

この記事は、Dr.Dobb’s Go Parallel に掲載されている「Welcome to the Parallel Jungle!」の日本語参考訳です。
編集注記:
本記事は、2012 年 6 月 29 日に公開されたものを、加筆・修正したものです。
この一連の記事の著者である Herb Sutter 氏は、早い時期からプロセッサーのマルチコア化がソフトウェア開発に及ぼす影響と、ソフトウェア開発者が考えるべき移行における課題を示していました。Sutter 氏による 「フリーランチは終わった」は、IT 業界での名語録にもなっています。この記事は、Sutter 氏が 2012 年の時点で「ムーアの法則」の終焉とそれを取り巻くソフトウェア開発の変化をまとめているものです。2020 年時点で読み返しても興味深い内容です。
このシリーズでは、モバイルデバイスからデスクトップ、クラスター、最高粒度のクラウドまで、並列化がもたらす影響について解説します。さまざまな並列化の実装が存在することによる混乱は、プログラミングにおける大きな挑戦をもたらしました。シリアル・プログラミングでフリーランチの恩恵を受ける時代はすでに終わりを迎えています。
Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | Part 6
グラフ: 3 つのトレンドではなく 1 つのトレンド
次に、マルチコア、ヘテロジニアス・コア、クラウドコアは 3 つのトレンドではなく、1 つのトレンドであることを示しましょう。これには、同一マップ上にこれらの動向を示さなければなりません。図 4 は、プロセッサー・コア・アーキテクチャーとメモリー・アーキテクチャーの変遷、つまり、これまで鉱山をどのように採掘してきたかをグラフにしたものです。
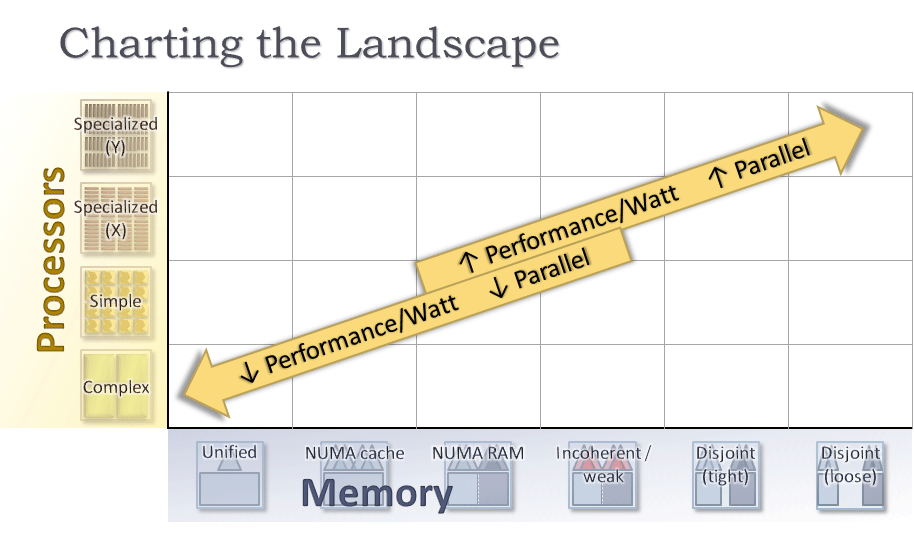 図 4.
図 4.
まず、それぞれの軸について説明した後、過去と現在のハードウェアをまとめてトレンドを特定し、最後にハードウェアが集中する箇所について結論を導きましょう。
プロセッサー・コアの種類
縦軸は、プロセッサー・コアのアーキテクチャーを示しています。図 5 で示されているように、下から上に、アーキテクチャーのパフォーマンスとスケーラビリティーは増加しますが、各ステップで、パフォーマンス上の問題 (黄色) や正当性の問題 (赤) も増えるため、プログラムおよびプログラマーに対する制限も増大します。
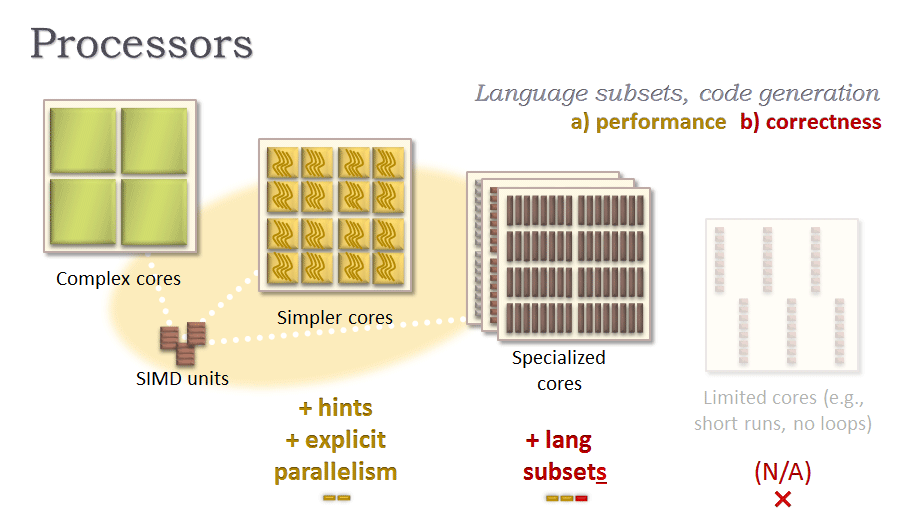
図 5.
複雑なコアは、「大きな」コアで、アムダールの法則で制限されるコードを含む、シリアルコードの実行に適しています。
より単純なコアは、「小さな」コアで、メインストリームのプログラミング言語を使用して並列化されたコードの実行に適しています。
専用コアは、GPU、DSP、Cell の SPU のようにより制限されたコアで、メインストリーム言語の一部の機能 (例外処理など) はまだ完全にサポートされていません。これらのコアは、C や C++ のような言語のサブセットで表現された、高度に並列化されたコードの実行に適しています。例えば、XBox* の Kinect* センサーは、コンソールの CPU と GPU の両方のコアを使用しています。
グラフの上 (図 6 の右) に移動するほど、パフォーマンス・スループットが向上し、消費電力が低下しますが、より高い並列性を実装したり、メインストリーム言語のサブセットのみを使用する必要があり、アプリケーション・コードがより制限されます。
多くのアプリケーションでは、同一プログラムにこれらの種類のコードがすべて含まれており、すべての種類のコアを含むヘテロジニアス・コンピューターで最適に実行されるため、将来のメインストリームのハードウェアには 3 種類のコアがすべて含まれることになるでしょう。例えば、現在提供されているほとんどの PS3 ゲーム、すべての Kinect* ゲーム、すべての CUDA*/OpenCL*/C++AMP* アプリケーションは、1 つのアプリケーションの一部を CPU で、残りの部分を専用コアで実行するように設計されているため、ホモジニアス・マシンでは適切に (あるいは全く) 実行できません。このようなアプリケーションは始まりにすぎません。
メモリー・アーキテクチャー
横軸は、6 つの一般的なメモリー・アーキテクチャーを示しています。左から右に、パフォーマンスとスケーラビリティーは増加しますが、パフォーマンス上の問題 (黄色) や正当性の問題 (赤) に対処するため、プログラムおよびプログラマーの作業も増大します。図 6 では、三角形はキャッシュを、下の四角形は RAM を表しています。プロセッサー・コア (ALU) は、各キャッシュの「頂点」に位置します。
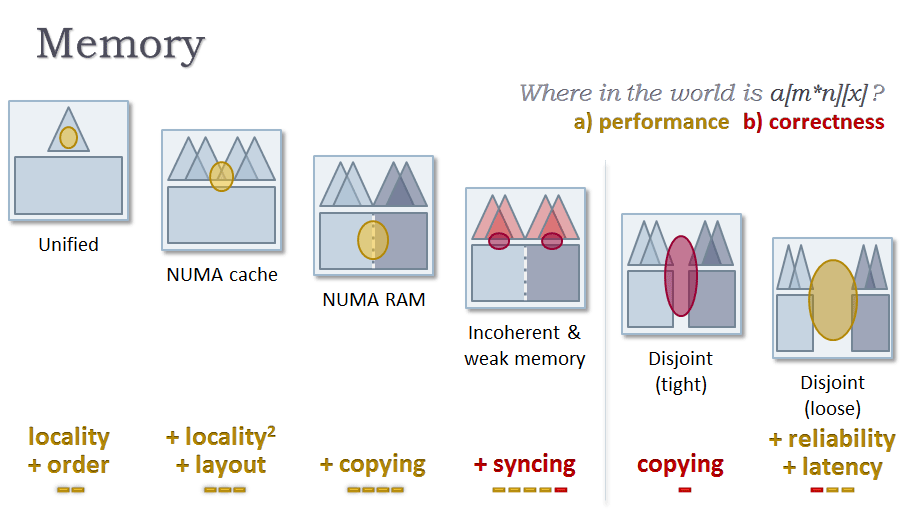 図 6.
図 6.
ユニファイド・メモリーは、単一コアの主鉱脈と関連しており、メモリー階層は非常に単純です。1 つの山の頂点にコアが位置します。これは、2000 年代中頃まで、ほとんどのメインストリーム・コンピューターに搭載されていました。プログラミング・モデルは単純で、すべてのポインター (またはオブジェクト参照) をバイトで指定でき、バイトはコアからの距離に等しくなります。
現代のメモリー・アーキテクチャーではシーケンシャルなアクセスパターンが主流のため、この時点でも、プログラマーは、少なくとも 2 つの基本的なキャッシュ効果 (「ホットな」データがどの程度キャッシュに収まるかを示す局所性とアクセス順) を意識する必要があります (詳細は、マシン・アーキテクチャーについての解説 (http://is.gd/1Fe99o) を参照)。
NUMA キャッシュは、単一の RAM に複数のキャッシュを追加したものです。これで、1 つの山の代わりに、複数の頂点があり、それぞれの頂点にコアが位置する山になりました。今日のメインストリームのマルチコアデバイスで用いられているアーキテクチャーです。ここでは、異なるコアが異なるメモリーにアクセスする限り、まだ単一のアドレス空間を使用して優れたパフォーマンスを得ることができますが、プログラマーは次の 2 つのパフォーマンス問題に対処しなければなりません。
- 一部の頂点間がほかの間よりも近いこと (L2 キャッシュを共有する 2 つのコアと L3 や RAM を共有する 2 つのコア) による新しい 局所性 の問題
- データをともに使用する場合は物理的に近いままで (同じキャッシュラインで) 保ち、ともに使用しない場合は (フォルス・シェアリングを回避するために) 別々に保つという レイアウト の問題
NUMA RAM は、RAM を複数の物理的なチャンクに細分化しますが、単一の論理アドレス空間のままです。リモートコアのチャンクの RAM にアクセスするとバスを介して行き来することになるため、コア間のパフォーマンスの谷はより深くなります。例えば、ブレードサーバー、複数ソケットの対称型マルチプロセッサー (SMP) デスクトップ・コンピューター、また CPU と GPU メモリーの統合アドレス空間を提供します。これは、一部のメモリーが CPU に近く、ほかのメモリーが GPU に近い新しい GPU アーキテクチャーなどです。パフォーマンスを意識するプログラマーが考慮するべきこととして、ここでは コピー が追加されます。たとえすべてをポインターで処理することが可能であっても、すべてのアクセスでコストがかかるのであれば、ポインターで処理すべきではありません。
インコヒーレント (一貫性のない) /弱いメモリー (Incoherent & weak memory)は、メモリーをデフォルトで非同期にして、各コアでメモリーの状態を個別に制御できるようにします。少なくともメモリーを再び同期しなければならないときまで、処理をより高速に実行できます。この記事を執筆している時点で、このメモリーモデルを使用しているメインストリーム CPU で残っているのは PowerPC* と ARM* プロセッサーのみです (いくつかの課題があるにもかかわらずポピュラーです。詳細は後述)。このモデルは単一のアドレス空間のままですが、プログラマーには自身でメモリーの 同期 を行わなければならないという負担が増えます。
密結合 (Disjoint tight) メモリーは、異なるコアが (特に共有バス上の) 異なるメモリーを見られるようにしたものです。レイテンシーの低い密結合ユニットとして実行され、信頼性は単一ユニットとして評価されます。このモデルは、密にクラスター化された複数の山を持つ島のグループといえます。それぞれの島には、コアを頂点としメモリーの隅々を見渡すキャッシュの山々があり、島々は橋で繋がっています。そこをトラック部隊が移動して (バルク転送処理、メッセージキューなどを使用して) ポイントからポイントに情報が伝えられます。
メインストリームでは、オンボードのメモリーが CPU やほかの GPU と共有されない 2009 年~2011 年頃の GPU でこのモデルが使用されました。プログラマーは単一アドレス空間やポインターを共有する機能を利用できなくなりましたが、その代わりにこれまで蓄積されていたプログラマーの負担はすべてなくなり、メモリーの島々の間でデータをコピーするという、1 つの新しい責任が生じました。
疎結合 (Disjoint loose) は、コアが異なる部屋、建物、データセンターに拡散されたクラウドです。島と島の間の距離が遠くなり、移動手段は「橋」 (バス) から「高速艇」と「タンカー」 (ネットワーク) になりました。メインストリームでは、このモデルは HaaS クラウド・コンピューティングで見られます。計算クラスターの商品化といえます。プログラマーは、ノード間の移動における信頼性 と、遠く離れた島々の間のレイテンシーの 2 つの追加項目に取り組むことになります。通常、これらはライブラリーやランタイムを使用して抽象化できます。
ハードウェアのグラフ化
3 つのトレンドはすべて、(グラフの余白を埋めて) ヘテロジニアスな並列コンピューティングを可能にするという 1 つのトレンドの一面にすぎません。図 7 は、それぞれのマス目に適したワークロードが存在するため、グラフの余白を埋めることができることを示しています。
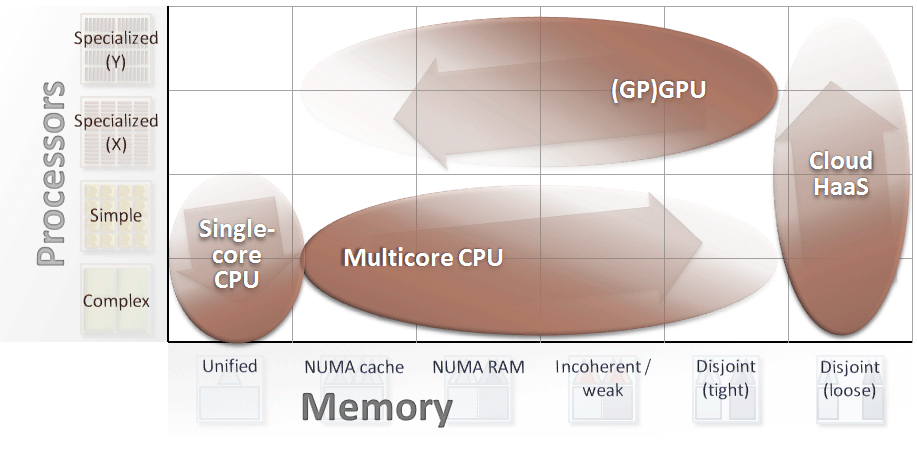
図 7.
