オフロードのモデル化パースペクティブを実行して [Summary (サマリー)] ウィンドウを開き、コードに関連する最も重要な情報、オフロードによって達成されると推測されるスピードアップ、上位のオフロードおよび非オフロード領域などを表示します。
必要に応じて、ドラッグアンドドロップ、展開と折りたたみ、ペインのサイズ変更を行って、サマリー表示をカスタマイズできます。
![コードに関連する最も重要な情報、オフロードによって達成されると推測されるスピードアップ、上位のオフロードおよび非オフロード領域などを [Summary (サマリー)] ペインに表示します。](GUID-D00D654B-E66F-4637-9C88-8378D157CF2D-low.png)
上位メトリック
このペインでは、オフロードによって達成されることが推測されるコードのスピードアップに関する情報を表示します。次のメトリックが報告されます。
アクセラレートされたコードのスピードアップ |
ペイン内の元の実行時間と比較したコードのスピードアップを推測 |
アムダールの法則によるスピードアップ |
アムダールの法則によって推測されるアプリケーション全体のスピードアップの推定値。アムダールの法則では、「プログラムの一部分の並列化から得られるスピードアップは、シリアル実行されるプログラム領域によって制限される」と規定されています。このメトリックは CPU - GPU 間のモデル化でのみ利用できます |
アクセラレートされたコードの割合 |
元のプログラムの合計時間に対する、高速化されたコードの割合 (パーセント)。このメトリックは CPU - GPU 間のモデル化でのみ利用できます |
オフロードの数 |
オフロードされたコード領域の数 |
プログラムのメトリック
このペインには、オフロード前の時間とオフロード後の推測時間、ホストとターゲットデバイスで消費される推測時間の内訳、オフロードコスト、ホストとターゲット・プラットフォームに関する情報、およびアプリケーション全体で推測されるパフォーマンス・メトリックが一覧表示されます。このペインは、コードをターゲットデバイスにオフロードする利点があるかどうかを判断し、高速化前のコードの時間を高速化されたコードの推測時間と比較するのに役立ちます。
オフロードを制限する要因
このペインは、コードがターゲットデバイスでより良いパフォーマンスを達成するのを妨げる要因をリストします。情報は、結果を分かり易く視覚化するためリストと図で表示されます。最も高いパーセンテージの係数は、アプリケーションを高速化する上でターゲット GPU 向けにアプリケーションを最適化する必要があることを意味します。
モデル化パラメーター
このペインには、モデル化されているターゲット GPU とパラメーターが表示されます。このペインは対話型であり、次の用途に使用できます。
- アプリケーションのパフォーマンスがモデル化されたデバイス・パラメーターを調査して、推測されるパフォーマンスにどのように影響するか理解できます。
- ターゲットデバイスを変更して、新しい構成で現在のモデル化と比較できます。
- スライドバーを使用してパラメーターを調整し、新しいデバイスのパラメーターを再モデル化して検証することでそれらが GPU のパフォーマンスに影響するか確認します。
ペイン の機能は以下のとおりです。
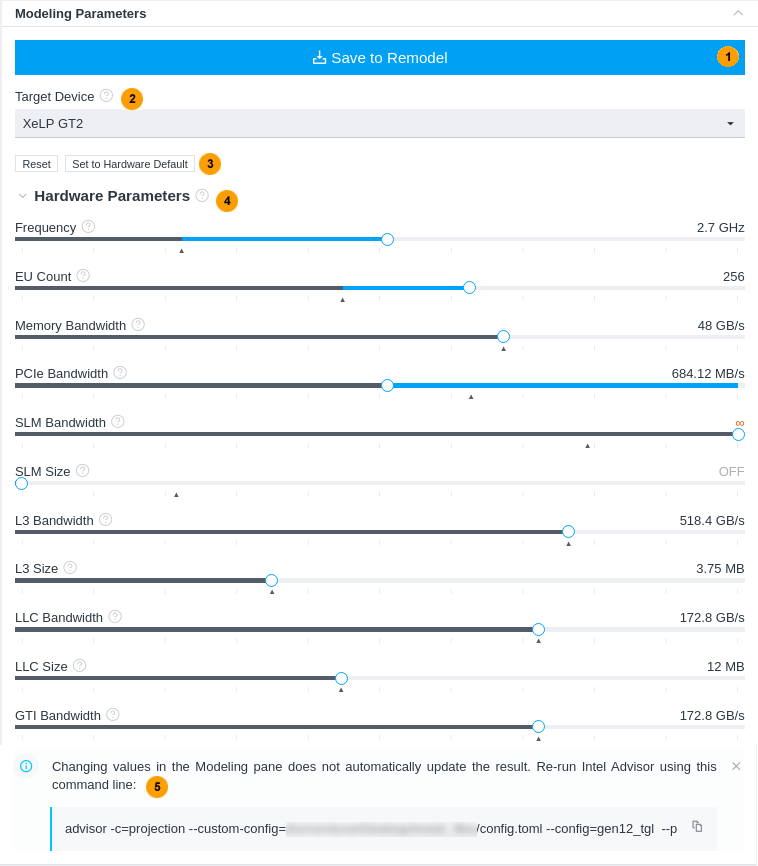
1 |
GUI と HTML レポートの CPU - GPU 間のモデル化、または HTML レポートの GPU - GPU 間のモデル化の場合: ハードウェアのパラメーターを変更した後、[Save to Remodel (再モデル化のため保存)] をクリックして、パラメーターを含む設定ファイルを保存し、それらを再モデル化に使用します。モデル化の結果は自動的に更新されませんが、設定したデバイス・パラメーターを含む構成ファイルが生成されます。 GUI レポートの GPU - GPU 間のモデル化: ハードウェアのパラメーターを変更し、ボタンをクリックしてカスタムデバイスのパフォーマンスのモデル化を再実行します。 |
2 |
モデル化するターゲットデバイスを選択して、現在のデバイス構成とのパラメーターの違いを確認します。 |
3 |
[Reset (リセット)] ボタンをクリックして、スライドバーの位置を現在のモデル化に使用されているパラメーターに戻します。このボタンはスライドバーの位置を変更すると表示されます。 例えば、現在のモデル化がカスタム構成である場合、[Set to Hardware Default (ハードウェアのデフォルトに設定)] ボタンをクリックして、スライドバーの位置をデフォルトのターゲット GPU のパラメーターに戻すことができます。 |
4 |
スライドバーを移動して、パラメーターをカスタムデバイス構成の目的の値に変更します。マウスカーソルをパラメーター名の近くにある ? アイコンに移動すると、詳細が表示されます。
パラメーター・リストは、選択されたターゲットデバイスによって異なります。これは、GPU アーキテクチャーや用語固有の違いが原因である可能性があります。 |
5 |
これは、GUI と HTML レポートの CPU - GPU 間のモデル化、または HTML レポートの GPU - GPU 間のモデル化でのみ利用できます。 生成されたパフォーマンスのモデル化コマンドをコピーして、ターミナルまたはコマンドプロンプトで実行し、カスタム・ターゲット・デバイスのアプリケーションのパフォーマンスを再モデル化します。このコマンドラインは、[Save to Remodel (再モデル化のため保存)] ボタンをクリックしてカスタム構成を保存した後に生成されます。このコマンドラインには、必要なすべてのオプションと構成ファイル、およびプロジェクト・ディレクトリーへのパスが含まれており、コピー & ペーストすることができます。 |
上位のオフロード
このペインには、コード領域ごとに次のデータを含むターゲットデバイスへのオフロードの収益性髙い上位 5 つのコード領域が表示されます。
ループ/関数 |
CPU - GPU 間のモデル化のみ。最もスピードアップされた上位 5 つのオフロードされたループ/関数のソースの場所。ループ/関数名をクリックすると、[Accelerated Regions (高速化された領域)] タブに切り替わり、対応する詳細情報が表示されます。 |
カーネル |
GPU - GPU 間のモデル化のみ。最もスピードアップされた上位 5 つのカーネルのソースの場所。カーネル名をクリックすると、[Accelerated Regions (高速化された領域)] タブに切り替わり、対応する詳細情報が表示されます。 |
実行時間 |
ベースライン・デバイスでオフロード前に測定された経過時間と、オフロード後にターゲットデバイスで推測される経過時間。 |
スピードアップ |
オフロードによってターゲットデバイス上でコード領域が達成可能な推測されるスピードアップ。 |
制限される要因 |
コード領域のパフォーマンス向上を妨げる主な要因。ダイアグラムにマウスを移動すると、それぞれの要因で制限される時間が表示されます。 |
データ転送 |
選択されたコード領域のデータ転送のオーバーヘッド。 |
上位の非オフロード
このペインには、現在のターゲットデバイスへのオフロードが推奨されない上位 5 つのコード領域が表示されます。このペインは、CPU - GPU 間のモデル化を実行する場合にのみ利用でき、GPU - GPU 間のモデル化では、推測されるスピードアップを無視してすべてのカーネルがオフロードされると想定されるため、空の表示になります。
このペインには、コード領域ごとに次のデータが示されます。
ループ/関数 |
オフロードされない上位 5 つのループ/関数のソースの場所。ループ/関数名をクリックすると、[Accelerated Regions (高速化された領域)] タブに切り替わり、対応する詳細情報が表示されます。 |
実行時間 |
ベースライン・デバイスでオフロード前に測定された経過時間と、オフロード後にターゲットデバイスで推測される経過時間。 |
スピードアップ |
コード領域のパフォーマンス向上を妨げる主な要因。ダイアグラムにマウスを移動すると、それぞれの要因で制限される時間が表示されます。 |
制限される要因 |
コード領域のパフォーマンス向上を妨げる主な要因。ダイアグラムにマウスを移動すると、それぞれの要因で制限される時間が表示されます。 |
オフロードされない理由 |
コード領域を現在のターゲットデバイスにオフロードすることが推奨されない理由。[Accelerated Regions (高速化された領域)] タブに切り替えると、詳しい情報が表示されます。 |
データ転送 |
選択されたコード領域のデータ転送のオーバーヘッド。 |