

この記事は、インテルの The Parallel Universe Magazine 26 号に収録されている、インテル® DAAL と最新のインテル® Xeon Phi™ プロセッサーにより成果を上げる方法に関する章を抜粋翻訳したものです。
データ・サイエンティストは、最新のインテル® Xeon Phi™ プロセッサー x200 ファミリー (開発コード名 Knights Landing) 上で、R アプリケーションの大幅なスピードアップを実現できるようになりました。インテル® Data Analytics Acceleration Library (インテル® DAAL) のようなインテル® ソフトウェア・ツールを使用することで、開発者の労力を最小限に抑えつつ、これを達成することが可能です。
最新のインテル® Xeon Phi™ プロセッサーは、コンピューティング負荷の高いアプリケーション向けに特化したプラットフォームです。以下を含む、いくつかの新しい画期的な技術を提供します。
- ソケット (セルフブート CPU) とコプロセッサー・バージョン
- DDR4 メモリーに加えて、マルチチャネル DRAM (MCDRAM) と呼ばれる高帯域幅オンパッケージ・メモリー
- 最先端のベクトル化テクノロジー: インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) 命令セット
- ダイごとに最大 72 コア、コアごとに 4 スレッドによる超並列処理
- 倍精度浮動小数点演算では 3+ TFLOPS
- 単精度浮動小数点演算では 6+ TFLOPS
インテルでは、開発者がこれらの技術を搭載したインテル® Xeon Phi™ プロセッサーを最大限に利用できるように、インテル® Parallel Studio XE スイートでソフトウェア・ツール群を提供しています。その 1 つが、最適化されたマシンラーニングおよびデータ解析アルゴリズムを提供するインテル® DAAL です。マシンラーニングの問題は、一般に CPU およびメモリー要件が最も厳しく、インテル® Xeon Phi™ プロセッサーは、このような問題にとって理想的なプラットフォームです。インテル® DAAL は、インテル® Xeon Phi™ プロセッサー向けに最適化されたマシンラーニング・アプリケーションを素早く開発できるように支援します。
R はオープンソース・プロジェクトで、統計解析、データマイニング、マシンラーニング向けの最も豊富なアルゴリズム群を提供するソフトウェア環境です。1 R は、データ・サイエンティストの間で非常に人気があります。しかし、特別なチューニングなしでは、R とそのパッケージは、インテル® Xeon Phi™ プロセッサーのハイパフォーマンスな機能を十分に活かすことはできません。インテル® Xeon Phi™ プロセッサー上での R のアウトオブボックス・パフォーマンスは良くないことが想定されます。これは、通常の R はほとんどの場合、1 つのインテル® Xeon Ph™ プロセッサー・コア上で、シングルスレッドしか使用しないためです。つまり、(72 コア、コアごとに 4 スレッドと仮定した場合) インテル® Xeon Ph™ プロセッサー上で利用可能な計算リソースの 1/288 しか使用していないことになります。1 つのインテル® Xeon Phi™ プロセッサーは、およそ 1 つのインテル® Atom™ プロセッサーに相当し、1 つのインテル® Xeon® プロセッサーよりも性能が劣ります。また、通常の R は、インテル® AVX-512 命令セットを利用する高度なベクトル化や高帯域 MCDRAM のようなパフォーマンス機能を利用しません。
インテル® Xeon Phi™ プロセッサーの魅力的なデータ処理能力を、R プログラマーが簡単に利用できる方法があります。それは、R 環境に最適化されたライブラリーを統合することです。ここでは、典型的なマシンラーニング・アルゴリズムのナイーブベイズ分類器を使用します。インテル® Xeon Phi™ プロセッサー・ベースのセルフブートシステムで、インテル® DAAL を使用して、R でナイーブベイズ分類器を作成し、実行する方法をステップ・バイ・ステップで示します。そして、そのパフォーマンスを R パッケージ e1071 のネイティブ実装と比較します。2
ナイーブベイズ分類器
ナイーブベイズ・アルゴリズムは、ベイズの定理に基づく分類手法で、3 すべての特徴は互いに独立していると仮定します。単純ですが、多くの場合、洗練された分類手法よりもパフォーマンスが優れています。一般に、ドキュメントの分類、スパムメールの検出などに使用されます。特徴ベクトル Xi=(xi1,…,xip)、i=1,…,n (xik は i 番目の観測の k 番目に観測された特徴のスケーリングされた頻度、p は特徴の数)、ラベルのセット C=(C1,…,Cd) の場合、ナイーブベイズ・アルゴリズムは次のようになります。
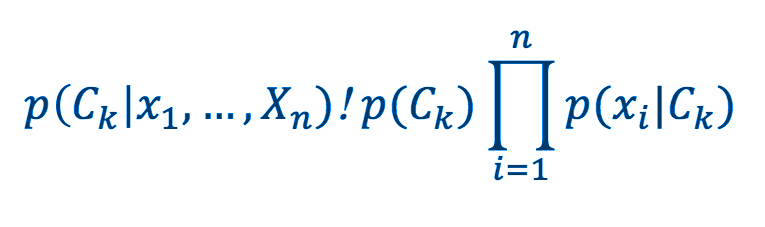
ラベル Ck1 では、
事後確率は、(事前確率 × 尤度) に正比例します。
トレーニング段階では、各観測のラベルが判明しているトレーニング・データセットが、各クラス (ラベル) の事前確率とすべての特徴の尤度などの引数を含むモデルの学習に使用されます。そして、予測段階では、新しい観測ごとに、アルゴリズムは観測の最大事後確率を計算し、対応するラベルを割り当てます。
R のナイーブベイズ
良く知られている R のナイーブベイズ分類器は、パッケージ e1071: Misc Functions of the Department of Statistics, Probability Theory Group で提供されています。2
簡単なインターフェイスと 2 つの関数が含まれており、1 つはモデルをトレーニングし、もう 1 つはモデルを適用します。
