この資料は、インテルの「Downloadable Documentation: Intel® oneAPI Toolkits and Components」からダウンロードした『Intel® VTune™ Profiler』 (vtune_docs_2025.0.0.zip) の「Get Started with Application Performance Snapshot - Linux* OS」 (documentation\en\vtune\vtune-profiler_get-started-application-snapshot\) を iSUS で翻訳した日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
本ドキュメントはレイアウト調整および校閲を行っておりません。誤字脱字、製品名や用語の表記、レイアウト等の不具合が含まれる可能性があることを予めご了承ください。
はじめに
アプリケーション・パフォーマンス・スナップショットを使用すると、計算集約型アプリケーションに関連するパフォーマンスを素早くスキャンできます。
- MPI 使用
- OpenMP* 使用
- インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) 使用
- CPU 使用
- メモリーアクセスの効率
- ベクトル化
- I/O とメモリー容量
アプリケーション・パフォーマンス・スナップショットをダウンロード
アプリケーション・パフォーマンス・スナップショットは、Linux* 上のインテル® VTune™ プロファイラーのすべてのインストールにバンドルされています。アプリケーション・パフォーマンス・スナップショットは、次の方法でダウンロードすることができます。
必要条件
(オプション) アプリケーション・パフォーマンス・スナップショットの実行中に高度なメトリックを収集するには、次のソフトウェアを使用します。
- 推奨されるコンパイラー: インテル® C++ コンパイラー・ クラシック、インテル® oneAPI DPC++/C++ コンパイラー、またはインテル® Fortran コンパイラー・クラシックとインテル® Fortran コンパイラー (他のコンパイラーも使用できますが、OpenMP* 不均衡に関する情報はインテルの OpenMP* ライブラリーからのみ入手できます)
インテル® MPI ライブラリー 2017 以降。(ほかの MPICH ベースの MPI 実装も使用できますが、MPI インバランスに関する情報は、インテル® MPI ライブラリーでのみ利用できます。)
(オプション) 収集のオーバーヘッドを軽減し、メモリー帯域幅の測定値を収集するには、システム全体のモニタリングを有効にします。システム全体のモニタリングを有効にするには、次のいずれかのオプションを使用します。
環境変数/proc/sys/kernel/perf_event_paranoidに 0 以下の値を設定します)、または
インテル VTune™ プロファイラーのサンプリング・ドライバーをインストールします。ドライバーのソースは、<vtune_install_dir>/internal/sepdk/src にあります。インストール手順については、インテル® VTune™ プロファイラー・ユーザー・ガイドの「Linux* ターゲット用のサンプリング・ドライバーのビルドとインストール」ページを参照してください。
注
インテル® Omni-Path ファブリック (インテル® OP ファブリック) メトリックは、インテル® VTune™ プロファイラーのドライバーがインストールされている場合のみ利用できます。
アプリケーション・パフォーマンス・スナップショットを使用する前に、環境を設定します。
コマンドプロンプトを開きます。
アプリケーション・パフォーマンス・スナップショットを実行するため、適切な環境変数を設定します。
<vtune-install-dir>/apsvars.sh を実行します。ここで、<vtune-install-dir> はインテル® VTune™ プロファイラーがインストールされている場所です。
次に例を示します。
source /opt/intel/oneapi/vtune/latest/apsvars.sh
共有メモリー・アプリケーションの解析

次のコマンドを実行します。
aps <my app><app parameters>ここで、<my app> はアプリケーションの場所、<app parameters> はアプリケーション・パラメーターです。
アプリケーション・パフォーマンス・スナップショットは、アプリケーションを起動してデータ収集を実行します。
解析が完了すると、コマンドウィンドウにレポートが表示されます。サポートされるブラウザーで同じ情報を含む HTML レポートを開くこともできます。HTML レポートのパスは、コマンドウィンドウに示されます。次に例を示します:
firefox aps_result_01012017_1234.htmlレポートに表示されているデータを解析します。後述のメトリックの説明を参考にしてください。HTML レポートでは、メトリックにホバーすると詳細情報が表示されます。
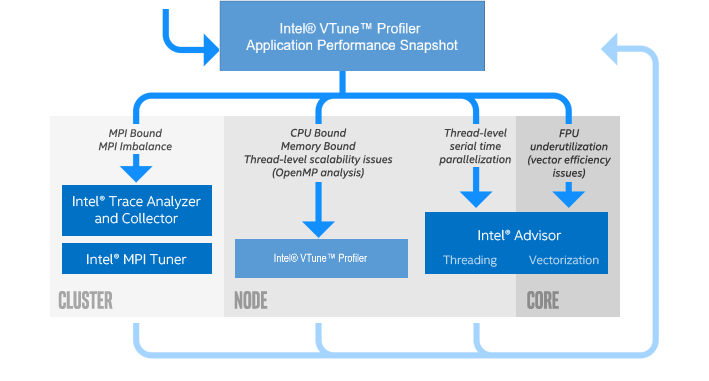
結果の解析に基づいて、適切な次のステップを決定します。一般的な次のステップには、アプリケーションのチューニング、またはインテル® VTune™ プロファイラーやインテル® Advisor などのパフォーマンス解析ツールによる詳しい調査が含まれます。
MPI アプリケーションの解析

次のコマンドを実行して、MPI アプリケーションに関するデータを収集します:
<mpi launcher><mpi parameters> aps <my app><app parameters>説明:
<mpi launcher> は、mpirun、srun、aprun などの MPI ジョブランチャーです。
<mpi parameters> は、MPI ランチャーのパラメーターです。
注
aps は最後の <mpi launcher> パラメーターでなければなりません。
<my app> は、アプリケーションの場所です。
<app parameters> はアプリケーション・パラメーターです。
アプリケーション・パフォーマンス・スナップショットは、アプリケーションを起動してデータ収集を実行します。解析が完了すると、aps_result_<date> ディレクトリーが作成されます。
次のコマンドを実行して、解析を完了します:
aps --report aps_result_<date>解析が完了すると、コマンドウィンドウにレポートが表示されます。サポートされるブラウザーで同じ情報を含む HTML レポートを開くこともできます。
レポートに表示されているデータを解析します。後述のメトリックの説明を参考にしてください。HTML レポートでは、メトリックにホバーすると詳細情報が表示されます。
ヒント
アプリケーションが MPI 依存の場合、次のコマンドを実行して、メッセージサイズ、ランク間またはノード間のデータ転送、集合操作に費やされた時間など、メッセージパッシングに関する詳細を得ることができます。
aps --report <option> app_result_<date>ランク間通信のグラフィック表現を生成するには、--format=html を使用します:
aps --report -x --format=html <result name>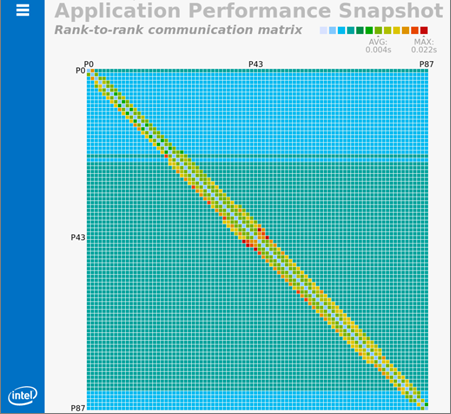
$ aps-report --help で利用可能なオプションを確認できます。
結果の解析に基づいて、適切な次のステップを決定します。一般的な次のステップには、mpitune ユーティリティーによる通信のチューニング、またはインテル® Trace Analyzer & Collector やインテル® VTune™ プロファイラーなどのパフォーマンス解析ツールによるさらに詳しい調査が含まれます。
次のステップ
一時停止/再開機能や選択的収集を使用してアプリケーション・パフォーマンス・スナップショットを実行することで、収集されるデータの精度を高め、サイズを制限できます。例えば、-start-paused オプションを使用してアプリケーションを一時停止した状態で開始し、ウォームアップ・フェーズの後に _itt_resume() や MPI_Pcontrol(1) を追加します。詳細は、『アプリケーション・パフォーマンス・スナップショット・ユーザーズガイド』 (英語) を参照してください。
インテル® Trace Analyzer & Collector (トレース・アナライザー/コレクター) (英語) : MPI アプリケーションの動作を理解し、ボトルネックを素早く特定し、正当性を向上し、インテル® アーキテクチャーで動作する並列クラスター・アプリケーションで優れたパフォーマンスを実現するためのグラフィカルなツールです。アプリケーションのスケーリングを向上します。入門ガイド (英語)
インテル® VTune™ プロファイラー (英語) : アルゴリズムのホットスポット解析、OpenMP* スレッド、マイクロアーキテクチャー全般解析、メモリーアクセス効率など、ノードレベルのパフォーマンスの詳細を提供します。C/C++、Fortran、Java*、Python*、およびコンテナのプロファイルをサポートします。導入ガイド
インテル® Advisor (英語) : Fortran、C、および C++ アプリケーションが最新のプロセッサーのパフォーマンスを最大限に引き出せるように支援する 2 つのツールを提供します。導入ガイド
ベクトル化アドバイザー: ベクトル化により恩恵を得られるループを特定し、効率良いベクトル化を妨げている原因を解析し、代替データ再構成の利点を予測する最適化ツールです。
スレッド化アドバイザー: 通常の環境に干渉することなく、スレッド化設計の選択肢を解析、設計、チューニング、および確認できるスレッド化設計/プロトタイプ生成ツールです。
メトリックのクイック・リファレンス
アプリケーション・パフォーマンス・スナップショットでは、次のメトリックが収集されます。インテル® VTune™ プロファイラーの詳細については、インテル® Vtune™ プロファイラーのユーザーガイドをご覧ください。
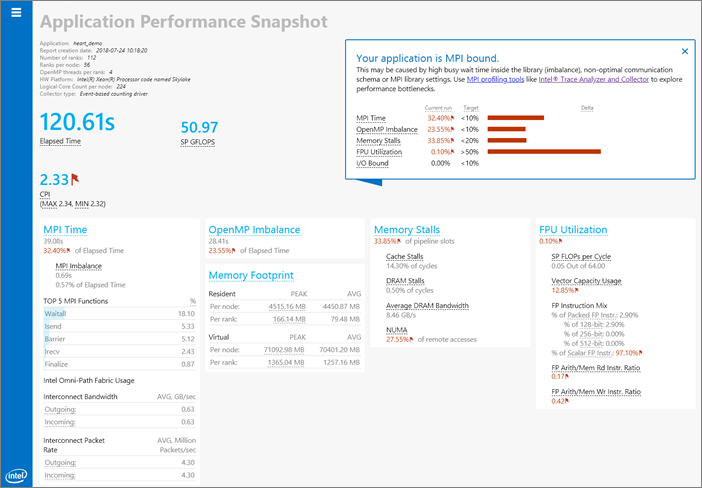
経過時間: 指定したアプリケーションの実行時間 (秒)。収集が一時停止された時間は含まれません。
SP GFLOPS: 1 秒間に計算された単精度ギガ浮動小数点操作数。SP GFLOPS メトリックは、第 3 世代インテル® Core™ プロセッサー、第 5 世代インテル® プロセッサー、および第 6 世代インテル® プロセッサーでのみ利用できます。
DP GFLOPS: 1 秒間に計算された倍精度ギガ浮動小数点操作数。DP GFLOPS メトリックは、第 3 世代インテル® Core™ プロセッサー、第 5 世代インテル® プロセッサー、および第 6 世代インテル® プロセッサーでのみ利用できます。
命令リタイアごとのサイクル (CPI): 実行された命令にかかった時間をサイクル数で測定した値。CPI =1 は、ハイパフォーマンス・コンピューティング (HPC) アプリケーションでは許容値と見なされますが、アプリケーション・ドメインごとに期待値は異なります。CPI 値は、レイテンシーの長いメモリー操作、浮動小数点操作、SIMD 操作、分岐予測ミスによりリタイアしない命令、またはフロントエンドの命令スタベーションがあると、大きくなる傾向にあります。
CCL 時間: oneCCL ライブラリー内で費やされたプロセスあたりの平均時間。MPI で費やされた時間は含まれません。高い値の原因としては、次のことが考えられます。
- ライブラリー内での待機時間が長い
- アクティブな通信
- oneCCL ライブラリーの不適切な設定
MPI 時間: MPI 呼び出しに費やされたプロセスごとの平均時間。MPI_Finalize に費やされた時間は含まれません。値が大きい場合、ライブラリー内の長い待機時間、アクティブな通信、MPI ライブラリーの最適でない設定が原因の可能性があります。このメトリックは、MPICH ベースの MPI で利用できます。
MPI の負荷インバランス: ランクが通信操作の待機でスピンに費やした CPU 時間。値が大きい場合、ランク間のアプリケーション・ワークロードのインバランス、最適でない通信スキーム、MPI ライブラリーの最適でない設定が原因の可能性があります。このメトリックは、インテル® MPI ライブラリー 2017 以降でのみ利用できます。
OpenMP* インバランス: ロードインバランスのためアプリケーションが OpenMP* 同期バリアで浪費した経過時間の割合。このメトリックは、インテルの OpenMP* ランタイム・ライブラリーでのみ利用できます。
インテル® Omni-Path ファブリックのインターコネクト帯域幅とパケットレート: 計算ノードごとの平均インターコネクト帯域幅とパケットレート (送信値と受信値)。値がインターコネクトの上限に近くなると、ネットワーク通信の待ち時間が長くなります。インターコネクト・メトリックは、インテル® VTune™ プロファイラーのドライバーがインストールされている場合にインテル® Omni-Path ファブリックで利用できます。
CPU 利用率: アプリケーションによるシステムのすべての論理 CPU コアの利用率の予測。このメトリックは、アプリケーションの並列効率を評価するのに役立ちます。100% の利用率は、アプリケーションの実行中ずっと、すべての論理 CPU コアがビジーに保たれていることを意味します。このメトリックは、アプリケーションの有用なワークと並列ランタイムで費やされた時間を区別しないことに注意してください。
メモリーストール: アプリケーションのパフォーマンスに影響を与えるメモリー・サブシステムの問題の数。要求ロード/ストア命令によりパイプラインがストールする可能性のあるスロットの割合を測定します。値が大きい場合、キャッシュストール、DRAM ストール、およびリモートアクセスの割合メトリックを確認して、メモリー関連のパフォーマンス・ボトルネックの性質を理解します。平均メモリー帯域幅がシステム帯域幅の上限に近い場合、メモリーストールを回避するため、メモリー依存アプリケーション向けの最適化手法が必要になる可能性があります。
ベクトル化: パックド (ベクトル化された) 浮動小数点操作のパーセンテージを表します。値が大きいほど、コードがベクトル化された領域は大きくなります。このメトリックは、ベクトル命令の実行に使用される実際のベクトル長を考慮していません。そのため、コードが完全にベクトル化されベクトル長の半分のみロードする従来の命令セットを使用している場合でも、ベクトル化メトリックは 100% で表示されます。
I/O 操作: ディスクからのデータの読み取りまたはディスクへのデータの書き込みにアプリケーションが費やした時間。Read (読み取り) 値と Write (書き込み) 値は、経過時間中に読み書きされるデータの平均と最大量を示します。このメトリックは、MPI アプリケーションでのみ利用できます。
PCIe* メトリック: PCIe* デバイスによって開始された受信読み取りおよび書き込み操作の平均帯域幅を示します。GPU およびネットワーク・コントローラー・デバイスのデータが表示されます。
メモリー使用量: 仮想メモリーと常駐メモリーのランクごとおよびノードごとの平均使用量。
GPU メトリック: このメトリックのコレクションには、アプリケーションの GPU 利用率を解析できるメトリックが含まれています。これらのメトリックを使用すると、GPU がオフロードタスクでビジー状態だった時間の割合を確認できるほか、実行ユニットがどの程度活用されているか把握できます。
ドキュメントとリソース
リソース |
説明 |
|---|---|
アプリケーション・パフォーマンス・スナップショットを含む、インテルのすべてのパフォーマンス・スナップショット・ツール用のユーザーフォーラム。 |
|
各メトリックの詳細やアプリケーション最適化のベスト・プラクティスなど、アプリケーション・パフォーマンス・スナップショットについて詳しく説明したマニュアル。 |
法務上の注意書き
インテルのテクノロジーを使用するには、対応したハードウェア、特定のソフトウェア、またはサービスの有効化が必要となる場合があります。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
実際の費用と結果は異なる場合があります。
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
本ソフトウェアおよび関連ドキュメントは、インテルが著作権を有する著作物であり、その使用には付随する明示的なライセンス (「ライセンス」) が適用されます。ライセンスに明記されている場合を除き、インテルから事前に書面による許可なしに、ソフトウェアまたは関連ドキュメントを使用、改変、複製、公開、配布、開示、転送してはなりません。
本ソフトウェアおよび関連ドキュメントは現状のまま提供され、ライセンスに明記されている場合を除き、明示されているか否かにかかわらず、いかなる保証もいたしません。