

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Part #1 – Tuning Java Garbage Collection for Hbase」(https://software.intel.com/en-us/blogs/2014/06/18/part-1-tuning-java-garbage-collection-for-hbase) の日本語参考訳です。
このパート 1 の記事では、100% YCSB 読み取りの HBase* 用 Java* ガベージ・コレクション (GC) をチューニングする方法を説明します。パート 2 では 100% 書き込み、パート 3 では 50%/50% 読み取り/書き込みの Java* GC のチューニングを行います。すべての記事で、標準 NoSQL ワークロードである YCSB を使用します。YCSB と HBase* のインストール方法および設定方法についてはすでに多くの文献で紹介されているため、詳細は説明しません。
最後に、この記事を広く紹介するために尽力してくれた Liqi Yi 氏と Yanping Wang 氏に感謝します。
——–
HBase* は、NoSQL データストレージを提供する Apache のオープンソース・プロジェクトであり、bsp; Apache Hadoop* Distributed File System (HDFS*) とともによく使用されます。世界中に広く普及しており、Facebook、Twitter、Yahoo なども HBase* を使用しています。 開発者の視点から見ると、HBase* は、「構造化されたデータ用の分散ストレージシステムである Google* の Bigtable に基づいて作成された、分散型の非リレーショナル・データベース」です。HBase* は、スケールアップ (より大きなサーバーで実行) あるいはスケールアウト (より多くのサーバーで実行) によって、非常に高いスループットを容易に制御できます。
ユーザーの視点から見ると、各単一クエリーのレイテンシーは重要です。これまで HBase* ワークロードのテスト、チューニング、最適化を多くのユーザーと取り組んできましたが、最近は 99 パーセンタイル (上から 1%) の操作レイテンシーを望むユーザーが多くなっています。これは、クライアントのリクエストからクライアントに戻るまで、すべてを 100 ミリ秒以内で行わなければいけないことを意味します。
レイテンシーが変動する要因はいくつかあります。最も大きく、予測できないレイテンシー変動の要因は、ガベージ・コレクション (メモリーのクリーンアップなど) のための Java* 仮想マシン (JVM) の “Stop-the-World” 休止です。
問題点を特定するため、Oracle* jdk7u21 と jdk7u60 の G1 (ガベージファースト) ガベージコレクターを用いてテストをいくつか行いました。 使用したサーバーシステムは、インテル® Xeon® プロセッサー (開発コード名: Ivy-bridge EP、ハイパースレッディング有効、40 論理プロセッサー) ベースのシステムです。ローカルストレージとして、256GB の DDR3-1600 RAM と 3 つの 400GB SSD を搭載しています。このセットアップには、1 つのマスターと 1 つのスレーブが含まれ、適切に負荷がスケーリングされた単一ノードで構成されています。Apache HBase* バージョン 0.98.1 と、ローカル・ファイル・システムとして HFile ストレージを使用しました。HBase* テストテーブルの行数は 4 億行で、サイズは 580GB です。ここでは、デフォルトの HBase* ヒープ・ストラテジー (40% blockcache、40% memstore) を使いました。YCSB は、HBase* サーバーにリクエストを送る 600 のワークスレッドを操作します。
次の図は、jdk7u21 で “-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100” を設定して 1 時間 100% 読み取りを実行した結果です。指定した項目は、使用するガベージコレクター、ヒープサイズ、目標のガベージ・コレクション (GC) “Stop-the-World” 休止時間です。
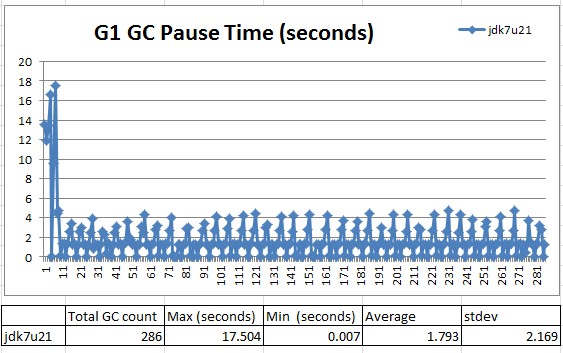
図 1: GC 休止時間の大きな変動
このケースの GC 休止時間は大きく変動しました。17.5 秒の初期変動の後、7 ミリ秒から 5 秒の範囲で変動しています。
次の図は、定常状態の GC 休止時間をより詳細に示しています。
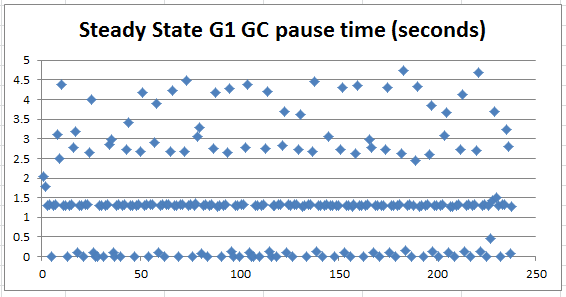
図 2: 定常状態の GC 休止時間の詳細
図 2 から、GC 休止時間には 3 つのグループ (1 ~ 1.5秒、0.007 ~0.5 秒、1.5 ~ 5 秒) があることが分かります。これは奇妙に思えるため、最新リリースの jdk7u60 でテストしてみました。
全く同じ JVM パラメーター、”-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100″ を用いて、同じ 100% 読み取りテストを実行しました。
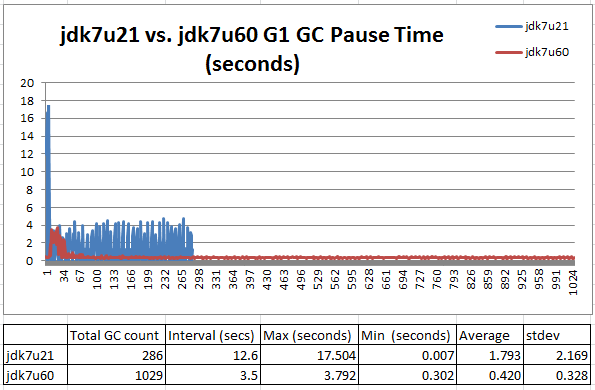
図 3: 大幅に改善された休止時間の変動
jdk7u60 では、初期変動後に休止時間を制御する G1 の能力が大幅に向上しています。jdk7u60 では、1 時間のテスト中に 1029 の Young および混在 GC が行われました。約 3.5 秒ごとに GC が行われたことになります。jdk7u21 では、1 時間のテスト中に行われた GC は 286 で、約 12.6 秒ごとに GC が行われたことになります。jdk7u60 では、休止時間の範囲は 0.302 から 1 秒で、大きな変動はありません。
次の図 4 では、定常状態中の GC 休止の総数が 150 になっています。
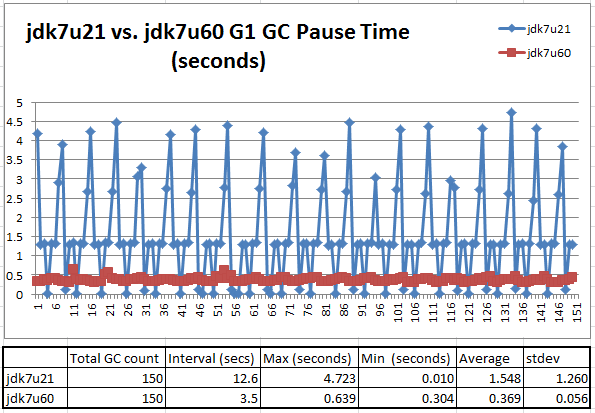
図 4: 改善されたがまだ不十分
定常状態中に、jdk7u60 では約 369 ミリ秒の平均休止時間が維持されています。この値は jdk7u21 よりも向上していますが、”–Xx:MaxGCPauseMillis=100″ で指定した 100 ミリ秒の要件にはまだ達していません。
100 ミリ秒の休止時間を達成するためにできることを判断するには、JVM のメモリー管理と G1 (ガベージファースト) ガベージコレクターの動作をより深く理解する必要があります。次の図は、Young 世代収集中の G1 の動作を示したものです。
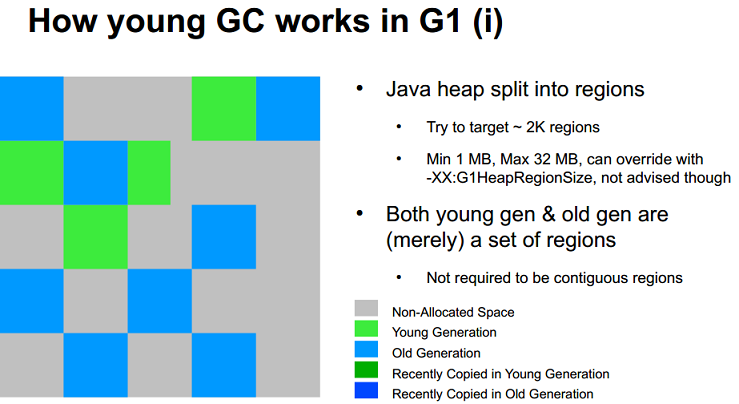
図 5: JavaOne 2012 プレゼンテーション: 「G1 Garbage Collector Performance Tuning」 (Charlie Hunt および Monica Beckwith) より
JVM を起動すると、JVM は、起動パラメーターに基づいて、ヒープをホストする大きな連続のメモリーチャンクを割り当てるようにオペレーティング・システムに要求します。このメモリーチャンクは JVM により複数の領域に分割されます。
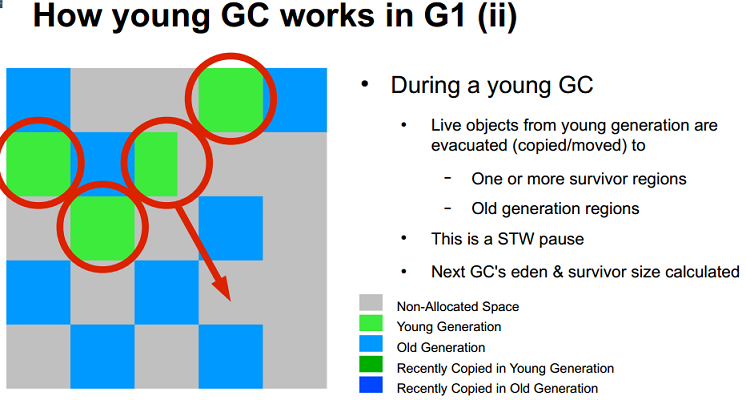
図 6: JavaOne 2012 プレゼンテーション: 「G1 Garbage Collector Performance Tuning」 (Charlie Hunt および Monica Beckwith) より
図 6 に示すように、Java* プログラムが Java* API を介して最初に割り当てるすべてのオブジェクトは、左の Young 世代の Eden 空間に配置されます。しばらくして、Eden 空間がフルになると、Young 世代の GC が行われます。まだ参照されている (ライブ) オブジェクトは Survivor 空間にコピーされます。Young 世代の数回の GC を生き残ったオブジェクトは、Old 世代の空間に進みます。
Young GC が行われるとき、ライブ・オブジェクトを安全にマークしてコピーするため、Java* アプリケーションのスレッドは停止されます。これらの停止は、休止が終わるまでアプリケーションが応答しなくなる、いわゆる “Stop-the-World” GC 休止です。
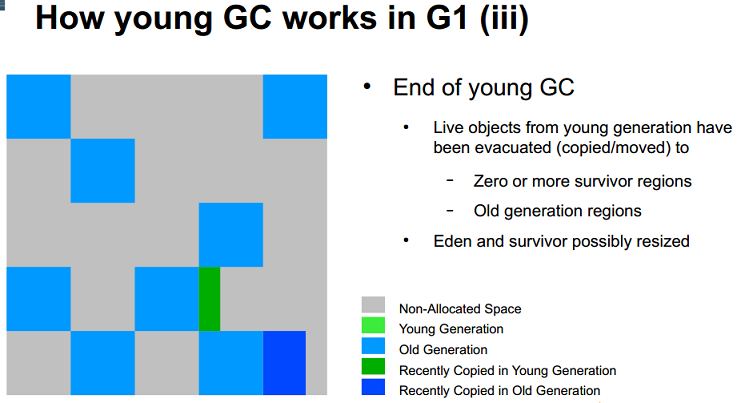
図 7: JavaOne 2012 プレゼンテーション: 「G1 Garbage Collector Performance Tuning」 (Charlie Hunt および Monica Beckwith) より
Old 世代が混雑し、あるレベル (-“XX:InitiatingHeapOccupancyPercent=?” により制御、デフォルトは合計ヒープの 45%) に達すると、混在 GC が行われます。混在 GC は、Young 世代と Old 世代の両方を収集します。混在 GC の休止は、混在 GC が行われるときのクリーンアップに Young 世代がどの程度時間をかけるかによって制御されます。
G1 では、”Stop-the-World” GC の休止は、G1 が Eden 空間のライブ・オブジェクトをどの程度速くマークしてコピーできるかにより決まります。これを念頭において、目標の休止時間 (100 ミリ秒) になるように G1 GC をチューニングするため、HBase* メモリー割り当てパターンがどのように役立つかを解析しました。
HBase* では、2 つのインメモリー構造 (読み取り操作用に HBase* のファイルブロックをキャッシュする BlockCache と、最新の更新をキャッシュする Memstore) でヒープのほとんどを消費します。

図 8: HBase* では 2 つのインメモリー構造でヒープのほとんどを消費する
HBase* の BlockCache のデフォルト実装は LruBlockCache であり、HBase* ブロックをすべてホストする大きなバイト配列を使用します。ブロックが「退避」されると、そのブロックの Java* オブジェクトへの参照が削除され、GC はメモリーを再配置できるようになります。
LruBlockCache と Memstore を形成する新しいオブジェクトは、最初に Young 世代の Eden 空間に移動します。ライブの (LruBlockCache から退避されない、あるいは Memstore からフラッシュされない) 状態が長い場合、いくつかの Young 世代の GC の後に、Java* ヒープの Old 世代に進みます。Old 世代の空き容量が、指定された threshOld よりも少ない (HeapOccupancyPercent を初期化して開始する) 場合、混合 GC が開始され Old 世代のデッド・オブジェクトを取り除き、Young 世代からライブ・オブジェクトをコピーした後、Young 世代の Eden と Old 世代の HeapOccupancyPercent を再計算します。HeapOccupancyPercent があるレベルに達すると、フル GC が行われ、Old 世代内部のデッド・オブジェクトをすべて取り除くため、”Stop-the-World” GC 休止が大きくなります。
“-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy” を指定して生成された GC ログを調べたところ、HeapOccupancyPercent は HBase* 100% 読み取り中にフル GC が行われるほど大きくなっていませんでした。GC 休止は、Young 世代の “Stop-the-World” 休止と時間で増加する参照処理数により決定されていました。
解析の完了後、デフォルトの G1 GC 設定における 3 つのグループを変更しました。
(1) -XX:+ParallelRefProcEnabled オプションを指定する
このオプションを指定すると、GC は複数のスレッドを使用して Young および混在 GC 中に増加する参照を処理します。このオプションを HBase* に使用すると、GC リマーク時間が 75% 減少し、全体の GC 休止時間が 30% 減少します。
(2) -XX:-ResizePLAB および -XX:ParallelGCThreads=8+(論理プロセッサー数-8)(5/8) を設定する
Young の収集中は、プロモーション・ローカル・アロケーション・バッファー (PLAB) が使われます。複数のスレッドが使用され、各スレッドは Survivor 空間または Old 空間のいずれかにコピーするオブジェクトの空間を割り当てる必要があります。k空メモリーを管理する共有データ構造でスレッドの競合を回避するには、PLAB が必要です。各 GC スレッドには、Survival 空間用に 1 つの PLAB、Old 空間用に 1 つの PLAB があります。そこで、各 GC 間の変動だけでなく、GC スレッド間の通信コストを回避するため、PLAB のサイズ変更を停止しました。
また、8+(論理プロセッサー数-8)(5/8) で計算したサイズになるように GC スレッド数を変更しました。この式は、Oracle* により最近推奨されているものです。
この 2 つの設定により、実行中の GC 休止がよりスムーズになりました。
(3) 100GB ヒープの -XX:G1NewSizePercent のデフォルトを 5 から 1 に変更する
-XX:+PrintGCDetails および -XX:+PrintAdaptiveSizePolicy の出力から、G1 が要件である 100GC 休止時間を満たさない理由が、Eden の処理にかかっている時間であることに気付きました。G1 は、テスト中に Eden の 5GB を空にするために平均 369 ミリ秒かかっていたのです。そこで、-XX:G1NewSizePercent=<正の整数> オプションを用いて、Eden のサイズを 5 から 1 に変更しました。この変更により、GC 休止時間は 100 ミリ秒に減りました。
この実験から、使用した HBase* のセットアップでは、Eden をクリーンする G1 の速度が 100 ミリ秒あたり約 1GB (1 秒あたり約 10GB) であることが分かりました。
この速度に基づいて、Eden サイズを約 1GB で維持できるように、-XX:G1NewSizePercent=<正の整数> を設定しました。次に例を示します。
- 32GB のヒープ、-XX:G1NewSizePercent=3;
- 64GB のヒープ、-XX:G1NewSizePercent=2;
- 100GB 以上のヒープ、-XX:G1NewSizePercent=1;
HRegionserver の最終的なコマンドライン・オプションは次のようになります。
- -XX:+UseG1GC
- -Xms100g -Xmx100g (テストで使用したヒープサイズ)
- -XX:MaxGCPauseMillis=100 (テストの目標 GC 休止時間)
- -XX:+ParallelRefProcEnabled
- -XX:-ResizePLAB
- -XX:ParallelGCThreads= 8+(40-8)(5/8)=28
- -XX:G1NewSizePercent=1
1 時間 100% 読み取り操作を実行したときの GC 休止時間を以下に示します。
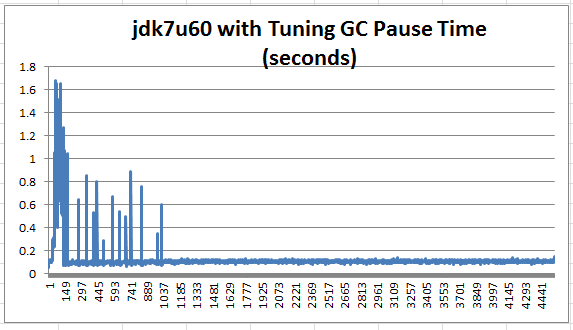

図 9: 最も高い初期変動が半分以下に減少
この図では、最も高い初期変動でさえ、3.792 秒から 1.684 秒に減少しています。最も多い初期変動は 1 秒未満でした。初期変動の後、GC は約 100 ミリ秒の休止時間を維持することができました。
次の図は、定常状態中の jdk7u60 の実行をチューニング前と後で比較したものです。
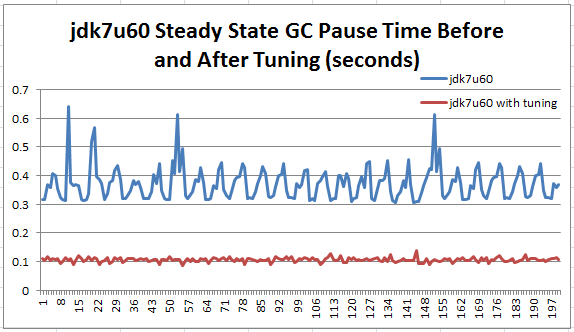

図 10: 定常状態中の jdk7u60 の実行をチューニング前と後で比較
この記事で説明した単純な GC チューニングにより、平均 106 ミリ秒、標準偏差 7 ミリ秒の理想的な GC 休止時間 (約 100 ミリ秒) を達成できました。
まとめ
HBase* は、予測可能で扱いやすい GC 休止時間を要求する、応答時間が重要なアプリケーションです。Oracle* jdk7u60 では、”-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy” を指定して生成された GC ログに基づいて、GC 休止時間を目標の 100 ミリ秒までチューニングすることができました。
参考文献 (英語)
JavaOne 2012 プレゼンテーション: 「G1 Garbage Collector Performance Tuning」 (Charlie Hunt および Monica Beckwith)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
