インテル® VTune™ プロファイラーによるパフォーマンス解析の開始点として [サマリー] ウィンドウを使用します。このウィンドウにアクセスするには、結果タブの [サマリー] サブタブをクリックします。
インテル® VTune™ プロファイラーはインテル® アーキテクチャーで定義されるしきい値と解析したメトリックを比較し、アプリケーション全体のパフォーマンスの問題としてメトリックをピンク色でハイライト表示することがあります。そのような値の問題に関する説明は、重要なメトリックの下に表示されます。または、ハイライト表示されたメトリックにカーソルを移動して表示することもできます。
[サマリー] ウィンドウの [HPC パフォーマンス特性] ビューポイントには、次のアプリケーション・レベルの統計情報が示されます。
注
 [クリップボードへコピー] ボタンをクリックして、選択したサマリーセクションの内容をクリップボードへコピーできます。
[クリップボードへコピー] ボタンをクリックして、選択したサマリーセクションの内容をクリップボードへコピーできます。
解析メトリック
[サマリー] ウィンドウは、アプリケーション実行の全体を予測するのに役立つメトリックを表示します。疑問符  アイコンにカーソルを移動すると、メトリックを説明するポップアップ・ヘルプが表示されます。
アイコンにカーソルを移動すると、メトリックを説明するポップアップ・ヘルプが表示されます。
経過時間、GFLOPS、GFLOPS 上限値 (インテル® Xeon Phi™ プロセッサーのみ) のメトリックを指標として、最適化前後の結果を比較するベースラインに使用します。

CPU 利用率
CPU 利用率には、収集時間内の CPU 使用メトリックが表示されます。
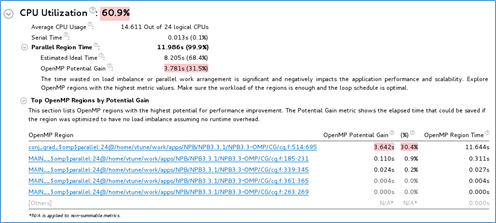
メトリックには以下が含まれます。
OpenMP* 解析収集時間: プログラムのシリアル領域 (並列領域外) と並列領域のメトリックを表示します。シリアル時間が長い場合、[上位のシリアル・ホットスポット] を確認して、並列処理を導入するか、並列化が困難なシリアル領域ではアルゴリズムやマイクロアーキテクチャーのチューニングを行って、シリアル実行を短縮することを検討してください。スレッド数の多いマシンのシリアル領域は、潜在的なスケーリングに深刻な悪影響を与えるため (アムダールの法則)、可能な限り最小にすべきです。
潜在的なゲインによる上位 OpenMP* 領域: コードの並列領域における OpenMP* による並列化の効率を表示し、MPI インバランスをチェックします。[潜在的なゲイン] メトリックは、並列領域の実測された経過時間と理想化された経過時間 (スレッドのバランスが完璧で OpenMP* ランタイムのオーバーヘッドがゼロであると仮定) の差を予測します。このデータを使用して、並列実行を改善することで短縮できる最大時間を見積ることができます。領域の潜在的なゲインが顕著である場合、領域名のリンクをクリックして [ボトムアップ] ウィンドウに移動し、[OpenMP* 領域] グループ化と注目する領域の選択を使用します。
効率良い CPU 利用率の分布図: アプリケーションが同時実行した特定の CPU 数に対するウォール時間のパーセンテージを示すグラフ。CPU 使用には、実際のワークを実行しないスピンとオーバーヘッド時間は含まれません。垂直バーにカーソルを移動して、アプリケーションが論理 CPU コア数で費やした経過時間を特定できます。パフォーマンス測定のベースラインとして、平均物理コア利用率と平均論理コア利用率を使用します。どの時点の CPU 利用も利用可能な論理 CPU コア数を超えることはできません。
メモリー依存

高いメモリー依存値は、データのフェッチにより実行時間のかなりが費やされていることを示します。ここでは、異なるキャッシュ階層レベル (L1、L2、L3) で処理される、または DRAM からのデータフェッチのストールによって失われたサイクルの割合を示します。DRAM アクセスに直結するラスト・レベル・キャッシュ・ミスでは、レイテンシー依存のストールと比較する際に特定の最適化手法が必要になるため、ストールがメモリー帯域幅の制限によるものであるか区別することが重要です。インテル® VTune™ プロファイラーは、DRAM 依存メトリックの問題の説明でこの問題を特定するヒントを示します。このセクションではまた、メモリーストールが NUMA の問題に関連しているか確認するため、ローカルソケットと比較したリモートソケットへのアクセスのパーセンテージを示します。
インテル® Xeon Phi™ プロセッサー開発コード名 Knights Landing では、メモリーアクセスの効率を評価する基準となるメモリーストールを測定する方法がありません。そのため、高レベルの特性メトリックとしてメモリー関連のストールを含むバックエンド依存のストールが代わりに示されます。第 2 レベルのメトリックは、特にメモリーアクセス効率に注目します。
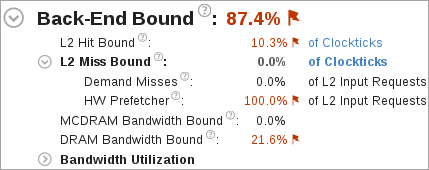
高い [L2 ヒット依存] や [L2 ミス依存] 値は、L2 ヒットやミスの処理に高い割合のサイクルが費やされたことを示します。
[L2 ミス依存] メトリックは、ハードウェア・プリフェッチャーが L2 キャッシュに取り込んだデータを考慮しません。ただし、ハードウェア・プリフェッチャーによる大量の DRAM/MCDRAM トラフィックが発生すると、帯域幅が飽和する場合があります。[要求ミス]と [HW プリフェッチャー] メトリックは、要求ロードやハードウェア・プリフェッチャーによるすべての L2 キャッシュ入力要求のパーセンテージを示します。
高い [DRAM 帯域幅依存] や [MCDRAM 帯域幅依存] 値は、経過時間の大部分が高い帯域幅利用率に費やされていることを示します。高い [DRAM 帯域幅依存] 値は、メモリーアクセス解析を実行して、高帯域幅メモリー (MCDRAM) に割り当て可能なデータ構造を識別します。
[帯域幅利用率分布図] は、システム帯域幅が特定の値 (帯域幅ドメイン) で使用された時間を表し、帯域幅利用率を、高、中、低、に分類するしきい値を提供します。しきい値は、最大値を求めるベンチマークに基づいて計算されます。しきい値を変更するには、分布図の下部のスライドバーを使用します。変更された値は、プロジェクトの以降のすべての結果に適用されます。
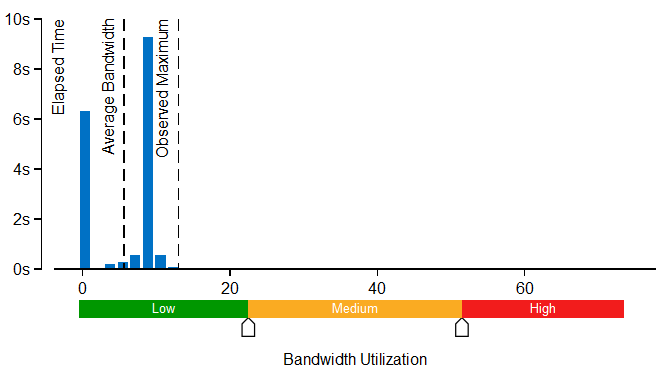
アプリケーションがメモリー依存である場合、さらに深いメモリーの問題を特定し、メモリー・オブジェクトを詳しく調査するため、メモリーアクセス解析を行うことを検討してください。
ベクトル化
注
ベクトル化メトリックと GFLOPS メトリックは、インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge、Broadwell、および Skylake でサポートされます。インテル® Xeon Phi™ プロセッサー (開発コード名 Knights Landing) では機能が制限されます。メトリックは、第 4 世代のインテル® プロセッサーでは利用できません。システムで利用可能なプロセッサー・ファミリーを表示するには、[解析の設定] ウィンドウの [どのように] ペインの [詳細] セクションを展開します。
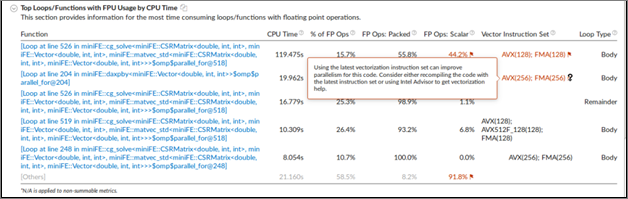
このメトリックは、アプリケーションがベクトル化に浮動小数点ユニットをどの程度効率的に利用しているかを示します。[GFLOPS] または [GFLOPS 上限依存] (インテル® Xeon Phi™ プロセッサーのみ) を展開して、スカラーとパックド GFLOPS 数を表示します。このセクションから、ベクトル化されていない FLOP 量の予測が得られます。
[CPU 時間による FPU を使用する上位のループ/関数] には、CPU 時間でソートされた浮動小数点演算を含む上位の関数を示し、ベクトル化されたコードの割合、ループ/関数で使用されたベクトル命令セット、ループタイプを簡単に予測できます。
例えば、浮動小数点ループ (関数) が帯域幅依存である場合、メモリーアクセス解析を使用して帯域幅依存の問題を解決します。浮動小数点ループがベクトル化されていれば、インテル® Advisor を使用してベクトル化の効率を改善します。ループが帯域幅依存である場合、ベクトル化を改善する前に帯域幅依存の問題を解決する必要があります。関数名をクリックして [ボトムアップ] ウィンドウに切り替えて、関数がメモリー依存であるかを判断します。
インテル® Omni-Path ファブリックの使用
インテル® Omni-Path ファブリック (インテル® OP ファブリック) メトリックは、インテル® OP ファブリック・インターコネクトを搭載した計算ノードの解析に利用できます。MPI 通信が、インターコネクト・ハードウェアの上限に達することでボトルネックになっているか確認するのに役立ちます。ここでは、インターコネクトの使用に関する、帯域幅とパケットレートについて説明します。インターコネクトは双方向であるため、帯域幅とパケットレートはどちらもデータを送信と受信に区別します。ボトルネックはどちらかの方向に関連している可能性があります。
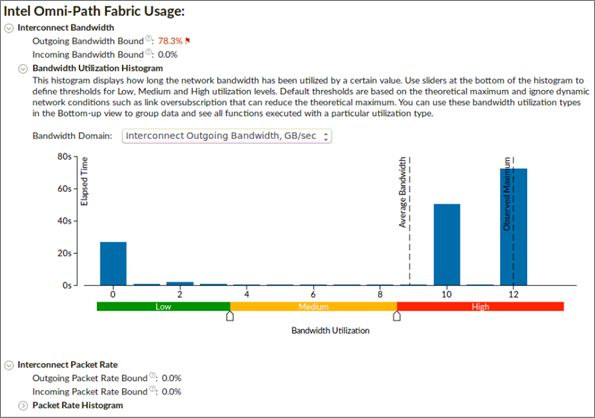
[送信帯域幅依存] と [受信帯域幅依存] メトリックは、アプリケーションがインターコネクト帯域幅の上限に接近または到達した通信に費やした経過時間のパーセンテージを示します。
[帯域幅利用率分布図] は、インターコネクト帯域幅が特定の値 (帯域幅ドメイン) で使用された時間を表し、帯域幅利用率を、高、中、低、に分類するしきい値を提供します。
[送信パケットレート] と [受信パケットレート] メトリックは、アプリケーションがインターコネクトのパケットレートの上限に接近または到達した通信に費やした経過時間のパーセンテージを示します。
[パケットレート分布図] は、インターコネクトのパケットレートが特定の値で使用された時間を表し、帯域幅利用率を、高、中、低、に分類するしきい値を提供します。
収集とプラットフォーム情報
このセクションでは次のデータを提供します。
アプリケーションのコマンド行 |
ターゲット・アプリケーションへのパス。 |
オペレーティング・システム |
収集に使用されたオペレーティング・システム。 |
コンピューター名 |
収集に使用されたコンピューター名。 |
結果サイズ |
インテル® VTune™ プロファイラーで収集された結果のサイズ。 |
収集開始時間 |
外部収集の開始時間 (UTC 形式)。[タイムライン] ペインで、カスタムコレクターが提供するパフォーマンス統計を調査できます。 |
収集停止時間 |
外部収集の停止時間 (UTC 形式)。[タイムライン] ペインで、カスタムコレクターが提供するパフォーマンス統計を調査できます。 |
CPU 情報 |
|
名前 |
収集に使用されたプロセッサー名。 |
周波数 |
収集に使用されたプロセッサーの周波数。 |
論理 CPU 数 |
収集に使用するマシンの論理 CPU コア数。 |
物理コア数 |
システム上の物理コア数。 |
ユーザー名 |
データ収集を開始したユーザー。このフィールドは、製品のインストール時にユーザーごとのイベントベース・サンプリング収集モードを有効にすると利用できます。 |