
この記事は、インテル® デベロッパー・ゾーンに公開されている「Superior Performance Commits Kyoto University to CPUs Over GPUs」(https://software.intel.com/en-us/articles/superior-performance-commits-kyoto-university-to-cpus-over-gpus) の日本語参考訳です。
京都大学大学院医学部では、Theano フレームワークを使用した創薬計算におけるニューラル・ネットワークのディープラーニングのトレーニングを行う際に、デュアルソケットのインテル® Xeon® プロセッサー E5-2699 V3 (開発コード名 Haswell アーキテクチャー) ベースのシステムが NVIDIA* K40 GPU よりも優れたパフォーマンスを提供することを検証しました。Theano は、研究者が透過的にディープラーニング・モデルを CPU と GPU 上で実行できる Python* ライブラリーです。Theano は、Python* スクリプトから対象とするアーキテクチャー向けの C++ コードを生成します。生成された C++ コードは、最適化された数学ライブラリーを呼び出すこともできます。
京都大学のチームは、オープンソースの Theano C++ マルチコアコードのパフォーマンスが大幅に向上することを確認しました。彼らは、その時点で次世代のインテル® Xeon Phi™ プロセッサーがまだ利用できなかったため、デュアルソケットのインテル® Xeon® プロセッサー・ベースのシステムを使用して Theano のマルチコア・パフォーマンスを改善するため、インテルと協業しました。最適化によりパフォーマンスが大幅に向上し、ディープラーニング・タスク1 でデュアルソケットの Haswell (開発コード名) プロセッサー・チップセットが NVIDIA* K40 GPU より優れていることを実証しました。
バイオインフォマティクス学会の 2015 年次の会議 (JSBI 2015) で、浜中雅俊 (フェロー研究員) 氏によって提示されたインテル® Xeon® プロセッサーのベンチマーク結果とマルチコアとメニーコアの実行環境の一貫性に基づき、GPU はディープラーニングにおける利点を提供せず、無駄なコスト、複雑性、そしてメモリーの制限が生じることから考慮から除外しました。
プレゼンテーション資料から要約スライドを抜粋したものを以下に示します。

図 2: 最適化された Theano の GPU との相対的なスピードアップとインテル® Xeon® プロセッサー・ベースのシステムの大きなメモリー容量の影響。(結果は京都大学から提供されました)
京都大学によるディープラーニング・クラスターの調達は、GPU テクノロジーと比較しメニーコア CPU を選択する、最初のシステムの先導的存在です。Theano ソフトウェアは、次世代インテル® Xeon Phi™ プロセッサー上ではるかに高速で実行されることが期待されます。
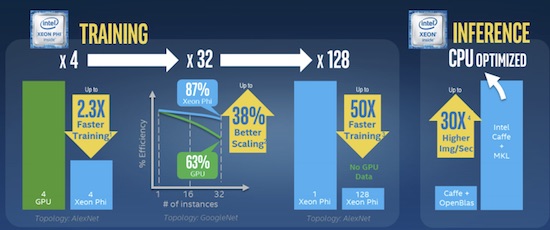
図 3: ISC’ 16 で、インテルはディープラーニング向けに GPU と比較したインテル® Xeon Phi™ プロセッサーの優れたパフォーマンスの詳細を示しました。
科学的重要性
京都大学大学院医学部では、創薬、医療、およびヘルスケアなどの生命科学の問題向けに、さまざまなマシンラーニングとディープラーニング・アルゴリズムを導入しています。他の分野と同様に、京都大学の研究者も膨大な量のデータに直面しています。例えば、京都大学のチームは、ハイスループット・スクリーニング (HTS) と次世代シーケンシング (NGS) などの実験技術によって生成されたデータに対して、マシンラーニングを適用することを望んでいます。また、日常の診察から電子カルテ (EHR) を分析することができます。京都大学のチームは、ビックデータ・マシンラーニング技術を利用することで、従来の手法に比べさらに多くの詳細な分析が可能であると考えています。
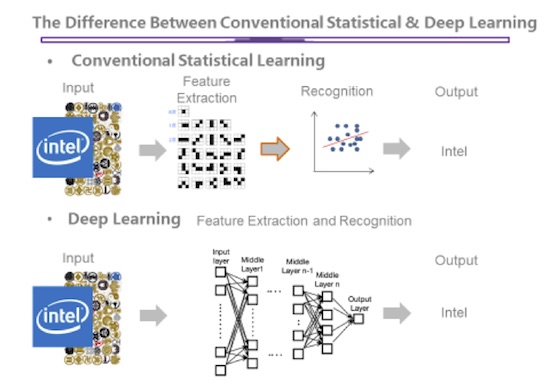
図 4: ディープラーニングと従来のアプローチの違いを示すイラスト。(イメージは京都大学から提供されました)
京都大学では、マシンラーニングとディープラーニングの研究で 2 つの目標を持っています: (1) 患者のベッドサイドにおける実験や収集された電子データから生成される膨大な量のデータから知識発見を行い、(2) 実験者と医師の知的発見から関連する情報をフィードバックすることで、創薬および患者のヘルスケアを向上させます。
奥野恭史教授は、「今後 10 年で多くの臨床応用は、マシンラーニングを採用するでしょう。マシンラーニングとディープラーニングの応用は、今後 10 年でますます重要になります。」と語っています。
京都大学における創薬ワークロード
京都大学のワークロードの一部は、創薬分野で計算による仮想スクリーニングを適用しています。仮想スクリーニングは、創薬プロセスの初期段階で使用され、このプロセスは通常は 10 年以上かかります。仮想スクリーニングの目的は、新薬の候補を見つけるため、膨大な数の科学物質を計算によりスクリーニングすることです。
奥野教授は、「現在、創薬の初期段階には数年の年月と数億ドルのコストがかかります。しかし、我々の研究により、時間とコストの両方を大幅に減少できると確信しています。」と語っています。
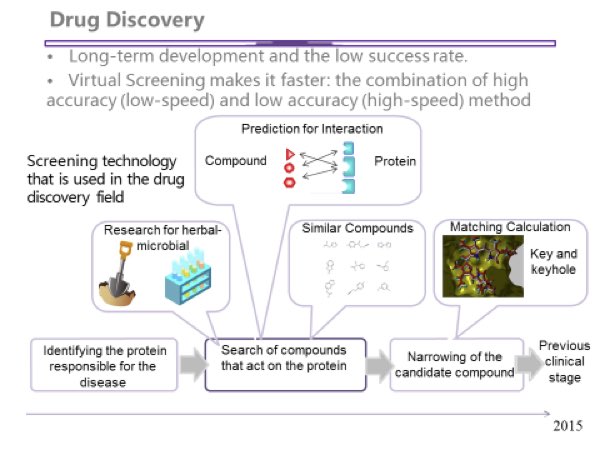
図 5: 仮想創薬向けのケースでは、速度と量が重要になります。(イメージは京都大学から提供されました)
「DBN はデータから学習するため、既存薬の化合物構造に類似しない薬剤候補を見つけることができる可能性があります。このような理由から、我々は、ディープラーニングが新たな薬剤候補を見つけるのに役立つと考えています。」と、奥野教授は続けました。
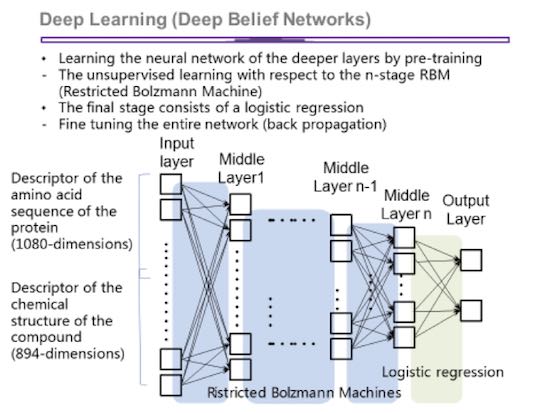
図 6: DBN は、薬剤様活性に重要なデータの特徴を ‘学習’ できます。そして、薬剤候補を予測、またはスコアを求めるため、DBN を利用できます。(イメージは京都大学から提供されました)
ビッグデータは、複雑な問題を解決するニューラル・ネットワークを高い精度でトレーニングするための鍵です (Alan Lapedes と Robert Farber の論文「How Neural Networks Work」 (https://papers.nips.cc/paper/59-how-neural-nets-work.pdf (英語)) では、ニューラル・ネットワークは ‘凹凸’ のある多次元面を調和させるもので、そのためには学習データが表面の山と谷、もしくは変曲点を指定する必要があることを示しています。複雑な表面の調和にはより多くのデータが必要になるのは、このためです)。
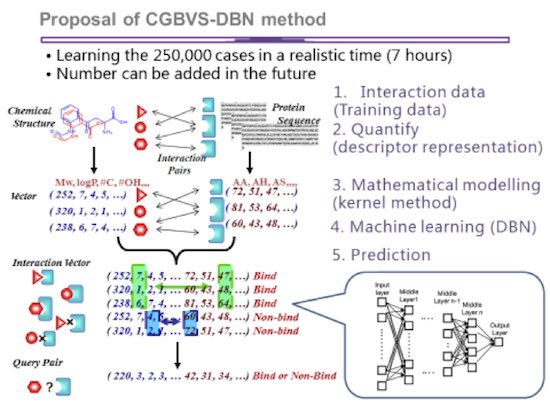
図 7: ディープラーニングを使用して薬剤候補を見つけるための方法 (イメージは京都大学から提供されました)
京都大学のデータセットでは、400 万行と 2,000 の機能に対する Theano のスケーリングの挙動を評価しました。結果は、20% のホールドアウト法を使用して評価されました。将来的には、京都大学のチームは、2 億行と 38 万の機能のデータセットをトレーニングするため Theano を使用する計画です – 130 倍のデータ増加!
「実験結果は日々増加しており、我々は常にコンピューティング・パフォーマンスを向上していかなければならないでしょう。」と、奥野教授は語っています。
以下に見られるように、最適化された Theano コードはデータセットのサイズ増加に対し優れたスケーリングを実現します。これにより、より多くのデータによるトレーニングが可能になります。新しいインテル® Xeon Phi™ プロセッサー・ベースのシステムも同様にスケールし、より速いタイムツーモデルのパフォーマンスを実現することを期待します。
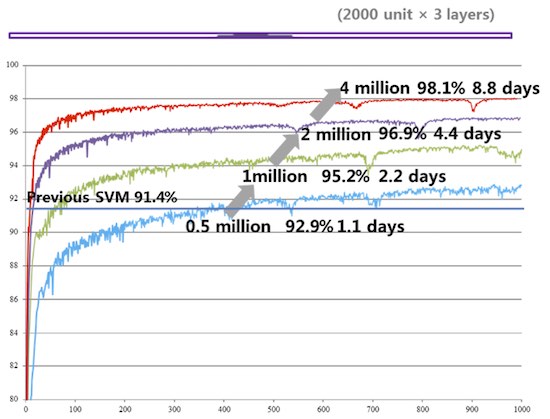
図 8: 最適化された DBN Theano コードのデータサイズに対するスケーリング。(イメージは京都大学から提供されました)
GPU コードパスに比べ不適切に最適化されたマルチコアコードを修正
京都大学が示した結果は、現代のマルチコア処理技術は GPU によるマシンラーニングのパフォーマンスを上回りますが、公正なベンチマークの比較を行うため同等に最適化されたソフトウェアが必要であることを示しています。歴史的背景により、すべてのオープンソースは GPU 向けのコードパスの最適化に労力が割かれ、Theano のような多くのソフトウェア・パッケージではマルチコア向けコードの最適化は欠如していました。
第三者が公正なベンチマークを実施することを支援し、マルチコアとメニーコアのパフォーマンスの利点を実現するため、インテルは、ISC’ 16 においてマシンラーニングとディープラーニング向けにいくつかのライブラリーを発表しました。代表的なものには、高レベルのインテル® Data Analytics Acceleration Library (インテル® DAAL) と、最適化されたディープラーニング・プリミティブを提供する低レベルのインテル® MKL-DNN があります。ISC’ 16 でのインテル® MKL-DNN の発表では、ライブラリーがオープンソースで、制限がなく、かつロイヤリティー・フリーであることにも言及しました。安定したインテル® マス・カーネル・ライブラリー (インテル® MKL) も、インテル® アーキテクチャー上でマシンラーニングとディープラーニングを高速化するため、最適化されたプリミティブの追加により、マシンラーニング向けに刷新されました。
例えば、SGEMM 操作はマシンラーニングにおいて重要なアルゴリズムですが、非常に重い単精度演算を行います。新しいライブラリーは、SGEMM の並列処理を改善します。
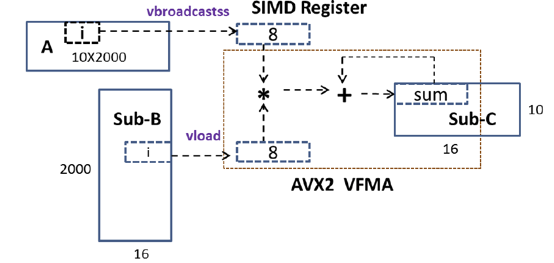
図 9: インテル® AVX 命令と連続したアドレスアクセスにより改善された SGEMM の並列処理。(イメージはインテルから提供されました)
ISC’ 16 で発表された、新しいベクトルおよびマルチコアに最適化されたライブラリーは、マシンラーニングへの取り組みを加速し、開発者や研究者を支援します。これはまさに、京都大学が、マシンラーニング向けにハードウェア・プラットフォームを評価する際に、最適化されたマルチコア向けのコードを使用して公正な比較を行ったようなことを支援します。
新しいインテル® Xeon Phi™ プロセッサー・ベースのシステムへの期待
京都大学学術情報メディアセンター (ACCMS) は、より大規模なデータセットでトレーニングをサポートするように設計された、新しいインテル® Xeon Phi™ プロセッサー・ベースのクラスターを立ち上げることを計画しています。具体的には、次のことが期待されます:
- 他の CPU と GPU プラットフォームに比べ、より大きなデータを短い時間でトレーニングできる高いパフォーマンスを提供する。
- 高度なアルゴリズムの開発を容易にする。多くのディープラーニングのアルゴリズムは複雑であるため、可能な限り多くのアーキテクチャー上の制約を排除する。複雑性、メモリーの制約、そして GPU 環境のハードウェアのバリエーションを排除することから、マルチコアとメニーコア・プログラミング環境の一貫性は非常に魅力的です。また、インテルは、インテル® Xeon® プロセッサーとインテル® Xeon Phi™ プロセッサーの機能を活用する、最適化ライブラリーを提供することに積極的であることが解っています。
マルチコア・プロセッサーが GPU をしのぐことを教育する人々
データ科学者と HPC コミュニティーがマルチコアとメニーコア向けのソフトウェアとハードウェア技術を理解するのを支援するため、インテルは、マシンラーニングのポータルサイト http://intel.com/machinelearning を開設しています。このポータルサイトで公開される情報は、マルチコアとメニーコア・プロセッサーで GPU を凌駕する方法を指導し、優れたトレーニングと予測 (推論やスコアリングとも呼ばれます) パフォーマンスに加えて、各種マシンラーニング・フレームワークにおいてより良いスケーラビリティーを提供します。このポータルサイトを通じて、インテルはマシンラーニング技術と最適化されたライブラリーの利点を 10 万人の開発者に伝えたいと考えています。インテルは、早期技術へのアクセスによって学術研究者を支援しています。
マシンラーニングや HPC コンピューティングのエクサスケール時代への対応を支援するため、インテルはインテル® スケーラブル・システム・フレームワーク (インテル® SSF) を作成しました。インテル® SSF は、インテル® Omni-Path アーキテクチャー (インテル® OPA)、3D XPoint™ テクノロジーで構築されたインテル® Optane™ SSD、そして新しいインテル® シリコン・フォトニクスを含む、ソフトウェアとハードウェア技術を組込み、さらにインテル® Xeon® プロセッサー、インテル® Xeon Phi™ プロセッサー、そしてインテル® Enterprise Edition for Lustre* software を含む、インテルの既存と今後登場する計算とストレージ製品で構成されます。
著者紹介: Rob Farber 氏は、HPC とマシンラーニング分野で広範な経歴を持つ世界的な技術コンサルタントおよび著作者で、その知識と経験を世界各地の国立研究所と商業団体に役立てています。著者には、info@techenablement.com からコンタクトできます。
1開発コード名 Broadwell マイクロアーキテクチャーによる改善 – 特に FMA (Fused Multiply-Add) 命令 – は、さらにパフォーマンスを向上させます。詳細は、http://www.nextplatform.com/2016/03/31/examining-potential-hpc-benefits-new-intel-xeon-processors (英語) をご覧ください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
