のサンプルは、oneTBB フローグラフ・アプリケーションのトポロジーと動作を示します。
このトレースは、バッファキューを提供する 8 つのスレッドと 32 個のバッファーを使用して収集されました。同時実行性は時間とともに変化しますが、最大で 8 スレッドに制限されます。
コンピューター・ビジョンとトレース
computer_vision.graphml サンプルは、データフローの並列処理の古典的な例を表し、oneTBB のフローグラフ・アプリケーションのトポロジーと動作を示しています。これは、同じ入力データを処理する 3 つの異なるコンピューター・ビジョン (CV) アルゴリズムで構成されています。データはビデオ入力ストリームであり、タイムライン・グラフの結果に定期的なパターンを確認できます (トレースにはおよそ 20 フレーム分が含まれています)。
次のことに注意してください。
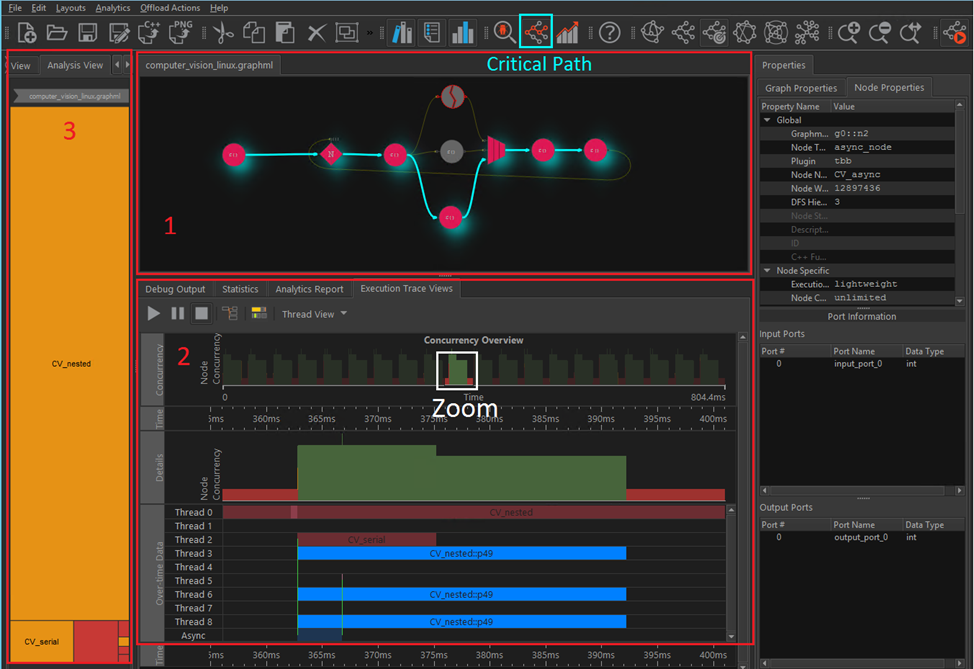
赤い枠で囲まれた領域 #1 |
クリティカル・パスの計算機能 (青緑色のボックス) を使用して、データフローのボトルネックを特定できます。これにより、クリティカル・パスにあるすべてのノードが強調表示されます。 |
白いボックス #2 |
タイムラインを拡大して、単一フレームの実行を詳しく解析します。フレームの実行フローは次のとおりです。
|
下部の赤い枠で囲まれた領域 #2 |
oneTBB のフローグラフでは、事前定義された非同期ノードに外部アクティビティーをカプセル化できます。このアクティビティーは、ワークをアクセラレーター (FPGA や GPU など) にオフロードすることを表します。このアクティビティーの始まりと終わりは、タイムラインで緑の縦線として表示されます。各 CV アルゴリズム (ノード CV シリアル、CV ネスト、CV 非同期で表現される) の単一フレーム内の単一実行を検出できます。ネストされた CV ノードは、平均してほとんどの CPU 時間を消費する oneTBB の parallel for アルゴリズムの入れ子になったノードを表しています。 |
赤い枠で囲まれた領域 #3 |
ツリーマップにはノードの平均加重が表示されます。CV_nested には、oneTBB のparallel_forアルゴリズムが含まれており、ほとんどの CPU 時間を消費します。 |