

この記事は、インテル® デベロッパー・ゾーンに掲載されている「OpenCL™ 2.0 Non-Uniform Work-Groups」(https://software.intel.com/en-us/articles/opencl-20-non-uniform-work-groups) の日本語参考訳です。
目次
はじめに
不均等なワークグループ
サンプルコードの概要
動作環境
サンプルコードの実行
参考文献
はじめに
OpenCL* 実行モデルには、NDRange の個々のワークアイテムの集まりを表す、ワークグループという概念があります。同じワークグループのワークアイテムは、ローカルメモリーの共有、ワークグループ・バリアによる同期、async_work_group_copy などのワークグループ関数による連携が可能です。OpenCL* 1.x を利用するアプリケーションの場合、NDRange 次元はワークグループ次元で均等に分割できなければなりません。clEnqueueNDRangeKernel の呼び出しで均等に分割できない global_size 引数と local_size 引数を指定すると、CL_INVALID_WORK_GROUP_SIZE エラーコードが返されます。また、clEnqueueNDRangeKernel の呼び出しで local_size を NULL にし、ランタイムがワークグループのサイズを選択できるようにすると、ランタイム時にグローバル NDRange 次元を均等に分割できるサイズを選択しなければなりません。
NDRange を均等に分割できるワークグループ・サイズにしなければならないという制限は、開発者の負担を増します。単純な 3×3 イメージのぼかしアルゴリズム (サンプルコードに含まれるアルゴリズム) について考えてみます。このアルゴリズムでは、入力ピクセルの近隣の 3×3 ピクセル値の平均から各出力ピクセルが計算されます。これは、畳み込み、エロージョン、ダイレーション、メディアンフィルターを含む、近隣ピクセルを処理する多くのイメージ処理アプリケーションと同じです。このようなアルゴリズムでは、イメージ境界での出力ピクセルの扱い方がさまざまです。次の図に示すように、出力ピクセルは入力イメージの境界外にあるピクセルに依存します。
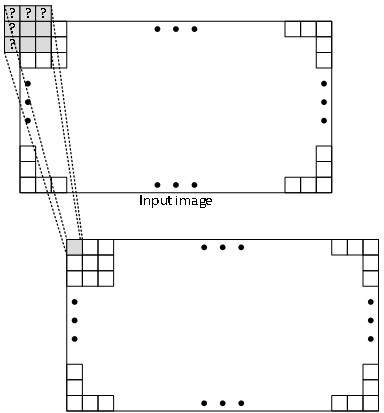
境界ピクセルを処理する 1 つの方法として、定数値を使用したり、境界の内側に隣接するピクセルを再利用して、境界をクランプします。ただし、このアプローチは、カーネル内でピクセルごとのロジックが必要になるため、コストがかかります。アプリケーションによっては、境界の出力値は重要でないため無視することができます。その場合、NDRange のサイズは出力イメージのサイズから境界領域のサイズを引いた値になり、 通常は均等に分割するのが困難です。例えば、1920×1080 イメージに対して 3×3 フィルターを実行する場合、両側に 1 ピクセルの境界が必要になります。最も簡単な方法は、1918×1078 カーネルを利用することです。しかし、1918 と 1078 はどちらも適切なワークグループ・サイズにはなりません。
この記事で使用するサンプルは、3×3 イメージのぼかしプログラムですが、この問題はほかのアルゴリズムでも見られます。
不均等なワークグループ
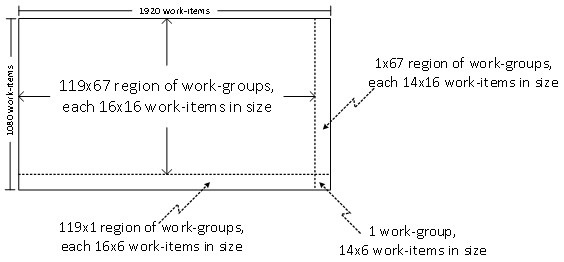
OpenCL* 2.0 では、この問題に対応する新しい機能が追加されています。この機能は、「不均等なワークグループ」と呼ばれ、OpenCL* 2.0 ランタイムが NDRange のすべての次元を不均等なワークグループ・サイズに分割できるようにします。この機能を利用すると、プログラマーが NDRange を均等に分割できないワークグループ・サイズを指定した場合、ランタイムはできるだけ多くのワークグループが指定されたサイズになり、残りのワークグループは異なるサイズになるように NDRange を分割します。例えば、NDRange が 1918×1078 ワークアイテムで、ワークグループ・サイズが 16×16 ワークアイテムの場合、OpenCL* 2.0 ランタイムは次の図に示すように NDRange を分割します。
さらに、この機能は、プログラマーが clEnqueueNDRangeKernel の local_size 引数を NULL にした場合、OpenCL* ランタイムが任意のワークグループ・サイズと NDRange サイズを使用できるようにします。一般に、アプリケーション・ロジックで特定のワークグループ・サイズを必要としない場合、local_size 引数を NULL にしてカーネルを実行したほうが良いでしょう。
カーネルコード内で、get_local_size() ビルトインは呼び出し元のワークグループの実際のサイズを返します。カーネルが clEnqueueNDRangeKernel の local_size 引数で渡された正確なサイズが必要な場合、get_enqueued_local_size() はその値を返します。
不均等なワークグループを使用できるようにするには、この OpenCL* 2.0 機能を有効にする -cl-std=CL2.0 フラグを指定してカーネルをコンパイルします。このフラグを指定しないと、OpenCL* 2.0 対応デバイスであっても、デフォルトで OpenCL* 1.2 が使用されます。また、-cl-uniform-work-group-size フラグを使用すると、-cl-std=CL2.0 フラグを指定してコンパイルしたカーネルで不均等なワークグループを無効にできます。これは、カーネルコードを OpenCL* 2.0 へ移行する際に、レガシーコードで役立つでしょう。
OpenCL* 2.0 の不均等なワークグループ機能により、OpenCL* がより使いやすくなり、一部のカーネルではパフォーマンスが向上します。そのため、もう均等に分割されない NDRange サイズのためにホストとカーネルコードを追加する必要はありません。また、この機能を利用するコードは、SIMD を効率良く利用し、メモリーアクセスをアライメントするため、注意深くワークグループ・サイズを選択することで、パフォーマンスを向上できます。
サンプルコードの概要
サンプルコードは、前述のとおり、3×3 イメージのぼかしアルゴリズムを実装します。ホストコードで注目すべきは main.cpp ファイルです。このファイルでは次の処理を行います。
- 入力ファイルからビットマップを読み込みます。
- OpenCL* 1.2 設定で OpenCL* C カーネルをコンパイルします。
// OpenCL* 1.2 でボックスのぼかしカーネルをコンパイルします // (これは、OpenCL* 2.0 デバイスでもデフォルトのコンパイル設定です。) // これにより、OpenCL* 2.0 使用前の動作を確認できます。 cl::Kernel kernel_1_2 = GetKernel(device, context);
- OpenCL* 2.0 設定で OpenCL* C カーネルをコンパイルします (-cl-std=CL2.0 フラグを渡します)。
// OpenCL* 2.0 でボックスのぼかしカーネルをコンパイルします。 // 不均等なワークグループ機能を利用するには OpenCL* 2.0 が必要です。 kernel_2_0 = GetKernel(device, context, "-cl-std=CL2.0");
- すべてのバージョンのカーネルの起動に使用されるグローバルサイズを設定します。
// すべての NDRange で使用されるグローバル NDRange サイズを設定します。 // これはボックスのぼかしプログラムなので、小さな次元の 2 つの要素を使用します。 // 通常、このグローバルサイズは、カーネルの実行で一般的に使用される // ローカル・ワーク・サイズで均等に分割できません。 cl::NDRange global_size = cl::NDRange(input.get_width() - 2, input.get_height() - 2);
- OpenCL* 1.2 でコンパイルしたカーネルを使って、
local_sizeを NULL にしてイメージをぼかします。// OpenCL* 1.2 でコンパイルしたカーネルを使用し、 // local_size を NULL にした場合 cout << "Compiled with OpenCL 1.2 and using a NULL local size:" << endl << endl; output = RunBlurKernel(context, queue, kernel_1_2, global_size, cl::NullRange, input, true); - OpenCL* 1.2 でコンパイルしたカーネルを使って、
local_sizeを 16×16 にしてイメージをぼかします。// OpenCL* 1.2 でコンパイルしたカーネルを使用し、 // local_size を 16x16 にした場合。 // OpenCL 2.0 でこのコードを実行しても上手く動作しません。 // OpenCL 2.0 設定でカーネルをコンパイルする必要があります。 try { cout << "Compiled with OpenCL 1.2 and using an even local size:" << endl << endl; output = RunBlurKernel(context, queue, kernel_1_2, global_size, cl::NDRange(16, 16), input, true); cout << endl; output.Write(output_files[1]); } catch (...) { cout << "Trying to launch a non-uniform workgroup with a kernel " "compiled using" << endl << "OpenCL 1.2 failed (as expected.)" << endl << endl; } - OpenCL* 2.0 でコンパイルしたカーネルを使って、
local_sizeを NULL にしてイメージをぼかします。// OpenCL* 2.0 でコンパイルしたカーネルを使用し、 // local range を NULL にした場合。 cout << "Compiled with OpenCL 2.0 and using a NULL local size:" << endl << endl; output = RunBlurKernel(context, queue, kernel_2_0, global_size, cl::NullRange, input, true); - OpenCL* 2.0 でコンパイルしたカーネルを使って、
local_sizeを 16×16 にしてイメージをぼかします。// OpenCL* 2.0 でコンパイルしたカーネルを使用し、 // local_size を 16x16 にした場合。 // これは、OpenCL* 2.0 デバイスとコンパイラーでのみ動作します。 cout << "Compiled with OpenCL 2.0 and using an even local size:" << endl << endl; output = RunBlurKernel(context, queue, kernel_2_0, global_size, cl::NDRange(16, 16), input, true); - ステップ 2 ~ 5 で生成された出力ファイルを書き出します。
ステップ 5 ~ 8 の各ケースで、NDRange の四隅で get_local_size () と get_get_enqueued_local_size () を呼び出した結果が画面に表示されます。この結果から、実行時に NDRange がワークグループによってどのように分割されたかを確認できます。
サンプルの入力イメージはステップ 6 で処理に失敗します。これは、NDRange は 16×16 ワークグループで分割できないためです。さらに、ステップ 7 と 8 も OpenCL* 2.0 をサポートしていないため処理に失敗します。
ぼかしアルゴリズムを実装するカーネルは BoxBlur.cl にあります。非常に単純な実装で、ボックスのぼかし実装として必ずしも最適なものではありません。
動作環境
サンプルコードのコンパイルと実行には、次の要件を満たす PC が必要です。
- インテル® Core™ プロセッサー・ファミリー (開発コード Broadwell) のプロセッサー
- Microsoft* Windows* 8 または 8.1
- インテル® SDK for OpenCL* Applications 2014 R2 以上
- Microsoft* Visual Studio* 2012 以上
サンプルコードの実行
このサンプルは、前述の NDRange ケースごとに、入力ビットマップを読み込み、ぼかし処理を実行して、ビットマップを出力するコンソール・アプリケーションです (ただし、ステップ 6 のケースは意図的に失敗するようにしています)。サンプルでは、次のコマンドライン・オプションをサポートしています。
| オプション | 説明 |
|---|---|
-h、-? |
ヘルプを表示し、終了します。 |
-i <input prefix> |
入力ビットマップ・ファイルのプリフィックス。ファイル名は <input prefix>.bmp で、 24 ビット形式のビットマップ・ファイルでなければなりません。 |
-o <output prefix> |
出力ビットマップ・ファイルのプリフィックス。ファイル名は <output_prefix>_N.bmp で、N は 0 から 3 の範囲の値です。 |
このサンプルを実行すると、次のような出力が得られます。
Input file: input.bmp
Output files: output_0.bmp, output_1.bmp, output_2.bmp, output_3.bmp
Device: Intel(R) HD Graphics 5500
Vendor: Intel(R) Corporation
Compiled with OpenCL 1.2 and using a NULL local size:
Work Item get_global_id() get_local_size() get_enqueued_local_size()
---------------------------------------------------------------------------
Top left ( 0, 0) ( 1, 239) undefined
Top right (637, 0) ( 1, 239) undefined
Bottom left ( 0, 477) ( 1, 239) undefined
Bottom right (637, 477) ( 1, 239) undefined
Compiled with OpenCL 1.2 and using an even local size:
Trying to launch a non-uniform workgroup with a kernel compiled using
OpenCL 1.2 failed (as expected.)
Compiled with OpenCL 2.0 and using a NULL local size:
Work Item get_global_id() get_local_size() get_enqueued_local_size()
---------------------------------------------------------------------------
Top left ( 0, 0) ( 1, 239) ( 1, 239)
Top right (637, 0) ( 1, 239) ( 1, 239)
Bottom left ( 0, 477) ( 1, 239) ( 1, 239)
Bottom right (637, 477) ( 1, 239) ( 1, 239)
Compiled with OpenCL 2.0 and using an even local size:
Work Item get_global_id() get_local_size() get_enqueued_local_size()
---------------------------------------------------------------------------
Top left ( 0, 0) ( 16, 16) ( 16, 16)
Top right (637, 0) ( 14, 16) ( 16, 16)
Bottom left ( 0, 477) ( 16, 14) ( 16, 16)
Bottom right (637, 477) ( 14, 14) ( 16, 16)
Done!
|
入力イメージは 640×480 なので、各ケースの NDRange サイズは 638×478 になります。上記の出力から、OpenCL* 1.2 でコンパイルしたカーネルを使用し、local_size を NULL にした場合、各ワークグループのサイズは均等に分割できない値 (1, 239) になることが分かります。ワークグループ・サイズが 2 の累乗でない場合、一部のカーネルでは SIMD レーンがアイドル状態になり、メモリーアクセスがアライメントされず、パフォーマンスが悪くなります。
OpenCL* 1.2 でコンパイルしたカーネルを使用し、ワークグループ・サイズ 16×16 で実行した場合、648 と 478 はどちらも 16 で割り切れないため、予想どおり処理に失敗しています。
OpenCL* 2.0 でコンパイルしたカーネルを使用し、local_size を NULL にした場合、OpenCL* ランタイムは NDRange を任意のワークグループ・サイズに分割することができます。上記の出力から、このケースでランタイムは、OpenCL* 1.2 でコンパイルしたカーネルで実行した場合と同様に、均等なワークグループ・サイズを使用していることが分かります。
OpenCL* 2.0 でコンパイルしたカーネルとワークグループ・サイズ 16×16 を使用した場合、ランタイムは NDRange を不均等なワークグループに分割しています。上記の出力から、左上のワークグループは 16×16、右上のワークグループは 14×16、左下のワークグループは 16×14、右下のワークグループは 14×14 であることが分かります。ほとんどのワークグループは 16×16 なので、カーネルは実行ユニットの SIMD レーンを効率良く利用し、適切にアライメントされたメモリー参照を生成できるでしょう。
参考文献 (英語)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
