 インテル® GPA
インテル® GPA インテル Parallel Universe 39 号日本語版の公開
インテル Parallel Universe マガジンの最新号が公開されました。 注目記事: インテル® oneAPI を使用したヘテロジニアス・プログラミング 掲載記事 インテル® FPGA 上での圧縮の高速化 ゲームが GPU 依存では...
 インテル® GPA
インテル® GPA 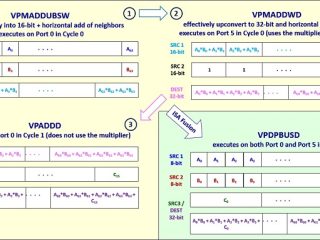 マシンラーニング
マシンラーニング  AI
AI  その他
その他  HPC
HPC 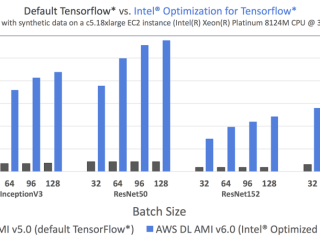 インテル® oneMKL
インテル® oneMKL  インテル® Parallel Studio XE
インテル® Parallel Studio XE 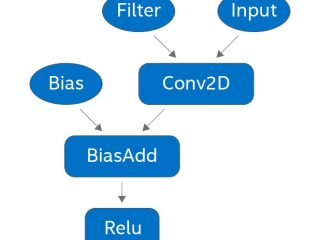 インテル® oneMKL
インテル® oneMKL 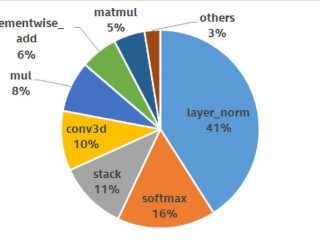 インテル® oneMKL
インテル® oneMKL 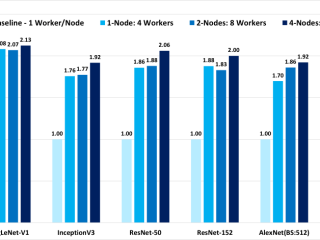 マシンラーニング
マシンラーニング  イメージ
イメージ  その他
その他  マシンラーニング
マシンラーニング  インテル® Parallel Studio XE
インテル® Parallel Studio XE 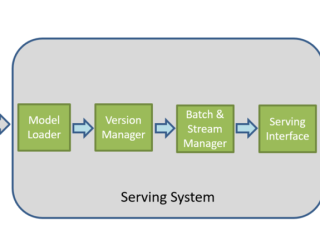 AI
AI 