
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Analyze a SYCL Application with GPU Roofline」(https://www.intel.com/content/www/us/en/develop/documentation/advisor-cookbook/top/use-cli-to-analyze-dpcpp-with-gpu-roofline.html) の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピでは、インテル® Advisor のコマンドライン・インターフェイス (CLI) を使用して、GPU 上で実行されるマンデルブロ・アプリケーションの SYCL* 実装で GPU Roofline Insights パースペクティブを実行し、コマンドライン出力、Python* API、グラフィカル・ユーザー・インターフェイス (GUI) およびインタラクティブな HTML レポートにより結果を視覚化する方法を紹介します。
インテル® Advisor の GPU Roofline Insights 機能は、SYCL*、OpenMP* ターゲットを含む C++/Fortran、インテル® oneAPI レベルゼロ API (レベルゼロ)、および OpenCL* アプリケーションの GPU カーネルのパフォーマンスを評価して最適化するのに役立ちます。GPU Roofline Insights パースペクティブを使用して、以下を行うことができます。
- GPU 上で実行されるコードを評価し、ハードウェアの上限にどれだけ近いパフォーマンスが得られるかを確認します。
- ボトルネックを検出して、予測されるパフォーマンス・ゲインで優先順位を付けて、メモリー依存や計算依存などの可能性のある原因を理解します。
- ボトルネックの原因である計算ピークやメモリー階層 (キャッシュ、メモリー、または計算スループット) をピンポイントで特定します。
- 最も効果的な最適化を特定し、アプリケーション固有の実行可能なコード再構成の推奨事項を適用します。
- 最適化の進捗状況を可視化し、1 つのルーフライン・グラフ上に描画された異なるコードバージョンを比較します。
手順:
- 必要条件
- GPU Roofline Insights パースペクティブの実行
- GPU ルーフライン結果の表示
- GPU 上でのアプリケーション・パフォーマンスの検証
- インテル® Advisor の Python* API による GPU メトリックの調査
- 別の方法
コンポーネント
ここでは、このレシピで示す結果を得るために使用したハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2021
スタンドアロン版 (英語) またはインテル® oneAPI ベース・ツールキットの一部としてダウンロードできます。 - アプリケーション: マンデルブロ (英語) は、行列の初期化によってフラクタル画像を生成し、ピクセルに依存しない計算を実行する SYCL* アプリケーションです。
- コンパイラー: インテル® oneAPI DPC++/C++ コンパイラー 2021
インテル® oneAPI ベース・ツールキットの一部としてダウンロードできます。 - オペレーティング・システム: Ubuntu* 20.04.2 LTS
- CPU: インテル® Core™ i7-8559U プロセッサー
- GPU: インテル® Iris® Plus グラフィックス 655
SYCL* マンデルブロ・アプリケーションの事前収集された GPU ルーフライン・レポートをダウンロード (英語) し、このレシピの手順に従って解析結果を調べることもできます。
必要条件
- 環境を設定します。以下に例を示します。
source /opt/intel/oneapi/setvars.sh - サンプル・アプリケーションをコンパイルします。
cd mandelbrot/ && mkdir build && cd build && cmake .. && make - GPU カーネルを解析するため、システムを設定 (英語) します。
GPU Roofline Insights パースペクティブの実行
GPU ルーフライン・データを収集するには、次のコマンドを実行します。
advisor --collect=roofline --profile-gpu --project-dir=./adv_gpu_roofline -- ./src/mandelbrotコマンドを実行すると、インテル® Advisor はアプリケーションの GPU カーネルと CPU ループ/関数の両方のデータを収集して、ルーフライン・グラフに描画します。
次のいずれかの方法で収集したデータを表示します。
注:
MPI アプリケーション (英語) や、特定のアプリケーション領域の浮動小数点/整数演算やトリップカウント・データを収集制御 API (英語) のみで収集するなど、制約のあるアプリケーションを解析する場合、別途 Survey コマンドと Characterization コマンドを実行する必要があります。ショートカット・コマンドはそのようなアプリケーションをサポートしていません。詳細は、「コマンドラインから GPU Roofline Insights パースペクティブを実行」 (英語) を参照してください。
GPU ルーフライン結果の表示
インテル® Advisor は、--project-dir オプションで指定した adv_gpu_roofline ディレクトリーに解析設定と解析結果を保存します。収集結果はいくつかの出力形式で可視化できます。
CLI で結果を表示
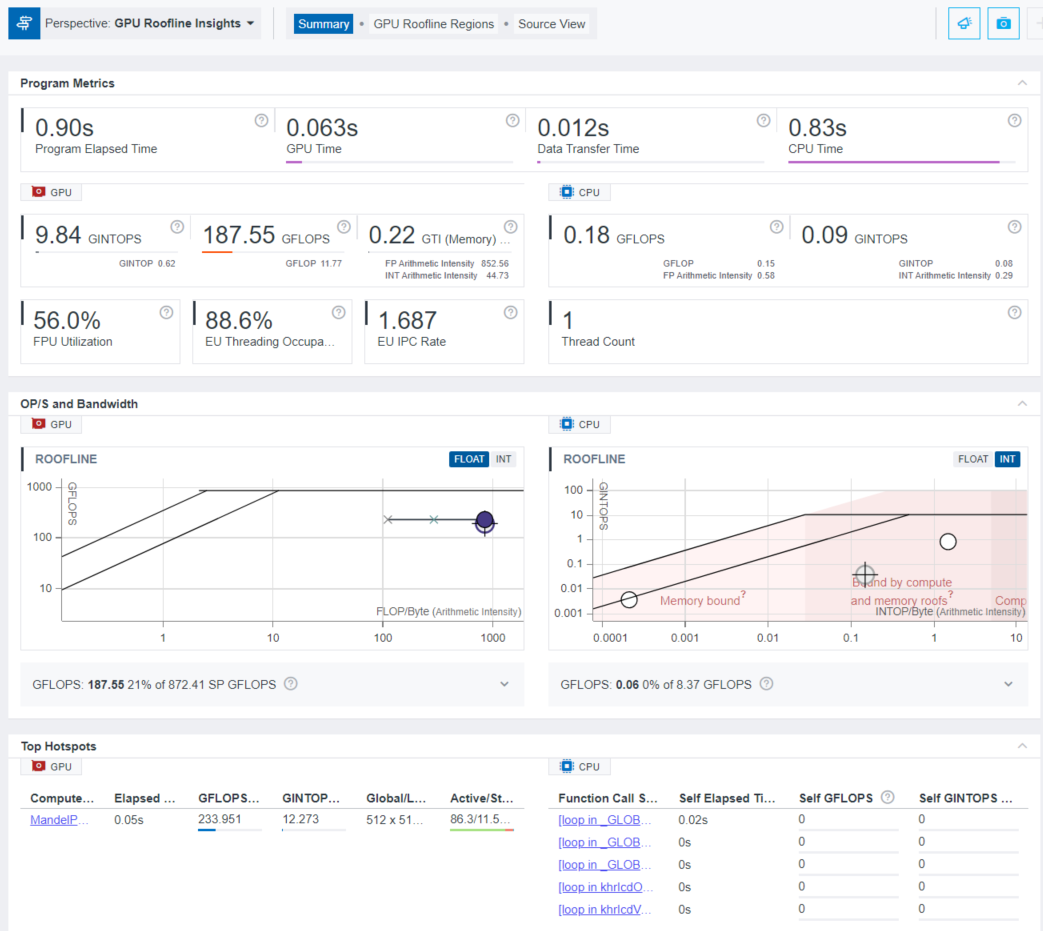
コマンドを実行すると、結果のサマリーがターミナルに出力されます。これには、アプリケーション全体と、CPU および GPU 部分に関するメトリックの概要が含まれています。上位の GPU ホットスポットに関する情報の表が表示され、各 GPU ホットスポットの実行時間、1 秒あたりの操作数、呼び出し回数、実行ユニット関連のメトリックを確認できます。
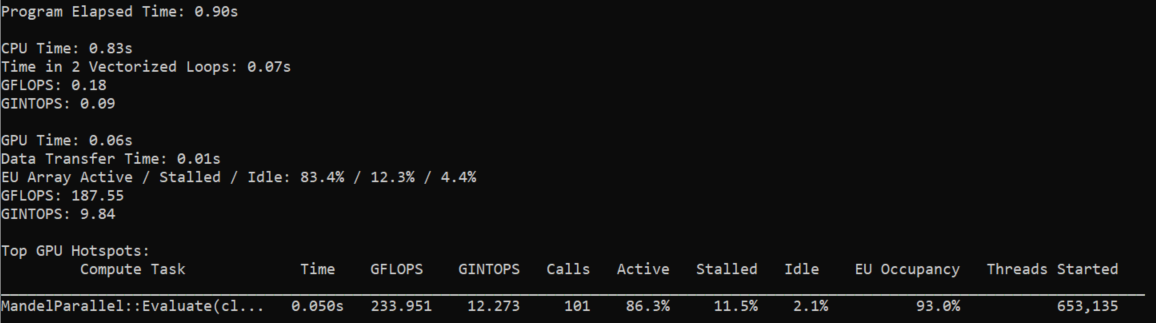
すべての GPU ホットスポットのメトリックを表示するには、次のように --gpu を指定して report コマンドを実行します。
advisor --report=survey --gpu --project-dir=./adv_gpu_roofline
表示するデータ列を増やすには、--show-all-columns オプションを追加します。
advisor --report=survey --gpu --show-all-columns --project-dir=./adv_gpu_roofline結果をインタラクティブな HTML レポートとしてエクスポート
ウェブブラウザーで共有および表示可能なインタラクティブな HTML レポートを生成できます。
advisor --report=all --project-dir=./adv_gpu_roofline --report-output=./gpu_roofline_report.htmlこのコマンドは、GUI と同様の構成で結果を表示するインタラクティブな HTML レポートを作成します。インタラクティブな HTML レポートでは、GPU メトリックがグリッド表示され、ルーフライン・グラフに描画されます。ルーフライン・グラフは、adv_gpu_roofline 結果で利用可能な浮動小数点演算、整数演算、およびすべてのメモリー階層のデータを表示します。
GUI で結果を表示
結果を表示する最も簡単な方法は、結果を収集したマシンにインテル® Advisor の GUI がインストールされている場合、同じマシンで結果を開くことです。この場合、追加のファイルやレポートを作成することなく、既存のインテル® Advisor の結果を開くことができます。
GUI で結果を開くには、次のコマンドを実行します。
advisor-gui ./adv_gpu_roofline注:
レポートが開かない場合、[Welcome] ページで [Show Result] をクリックするか、インテル® Advisor の GUI でメニューから [File] > [Open] > [Project] を選択します。
読み取り専用の結果スナップショットの保存 (HTML および GUI レポートの代用)
ターゲットマシンにインテル® Advisor の GUI がインストールされていない場合、結果を共有ドライブにコピーして別のマシンで開くか、クライアントマシンに直接コピーしてください。
ヒント:
読み取り専用のスナップショットを使用すると、コピーしたファイルのサイズを小さくできます。
スナップショットを作成して、ソースとバイナリーを含むアーカイブにパックするには、次のコマンドを実行します。
advisor --snapshot --project-dir=./adv_gpu_roofline --pack --cache-sources --cache-binaries -- ./my_snapshotmy_snapshot.advixeexpz という名前のスナップショットのアーカイブが、--project-dir オプションで指定したadv_gpu_roofline ディレクトリーに保存されます。
インテル® Advisor の GUI で結果スナップショットを開くには、次のコマンドを実行します。
advisor-gui ./my_snapshotインテル® Advisor の GUI でメニューから [File] > [Open] > [Result] を選択してスナップショットを開くことができます。
ヒント:
macOS* で収集結果を GUI で表示するには、インテル® Advisor (macOS* 版) (英語) をダウンロードします。
snapshot コマンドの詳細は、ユーザーガイド (英語) を参照してください。
GPU 上のアプリケーション・パフォーマンスの検証
デフォルトでは、インテル® Advisor は [Summary] タブを表示します。これには、アプリケーション全体と、GPU および CPU 部分に関する一般的なメトリックが含まれます。また、アプリケーションのプレビュー・ルーフライン・グラフを調べることもできます。
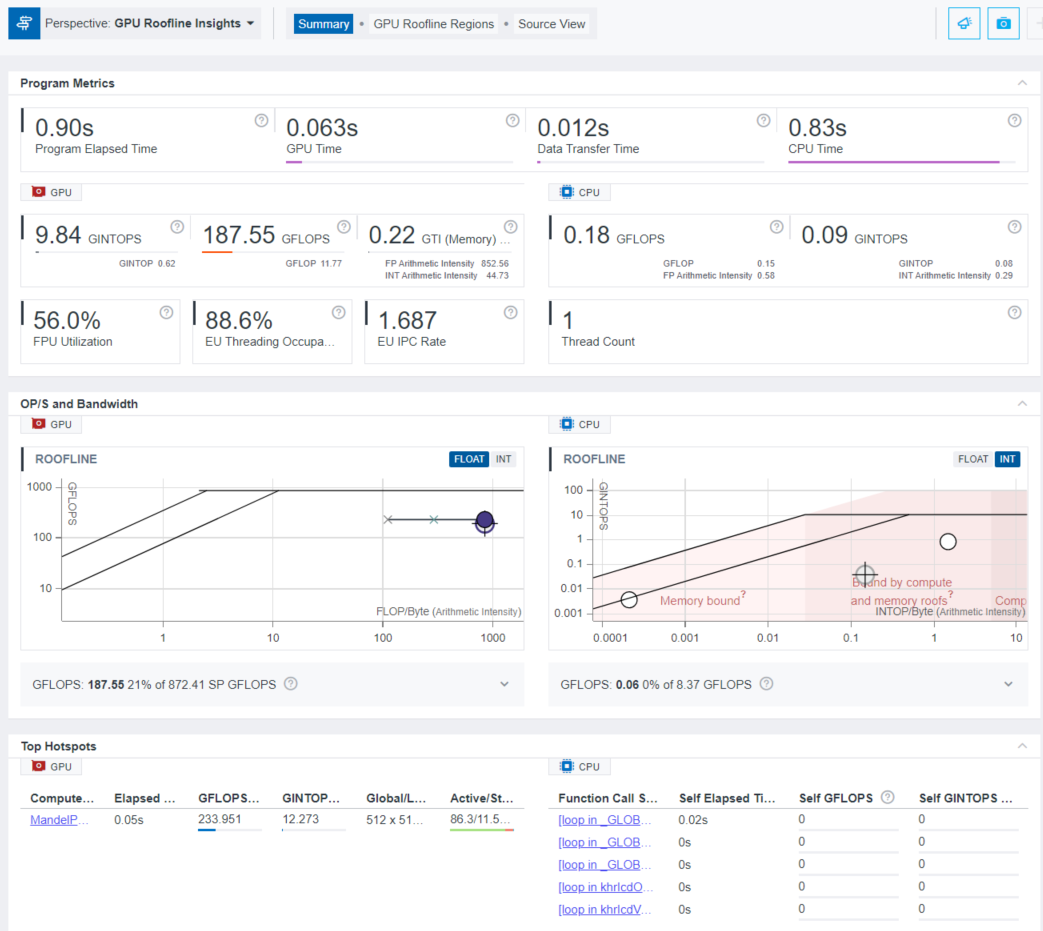
カーネルごとの詳細なビューを表示するには、[Top Hotspots] ペインで計算タスクをクリックするか、[GPU Roofline Regions] タブをクリックします。このタブでは、左側に GPU ルーフライン・グラフ、右側に選択したカーネルの詳細な概要とその GPU ソースおよびアセンブリー・ビューが表示されます。[GPU Roofline Regions] タブの下部にある [GPU] ペインには、カーネルのリストと関連する生の収集データ (メモリー関連データ、EU アクティブ/インストール/アイドルデータ、EU スレッド占有率、スレッド数など) がグリッド表示されます。詳細は、「GPU ルーフライン・グラフでのボトルネックの検証」 (英語) を参照してください。
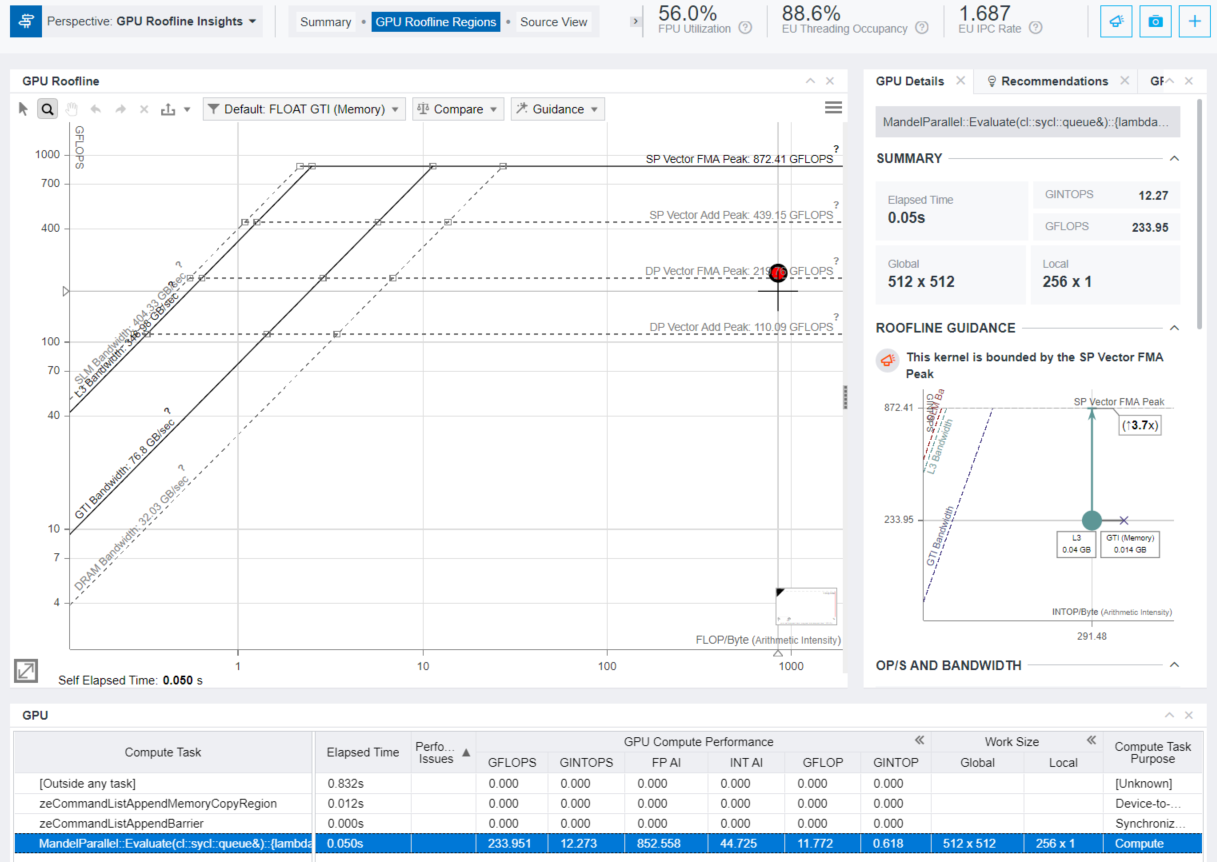
[GPU] テーブルで注目する計算タスクを右クリックして [View Source] を選択するか、[Source View] タブをクリックします。ソースと対応するアセンブリー・コードが表示されます。

インテル® Advisor の Python* API を使用した GPU メトリックの調査
CLI で収集した GPU ルーフライン結果を視覚化するには、/opt/intel/oneapi/advisor/latest/pythonapi/examples の Python* スクリプトを使用します。このスクリプトは、インテル® Advisor の Python* API を使用して生のメトリックを表示し、ユーザーのカスタムスクリプトで後処理を行うことができます。以下の例を参照してください。
注: /opt/intel/oneapi/ は、デフォルトのインテル® Advisor のインストール・ディレクトリーです。インテル® Advisor を別の場所にインストールした場合は、その場所に置き換えてください。
GPU ルーフ値の出力
gpu_roofs.py サンプルスクリプトを実行して、GPU ルーフライン収集中に測定された GPU 値を確認します。
advisor-python /opt/intel/oneapi/advisor/latest/pythonapi/examples/gpu_roofs.py ./adv_gpu_rooflineターミナルに次のような GPU ルーフのリストが出力されます。
DP Vector FMA Peak 219 GFLOPS DP Vector Add Peak 110 GFLOPS SP Vector FMA Peak 872 GFLOPS SP Vector Add Peak 439 GFLOPS Int64 Vector Add Peak 110 GFLOPS Int32 Vector Add Peak 438 GFLOPS Int16 Vector Add Peak 873 GFLOPS Int8 Vector Add Peak 432 GFLOPS SLM Bandwidth 404 GB/s L3 Bandwidth 346 GB/s DRAM Bandwidth 32 GB/s GTI Bandwidth 76 GB/s
カーネルごとのメトリックの表示
survey_gpu.py サンプルスクリプトを実行して、事前に収集した GPU プロファイルから各カーネルの詳細なメトリック (カーネルの命令ミックスなど) を表示します。
advisor-python /opt/intel/oneapi/advisor/latest/pythonapi/examples/survey_gpu.py ./adv_gpu_rooflineターミナルに次のような GPU メトリックのリストが出力されます。
============================================================
Main GPU Dataset
============================================================
…
============================================================
…
carm_l3_cache_line_utilization_______________: 1
carm_slm_cache_line_utilization______________: 0
carm_traffic_gb______________________________: 0.105906
computing_task_______________________________: MandelParallel::Evaluate(cl::sycl::queue&)::{lambda(cl::sycl::handler&)@235:14}::operator()(cl::sycl::handler&) const::{lambda()@240:44}
computing_task_average_time__________________: 0.000498183
…
elapsed_time_________________________________: 0.0503165
…
gpu_compute_performance_fp_ai________________: 852.558
gpu_compute_performance_gflop________________: 11.7716
gpu_compute_performance_gflops_______________: 233.951
gpu_compute_performance_gintop_______________: 0.617538
gpu_compute_performance_gintops______________: 12.2731
gpu_compute_performance_gmixop_______________: 12.3891
gpu_compute_performance_gmixops______________: 246.224
gpu_compute_performance_int_ai_______________: 44.7253
gpu_compute_performance_mix_ai_______________: 897.283
gpu_memory_bandwidth_gb_sec__________________: 0.27441
gpu_memory_bandwidth_gb_sec_read_____________: 0.233971
gpu_memory_bandwidth_gb_sec_write____________: 0.0404391
gpu_memory_data_transferred_gb_______________: 0.0138074
gpu_memory_data_transferred_gb_read__________: 0.0117726
gpu_memory_data_transferred_gb_write_________: 0.00203475
…
work_size_global_____________________________: 512 x 512
work_size_local______________________________: 256 x 1
============================================================
Instruction Mix Dataset
============================================================
zeCommandListAppendMemoryCopyRegion: 0
============================================================
zeCommandListAppendBarrier: 2
============================================================
MandelParallel::Evaluate(cl::sycl::queue&)::{lambda(cl::sycl::handler&)@235:14}::operator()(cl::sycl::handler&) const::{lambda()@240:44}: 1
Type: Size: Op Type : Callcount : Exec Count : Dynamic Count
INT : 32 : MOVE : 104,403,397 : 1,488,428,112 : 1,351,879,647
INT : 32 : BIT : 3,309,568 : 28,131,328 : 28,131,328
INT : 32 : BASIC : 190,604,170 : 509,977,482 : 509,977,482
: : OTHER : 165,063,391 : 2,641,014,256 : 2,505,733,341
: : CONTROL : 335,418,273 : 4,110,086,021 : 2,400,317,722
FP : 32 : MOVE : 13,238,272 : 112,525,312 : 112,525,312
FP : 32 : MATH : 3,309,568 : 3,309,568 : 3,309,568
FP : 32 : BASIC : 165,999,156 : 2,655,986,496 : 2,385,424,666
FP : 32 : FMA : 327,033,960 : 5,232,543,360 : 4,691,419,700
INT : 64 : BASIC : 3,309,568 : 26,476,544 : 26,476,544
INT : 32 : FMA : 3,309,568 : 26,476,544 : 26,476,544
INT : 16 : STORE : 1,654,784 : 26,476,544 : 26,476,544
============================================================
別の方法
(デフォルト設定の代わりに) 複数の GPU を搭載したシステムでの GPU Roofline Insights パースペクティブの実行
システムに複数の GPU デバイス (例えば、統合 GPU とディスクリート GPU、または複数のディスクリート GPU) が搭載されている場合、プロファイル・データを収集するターゲット GPU を指定します。
- システムで利用可能な GPU デバイスのリストを取得します。
次の形式でデバイス構成が表示されます:advisor --help target-gpu<domain>:<bus>:<device-number>.<function-number>。 - 解析するデバイス構成をコピーします。例:
0:0:2.0。 - ターミナルに次のコマンドを入力し、
--target-gpuオプションでコピーしたデバイス構成を引数として指定し、解析対象の GPU を選択します。advisor --collect=roofline --profile-gpu --target-gpu=0:0:2.0 --project-dir=./adv_gpu_roofline -- ./src/mandelbrot - コマンドを実行します。
(デフォルト設定の代わりに) 実行時間の短い GPU Roofline Insights パースペクティブの実行
サンプリング間隔に対するカーネル時間の比率を下げると精度が低下します。最高の精度を達成するため、以下の条件を満たしていることを確認します。
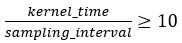
実行時間の短いカーネルで不正確なメトリックを回避するには、--gpu-sampling-interval=<double> オプションを使用して GPU サンプリング間隔 (ミリ秒単位) を短くします。
advisor --collect=roofline --profile-gpu --gpu-sampling-interval=0.1 --project-dir=./adv_gpu_roofline -- ./src/mandelbrot