

この記事は、インテルの The Parallel Universe Magazine 24 号に収録されている、コードのベクトル化に関する章を抜粋翻訳したものです。
多くの要因がプログラムの自動ベクトル化を妨げます。この記事では、コンパイラーによるヒントがないとコードのベクトル化が困難である要因について検証します。ループのベクトル化は、アプリケーションのパフォーマンスを向上するために重要です。インテル® Advisor XE は、ベクトル化のプロセスをガイドします。
インテル® Advisor XE 2016 は、ベクトル化アドバイザーを含む動的な解析ツールです (図 1)。ベクトル化アドバイザーを利用することで、アプリケーションに含まれるすべてのループを調査し、次のことを確認できます。
- ベクトル化されたループとされなかったループ
- ループがベクトル化されなかった原因
- ベクトル化されたループのスピードアップとベクトル化の効率
- ベクトル化の効率を下げている要因
- メモリーレイアウトにより制約を受けているベクトル化されたループとされなかったループ
この記事では、ベクトル化アドバイザーの概要を提供し、次世代のインテル® Xeon Phi™ 製品 (開発コード名 Knights Landing) 上でのベクトル化を支援する新しい機能を紹介します。また、ベクトル化アドバイザーを利用して一般的な問題をベクトル化する方法を示します。
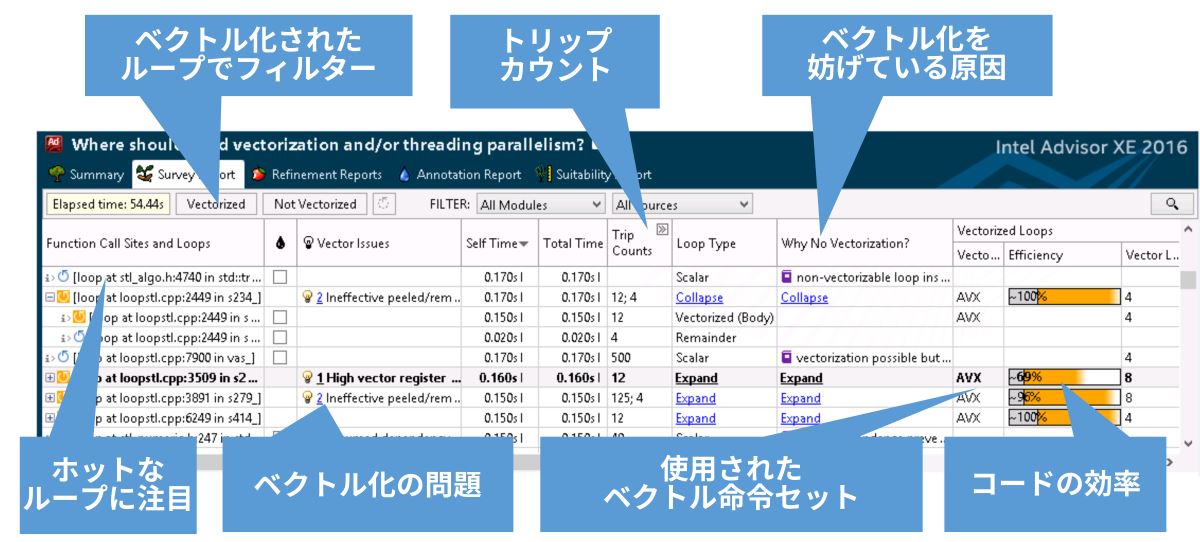
図 1. ベクトル化アドバイザー: 必要なすべてのデータに簡単にアクセス
ベクトル化の効率を向上するための 5 つのステップ
- 調査。最初のステップでは、アプリケーションを調査します。このステップで、アプリケーションが時間を費やしているループが分かります。「ホットな」ループは、最適化による恩恵が最も得られる場所です。図 2 は、アプリケーションの [Survey Report (調査レポート)] です。インテル® Advisor XE では、ループの種類 (ベクトル化されているかどうか) でフィルターすることができます。ベクトル化されなかったループには、ベクトル化を妨げている原因が表示されます。
- 推奨事項の確認。ベクトル化の効率を向上する方法について具体的なアドバイスが得られます。また、ベクトル化を妨げている原因も表示されます。
- トリップカウント。ループ反復のトリップカウントを個別の収集ステップとして収集します。ループがホットかどうかだけでなく、トリップカウントも把握することが重要です。トリップカウントが小さい場合、効率良くベクトル化するのに十分な反復がない可能性があります。トリップカウントがベクトル長の倍数かどうか確認することで、剰余ループが必要かどうか知ることもできます。
- 依存性解析。コードが正しい結果を生成するように、コンパイラーは、コンパイルしている言語のセマンティクスに対して保守的な見地に立たなければいけません。言語の規則に基づいて依存性が想定される場合、コンパイラーは依存性が存在すると仮定します。インテル® Advisor XE のような動的なツールを使用することにより、仮定した依存性が事実かどうか確認することができます。
- メモリー・アクセス・パターン (MAP) 解析。データ構造がメモリー上にどのように配置され、ループでどのようにアクセスされるか知っていれば、アプリケーションのベクトル化の効率を大幅に引き上げることができます。メモリー参照がユニットストライド方式でアライメントされていることは非常に重要です。構造体配列 (AOS) から配列構造体 (SOA) へのデータ構造の変換のように、ベクトル化を支援するメモリーアクセス関連の手法があります。MAP 解析を使用すると、本質的にベクトル化が非効率なパターンを見つけ出すことができます。
続きはこちら (PDF) からご覧いただけます。
