スータビリティー・ツールが、データを収集するためプログラムのターゲット実行形式を実行した後、[Suitability Report (スータビリティー・レポート)] ウィンドウが表示されます。ここには、アノテーションが追加された並列サイトとタスクの解析を基に予測されたパフォーマンスが表示されます。
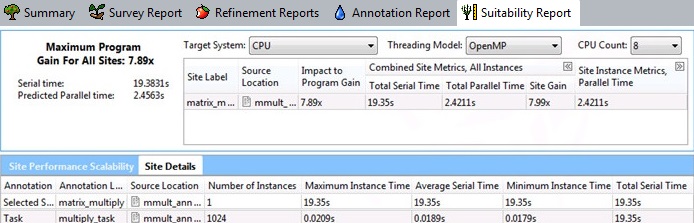
このスクリーンショットには、ターゲットシステム が CPU の場合のデータが表示されています。実際のシステムでの実行結果は異なります。
|
左上のエリアはプログラムの Maximum Program Gain for All Sites (すべてのサイトの最大プログラムゲイン) を表示します。並列処理を実装する主な目的は、すべてのサイトの最大プログラムゲイン を増やし、並列プログラムの実行をより高速化することです。測定されたシリアル実行時間、予測並列実行時間、および測定されたポーズされた時間は、Maximum Program Gain for All Sites (すべてのサイトの最大プログラムゲイン) の下に表示されます。予測されたスータビリティー・ゲイン値を使用して、詳しい情報を得た上で並列処理を実装すべき場所を決定できます。 スータビリティー・ツールが検出したアノテーションに関連するエラーは、[Suitability Report (スータビリティー・レポート)] ウィンドウの上部に表示されます。エラーが発生した場合、表示されているスータビリティー・データの信頼性は保証されません。アノテーションに関連するエラーは、アノテーションの不足により正しいシーケンスのアノテーションが実行されなかった場合、予期しない実行パスが実行された場合、またはスータビリティー・データ収集がターゲットの実行中にポーズされた場合に発生する可能性があります。 |
|
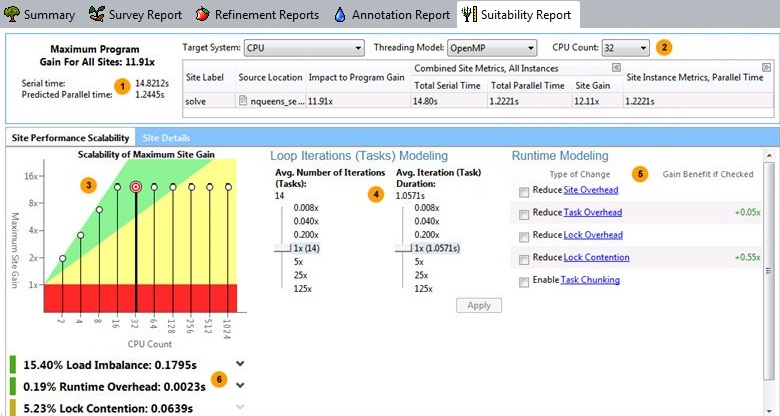
右上にある modeling parameters (モデル化パラメーター) を使用してパフォーマンスをモデル化します。ドロップダウン・リストから、ハードウェア構成とスレッド化モデル (並列フレームワーク) を選択します。[Target System (ターゲットシステム)] で、インテル® Xeon Phi™ プロセッサーを選択すると、追加の項目 [Coprocessor Threads (コプロセッサー・スレッド)] が表示されます。 この行の下のデータグリッドには、プログラム実行中に検出された各並列サイトのパフォーマンスの予測値が表示されます。[Site Label (サイトラベル)] には、サイト・アノテーションへの引数が示されます。すべてのサイトの最大プログラムゲインへの各サイトの貢献度を推測するため、[Site Gain (サイトゲイン)] と [Impact to Program Gain (プログラムゲインへの貢献度)] の予測 (高い値が良い) を調査します。[Combined Site Metrics (結合されたサイトメトリック)] または [Site Instance Metrics (サイト・インスタンス・メトリック)] の下にあるデータを展開するには、見出しの右にある 選択した並列サイトのソースコードを表示するには、[Suitability Source (スータビリティー・ソース)] ウィンドウを表示する行をクリックします。 コマンドツール・バーを表示/非表示にするには、 |
|
[Scalability of Maximum Site Gain (最大サイトゲインのスケーラビリティー)] グラフには、選択したサイトのパフォーマンス・サマリーが示されます。グラフの X 軸には、CPU プロセッサー数またはコプロセッサーのスレッド数の合計が示され、Y 軸にはターゲットの予測パフォーマンス・ゲインが示されます。デフォルトの [CPU Count (CPU 数)] と [Maximum CPU Count (最大 CPU 数)] を変更するには、オプション値を設定します。 [CPU] の [Target System (ターゲットシステム)] を選択した場合、タスクやロックと同様に選択したサイトの詳しい特性を見るには、[Site Details (サイト詳細)] タブをクリックします。 |
|
並列パフォーマンスを改善する異なるループ構造、反復数、およびインスタンスの存続時間を調査するには、[Loop Iterations (Tasks) Modeling (ループ反復 (タスク) のモデル化)] (または [Tasks Modeling (タスクのモデル化)]) の modeling parameters (モデル化パラメーター) を使用します。 例えば、入れ子のループ構造を変更したり、ループ本体のコードを変更したり、反復数を変更した場合の影響を確認したいこともあるでしょう。 タスク・アノテーションがタスク並列処理を示している場合、(データ並列処理を示す [Loop Iterations (Task) Modeling (ループ反復 (タスク) モデル化)] の代わりに) [Task Modeling (タスクのモデル化)] が表示されます。 |
|
[Runtime Modeling (ランタイムのモデル化)] の モデル化パラメーター を使用して、どの並列オーバーヘッド・タイプが、並列パフォーマンスに影響するか調査します。後で選択した並列フレームワークの機能を使用するか、並列処理を実装した後に並列コードをチューニングして指摘されたカテゴリーに対処する場合、カテゴリーを確認します。 [Target System (ターゲットシステム)] で [Intel Xeon Phi (インテル® Xeon Phi™)] または [Offload to Intel Xeon Phi (インテル® Xeon Phi™ へオフロード)] を選択した場合、[Runtime Modeling (ランタイムのモデル化)] の下に [インテル® Xeon Phi™ 製品向けの高度なモデル化] オプションが表示されます。このオプションを展開するには、[インテル® Xeon Phi™ 製品向けの高度なモデル化] の右にある下方向の矢印をクリックします。 |
|
グラフの下には、予測されるパフォーマンス・ゲインを妨げる問題のリストとシリアルおよび予測並列時間が示されます。行を展開するには、項目名の右にある下矢印をクリックします。大部分の問題は、[Runtime Modeling (ランタイムのモデル化)] の モデル化パラメーター に関連します。後で、インテル® VTune™ プロファイラー などの解析ツールを使用して、並列プログラムの実際のパフォーマンスを測定できます。 |


 アイコンをクリックします。データを折りたたむには見出しの右にある
アイコンをクリックします。データを折りたたむには見出しの右にある  をクリックします。
をクリックします。 または
または  アイコンをクリックします。
アイコンをクリックします。



ターゲットシステムのハードウェア設定
[ターゲットシステム] で解析するハードウェアのタイプを選択します。このドロップダウン・リストを利用して、各タイプで予測されるパフォーマンス特性をチェックできます。
[CPU] は、CPU のみの予測パフォーマンスを示します。この項目は、インテル® Xeon® プロセッサーや同等のプロセッサーなど、並列コプロセッサーを持たない場合に選択します。インテル® Xeon Phi™ コプロセッサーでは、インテル® Xeon® プロセッサーなどのホスト・プロセッサーのみをモデル化する場合にこの設定を選択します。この設定を選択すると、[CPU Count (CPU 数)] モデル化パラメーターを指定できます。
[Intel Xeon Phi (インテル® Xeon Phi™)] は、ホスト・プロセッサーではなくインテル® Xeon Phi™ コプロセッサー・コアのみを使用する場合の予測パフォーマンスを表示します。このパラメーターは、インテル® Xeon Phi™ コプロセッサー・コアとホスト CPU 間で交換されるデータは考慮しません。この設定を選択すると、[Coprocessor Threads (コプロセッサー・スレッド数)] モデル化パラメーターを指定できます。
[Offload to Intel Xeon Phi (インテル® Xeon Phi™ へオフロード)] は、ホスト CPU がプログラムの実行を開始した後、プログラムの実行がホスト CPU 上で再開される前に、インテル® Xeon Phi™ コプロセッサーのメニーコアを使用して並列コードを実行する場合の予測パフォーマンスを表示します。この設定を選択すると、[Coprocessor Threads (コプロセッサー・スレッド数)] と [CPU Count (CPU 数)] モデル化パラメーターを指定できます。
[ターゲットシステム] が [インテル® Xeon Phi™] である場合に表示されるデータ
[ターゲットシステム] で [CPU] の代わりに [インテル® Xeon Phi™] を選択すると、次のようにオレンジ色のボックスで示す個所が変化します。
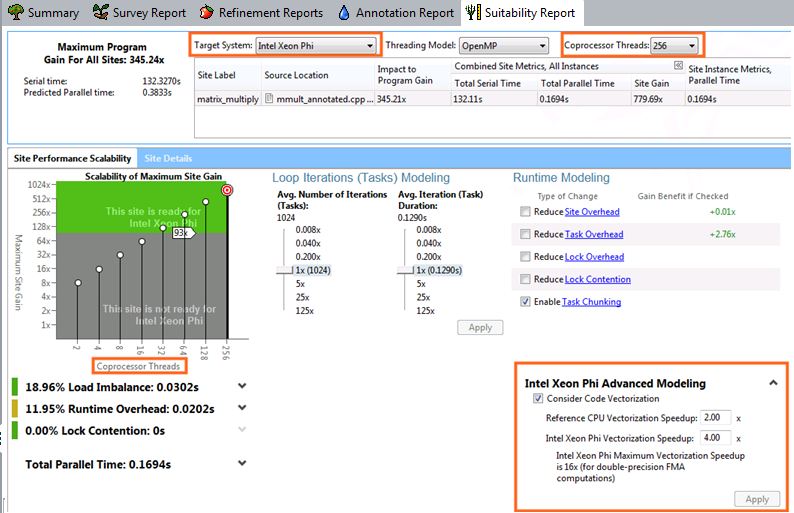
[すべてのサイトの最大プログラムゲイン] や、シリアルおよび予測並列時間などのデータが更新されます。
グラフが灰色-緑色表示に変更され、X 軸は [CPU Count (CPU 数)] の代わりに [Coprocesser Threads (コプロセッサーのスレッド)] になります。このグラフは、インテル® Xeon Phi™ コプロセッサーのコアとホスト CPU の間のデータ転送をカウントしない、メニーコア並列コプロセッサーの予測並列パフォーマンスを示します。多くのアプリケーションでは、タスク・インスタンス数はメニーコア並列コプロセッサーを完全に利用するようにはスケールしません。図形をホバーするとヒントが示されます。インテル® Xeon Phi™ プロセッサーへのオフロードに適していないアプリケーションは、グラフの灰色の領域に値が表示されます。この場合、[ターゲットシステム] でほかのモデル化タイプを検討してください。
グラフの灰色と緑色の間のラインはリファレンス・ベースラインであり、インテル® Xeon® プロセッサーのピーク・ベースラインを計算するために使用されたリファレンス・プロセッサーは、デュアルソケット 8 コアのインテル® Xeon® プロセッサー E5-26xx 製品ファミリー (2.70GHz、合計 16 コア) です。[Maximum Site Gain (最大サイトゲイン)] がこのベースラインを超えた場合、インテル® Xeon® プロセッサーまたは同等のプロセッサーの代わりに、インテル® Xeon Phi™ コプロセッサーの使用を検討してください。
[Target System (ターゲットシステム)] で [Intel Xeon Phi (インテル® Xeon Phi™)] または [Offload to Intel Xeon Phi (インテル® Xeon Phi™ へオフロード)] を選択した場合、[Intel Xeon Phi Advanced Modeling (インテル® Xeon Phi™ 製品向けの高度なモデル化)] オプションが表示されます。インテル® Xeon Phi™ 製品向けの高度なモデル化をご覧ください。
[ターゲットシステム] が [インテル® Xeon Phi™ へのオフロード] である場合に表示されるデータとモデル化パラメーター
[Target System (ターゲットシステム)] が [CPU] の代わりに [Offload to Intel Xeon Phi (インテル® Xeon Phi™ へオフロード)] を選択し、[Offload to Intel Xeon Phi (インテル® Xeon Phi™へオフロード)] カラムのチェックボックスをオンにすると、次のようにオレンジ色のボックスで示す個所が変化します。
![[ターゲットシステム] で [インテル® Xeon Phi™ へオフロード] を選択した場合](GUID-B2213DE7-A3A2-41A7-B6B4-A24F37869966-low.jpg)
[Target System (ターゲットシステム)] で [Offload to Intel Xeon Phi (インテル® Xeon Phi™ コプロセッサーへオフロード)] を選択した場合:
[Maximum Program Gain for All Sites (すべてのサイトの最大プログラムゲイン)] や、シリアルおよび予測並列時間などのデータが更新されます。
それぞれのサイトに [Offload to Intel Xeon Phi (インテル® Xeon Phi™ へオフロード)] という名前の追加のモデル化パラメーターが新しいカラムとして表示されます。このチェックボックスをオンにすると、[Scalability of Maximum Site Gain (最大サイトゲインのスケーラビリティー)] グラフの X 軸が [Coprocessor Threads (コプロセッサー・スレッド数)] になります。オフにすると、グラフの X 軸は [CPU Count (CPU 数)] になります。
右上の角に、追加のモデル化パラメーターが表示されます。並列実行の予測では、CPU 数とコプロセッサーのハードウェア・スレッド数の両方を考慮する必要があるため、[Coprocessor Threads (コプロセッサー・スレッド数)] の合計と [CPU Count (CPU 数)] の両方が表示されます。
[Runtime Modeling (ランタイムのモデル化)] の下の [Intel Xeon Phi Advanced Modeling (インテル® Xeon Phi™ 製品向けの高度なモデル化)] に追加のモデル化パラメーターが表示されます。インテル® Xeon Phi™ 製品向けの高度なモデル化を参照してください。
[Offload to Intel Xeon Phi (インテル® Xeon Phi™ へオフロード)] カラムのチェックボックスをオンにすると、グラフは灰色-緑色表示に変更され、X 軸は [CPU Count (CPU 数)] の代わりに [Coprocessor Threads (コプロセッサー・スレッド数)] になります。このグラフは、メニーコアのインテル® Xeon Phi™ コプロセッサーの予測性能を表します。多くのアプリケーションでは、タスク・インスタンス数はメニーコア並列コプロセッサーを完全に利用するようにはスケールしません。図形をホバーするとヒントが示されます。インテル® Xeon Phi™ コプロセッサーへのオフロードに適していないアプリケーションは、グラフの灰色の領域に値が表示されます。その場合、[Target System (ターゲットシステム)] でほかのモデル化タイプを試してください。インテル® Xeon Phi™ コプロセッサーへのオフロードに適したアプリケーションでは、値はグラフの緑色の領域に表示されます。
グラフの灰色と緑色の間のラインはリファレンス・ベースラインであり、インテル® Xeon® プロセッサーのピーク・ベースラインを計算するために使用されたリファレンス・プロセッサーは、デュアルソケット 8 コアのインテル® Xeon® プロセッサー E5-26xx 製品ファミリー (2.70GHz、合計 16 コア) です。[Maximum Site Gain (最大サイトゲイン)] がこのベースラインを超えた場合、インテル® Xeon® プロセッサーまたは同等のプロセッサーの代わりに、インテル® Xeon Phi™ コプロセッサーの使用を検討してください。
[サイト詳細] タブ
[Target System (ターゲットシステム)] で [CPU] を選択し、[Site Details (サイトの詳細)] タブ ([Site Performance Scalability (サイト・パフォーマンスのスケーラビリティー)] の隣) をクリックすると、スータビリティー・レポートの下部には、選択したサイトの詳細に加えて、サイト内のそれぞれのタスクとロックの詳細が表示されます。