

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Finding Non-trivial Opportunities for Parallelism in Existing Serial Code using OpenMP」(http://software.intel.com/en-us/articles/finding-non-trivial-opportunities-for-parallelism-in-existing-serial-code-using-openmp/) の日本語参考訳です。
並列処理の可能性を見つけることができない場合はどうしたら良いか? どのようにしたら並列処理の可能性を見つけられるのか? 既存のコードを並列化する最良の方法は? このホワイトペーパーでは、既存のシリアルコードで並列処理の可能性を発見し、最適化された高いパフォーマンスの並列コードに変換します。
このホワイトペーパーのオリジナル (英語版) ダウンロード:
http://software.intel.com/file/37372
はじめに
ここでは、既存のシリアルコードから並列処理 (スレッド化) の可能性を見つける際の基本事項について説明します。スレッド化により、複数のスレッドを使用して大きなタスクや主要タスクの大部分を同時に実行することで、アプリケーションのパフォーマンスが大幅に向上します。ただし、既存のシリアルコードをスレッド化する場合には特定の課題が伴います。
構造化された並列コードの開発は幅広いトピックであり、多数の書籍があります。このホワイトペーパーは、インテルのエンジニアによって実証された方法を基にして、既存のシリアルコードを並列化することを目的としています。
次の 3 つのセクションで構成されています。
- 並列化の基本概念について
- 既存のシリアルコードを並列化する方法
- シリアルコードの並列処理候補を特定する方法
並列化の概念や並列ソフトウェアの開発に精通している場合は、最初の 2 つのセクションを飛ばして、セクション 3 だけを読んでもかまいません。
並列化の基本概念
並列プログラミングの目的
並列化されたコードは、より多くの計算リソース (複数のコア、シングルコア上の複数の実行ユニットなど) を利用して同時に実行し、一定の時間内により多くのタスクを完了したり、一定のタスクをより短時間で完了することができます。並列実行されるコードは、異なるデータを処理する同一コードの複数のインスタンスであることも、あるいは全く異なるタスクを処理する別々のコードであることもあります。並列実行の種類により、一定のタスクの実行時間、または一定の時間内に処理されるタスクの量 (スループット) が向上します。
並列性と並行性
最近のプロセッサー・マイクロアーキテクチャーでは、その利点を活用するために、可能な場合はコードをスレッド化し、同時かつ並列に実行したほうが良いでしょう。並列性と並行性には関連性がありますが、同じものではありません。それぞれのコードへの影響を理解することは重要です。
並行性とは、2 つ以上のスレッドが同時に進行中の状態のことで、必ずしも同時に実行中でなくてもかまいません。複数のスレッドがパイプラインにあっても、同時にリソースを使用していないため、並列実行と同じリスクや利点はありません。
並列性とは、複数の並行スレッドが同時に実行中の状態のことで、並行実行にはない多くの利点とリスクがあります。
スレッドを同時に実行することで、パフォーマンスと計算リソースの使用率を向上することができます。ただし、複数のスレッドはアプリケーションをより複雑にし、デバッグが困難になります。データ競合、デッドロック、その他の並列化における問題の特定には時間がかかります (インテル® VTune™ Amplifier XE やインテル® Inspector XE のような問題の特定に役立つツールもあります)。
スレッド化と並列性を効率良く実装することは、アプリケーションのパフォーマンスと計算サイズに応じたスケーリングにおいて、大きなメリットをもたらします。
機能分割とデータ分割
多くの場合、コードを並列化する目的は、1 つのタスクを最短時間で完了することです。これは、作業を小さな単位に分割し、それぞれにリソースに割り当てて並列に処理することで実現できます。問題は、作業をどのように分割するかです。同時に処理可能な個別の機能 (タスク) が多数あるか? 適度な大きさのワークロードに分割できるデータが多数あるか? あるいはその両方か?
これらの問いは、コードに内在する並列性の種類を特定するのに役立ちます。そして、これはコードの並列化方法に大きく影響します。
機能分割は、作業を機能別に分割します。これは、個別のタスク数に対応して作業量がスケーリングする場合に最良の方法です。機能分割は、タスクベースの並列化とも呼ばれます。
例えば、家を建てる場合、1 人で作業すると完成までにかかる時間は最長となります。複数の熟練した専門家が、それぞれ (可能であれば並列に) 作業を行えば、より効率良く短時間で完成することができます。コンクリート技師が基礎を作り、大工が骨組みを組み立て、電気技師が配線を引く間に配管工が配管を取り付け、左官工が壁を塗り、内装業者が内装を行うというように、作業を分割します。個別の作業を並列に行うことで、完成までの時間を短縮できます。
自動車の組み立て工程も機能分割の一例です。それぞれの工程で作業員は異なる作業を行い、次の工程へパーツを渡します。ボディーとエンジンの作業は並列に行い、ある工程で一緒にされ 1 台の自動車が完成します。
データ分割は、作業を作業可能な個別のデータの塊 (チャンク) に分割します。これは、データ量に対応して作業量がスケーリングする場合に最良の方法です。
例えば、複数の答案用紙を採点する場合、複数の採点者で作業を分担したほうが短時間で採点を完了することができます。1,000 枚の答案用紙を 10 人で採点すれば、1 人で採点するよりも作業時間を大幅に短縮 (1/10 にカット) できます。地球に落下したスカイラブ宇宙ステーションのパーツの捜索も、データ分割の概念を示す一例です。捜索範囲を分割して、複数の捜索チームが同じ作業を行います。
一般的なアプリケーションでは、道行く大勢の人々の写真といった膨大なデータの中から目の色などの特定のデータパターンを探しますが、このような処理はデータを分割し、それぞれのパターンに対して同じ検索を行うことでより迅速に行うことができます。
並列性と正当性
最適に並列化されたコードはパフォーマンスを大幅に向上させますが、結果が正しくなければ、アルゴリズムとコードの本来の目的を果たすことができません。開発者は、優れた並列化アルゴリズムを選択するか、正しくない結果を受け入れる必要があります (これは場合によっては可能です)。
並列化された乱数生成アルゴリズムやシーケンシャル・アルゴリズムなどは、この判断が難しいでしょう。また、丸めモードの浮動小数点計算の組み合わせでは、正しい結果になるように注意が必要です。
並列パフォーマンス: スピードアップとアムダールの法則
アプリケーションを並列化することでどの程度のスピードアップが達成できるでしょうか? 実行時間を短縮したい場合、達成可能なスピードアップを特定するのにアムダールの法則が役立ちます。達成可能な実行時間の短縮は、並列化するコード中のシリアル領域のサイズと利用可能な計算リソースによって制限されます。
- ・ P = 並列化されたコード領域 (例: 0.3 や 0.7)
- ・ N = 並列領域で利用可能なプロセッサー数
- ・ (1 – P) = コード中のシリアル領域
- ・ O = 並列化のオーバーヘッド
Tparallel = {(1-P) + P/N + O} Tserial
スケーリング = Tserial / Tparallel
N が非常に大きくなると P/N は 0 に近づき、結果はシリアル領域 (1-P) の実行時間に依存することが明白です。例えば上記の式から、(1-P) が 0.5 の場合、P/N をいくら小さくしても、スケーリングは 2.0 に達しません。
説明
スピードアップを最大にするには、コードのシリアル実行時間を最小に抑え、並列処理の可能性を最大限に引き出す必要があります。つまり、アルゴリズム中の明らかに並列化可能なコード領域を並列化するだけでなく、場合によってはより効率良く並列に実行できるようにシリアル・アルゴリズム自身の再設計も必要です。
通常、並列化されたコードはパフォーマンスが向上しますが、必ずしも最良のソリューションとは限りません。場合によっては、高度に最適化されたシリアルコードのほうが、同じアルゴリズムの並列バージョンよりも高速なこともあります。
前のセクションでは、並列化の基本概念を説明しました。ここでは、並列化を実装するためのいくつかの方法を紹介し、潜在的な並列処理の可能性を見つける方法を説明します。
並列化の実装方法
アプリケーションを並列化するには、いくつかの方法があります。どの方法を採用するかは、個々の要因によって決まります。
- コードを実行する計算プラットフォーム。個別のマシンからなる大規模なクラスターのように完全な分散型計算プラットフォーム、32/64/128 コアの対称型マルチプロセッサー・システム、あるいは 4 コアのワークステーションなど。
- 並列化の粒度 (粗粒度または細粒度)。通常、これは計算プラットフォームに影響されます。粒度は、各スレッドが行う作業量と似ています。
- 処理の種類。組込み式のロケット制御システムの並列化や、スーパー・コンピューターで実行される薬物のモデリング・アプリケーションの並列化など。
- パフォーマンス目標。主目的はスループットの向上か、あるいは実行時間の短縮か?
次に、最も一般的な並列化モデルを説明します。
MPI
メッセージ・パッシング・インターフェース (MPI) は、ハイパフォーマンス・コンピューティング (HPC) と広範な分散処理システムで使用される分散型マルチスレッド・モデルです。MPI の API は、明示的なメッセージを使用して、計算システム間で情報の受け渡しを行います。各ノードはスタンドアロンで実行し、MPI メッセージの送信/応答を行います。
MPI は粗粒度の並列化で使用されます。MPI に適した計算プラットフォームの例として、米国国立衛生研究所の LoBoS* (Lots of Boxes on Shelves) のように、ハイパフォーマンスな通信ネットワークで相互接続されたスタンドアロン・サーバーからなるクラスターが挙げられます。
MPI を使用する分散型計算プラットフォームでは、ノード間でメッセージとデータの受け渡しを行わなければならないため、ノード間の通信がシステム全体のパフォーマンスに影響します。また、あるノードで必要なデータが別のノードに保存されている場合があるため、メモリー・アーキテクチャーとパーティショニングもパフォーマンスに大きく影響します。そのため、プログラム全体の設計では、システムで最適なパフォーマンスが得られるように、データモデルと通信の最適化を考慮しなければいけません。
明示的なスレッド化
明示的なスレッド化では、POSIX* スレッド (Pthread)、Windows* スレッド、またはその他のスレッドを使用して、コード内で明示的にスレッドを作成します。スレッド化は開発者によって完全に制御可能なため、開発者のニーズを正確に満たすようにコードをスレッド化できます。
明示的なスレッド化はコードを複雑にしますが、開発者はスレッドの生成、使用、破棄の方法とタイミングをより細かく制御することができます。また、細粒度の並列化でも、粗粒度の並列化でも使用可能で、ほかのスレッド化モデルと組み合わせることもできます。ただし、それにより開発者の課題が増え、アプリケーション全体がより複雑になります。
コンパイラーに指示する並列化
コンパイラーに指示する並列化モデル (または自動並列化) では、OpenMP* やインテル® スレッディング・ビルディング・ブロック (インテル® TBB) のような API を使用して、開発者がスレッド化するコード領域を指示します。そして、対応するコンパイラーがその情報に基づきコンパイル時に自動で必要なスレッドを生成します。
この方法では、スレッド化に伴う開発者の作業は軽減されますが、スレッドの実装方法を細かく制御することはできません。しかし、コンパイラーに指示する並列化は、非常に柔軟で、既存のシリアルコードでも容易に使用することができます。開発者としての経験から、これは並列コードのラピッド・プロトタイピングに最適な方法といえます。そこで、このホワイトペーパーでは、特にこの並列化の実装方法に最適な箇所の特定に注目して説明します。
並列ライブラリー
インテルでは、インテル® プロセッサーで並列処理を最適化するためのさまざまなライブラリーを提供しています。これらのライブラリーは、特定のアプリケーション・ドメイン向けのアルゴリズムを並列化します。
インテル® マス・カーネル・ライブラリー (インテル® MKL) は、極めて高いパフォーマンスが求められる、工学、科学、金融系アプリケーション向けに高度に最適化され、広範囲にスレッド化された数学ルーチンを含むライブラリーです。主要な数学関数として、BLAS、LAPACK、ScaLAPACK1 (ScaLAPACK は Mac OS* X 版ではサポートされません)、スパースソルバー、高速フーリエ変換、ベクトル演算などが含まれています。
Microsoft* Visual Studio*、Eclipse*、および XCode* に統合可能であり、現在および次世代のインテル® プロセッサー向けにパフォーマンスを最適化します。インテル® MKL により、インテルの互換 OpenMP* ランタイム・ライブラリーを完全に統合し、優れた Windows*/Linux* クロスプラットフォームの互換性が得られます。
インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) は、マルチメディア、データ処理、通信アプリケーション向けに高度に最適化された、ソフトウェア関数を備えたマルチコア対応の広範囲なライブラリーです。インテル® IPP は、よく使用される基本的なアルゴリズムを含む、最適化された関数を多数提供します。
C++ テンプレート・ライブラリーであるインテル® スレッディング・ビルディング・ブロック (インテル® TBB) は、スレッドをタスクに抽象化し、安定性を備えた、移植性とスケーラビリティーに優れた並列アプリケーションの開発を支援します。C++ 標準テンプレート・ライブラリー (STL) による言語拡張のように、インテル® TBB は並列化において高レベルの抽象化を提供します。
インテル® TBB は、使い慣れた C++ テンプレートとコーディング方法を使って実装し、下位レベルのスレッド化の詳細をライブラリーに任せることができます。さらに、異なるプロセッサー・アーキテクチャーやオペレーティング・システム間で移植可能です。インテル® TBB により、プログラミングにかかる時間を短縮し、スケーラブルなパフォーマンスと保守が容易なコードを得られます。
次のステップ – 可能性を見つける
これまで並列化の基本といくつかの実装方法について見てきましたが、「どのようにしたら並列処理の可能性を見つけられるのか?」という疑問が残っています。次のセクションでは、並列実行に適した候補を見つけ、それらを並列化する際に直面する一般的な課題の克服方法について見てみましょう。
並列化候補の特定
ボトルネックを特定するためのアプリケーションのプロファイリング
コード中に並列化可能な個所は多数あるかもしれませんが、果たして並列化の労力に見合うだけのパフォーマンスの向上が得られるでしょうか? 通常、この疑問は、コードをプロファイリングして、プロセッサーが時間を費やしている場所を特定しない限り、判断するのが困難です。
インテル® Performance Bottleneck Analyzer (インテル® PBA) のようなパフォーマンス・アナライザーを使ってプロファイリングすると、パフォーマンス・ボトルネックが発生している場所を特定することができます。その結果を基に、並列化やアルゴリズムの最適化の可能性がある場合は、作業すべき場所を特定することができます。
方法
既存のシリアルコードで並列化候補を特定するさまざまな方法については、多数の書籍で取り上げられています。開発者として実際に作業を行ってきた経験から、最も単純なアプローチが最適であるといえます。つまり、ホットコードを見つけることが重要です。ホットコードとは、アプリケーションにおいてほかよりも多くの時間が費やされている領域のことです。一般に、これはループ本体で見つかることが多数です (ただし、常にそうであるとは限りません)。
ホットコードの特定には、インテル® VTune™ Amplifier XE、インテル® パフォーマンス・チューニング・ユーティリティー、インテル® Performance Bottleneck Analyzer のようなサンプリング・ツールを使用します。
データを収集するには、現実的なシナリオでアプリケーションを実行するワークロードが必要です。適切なワークロードの作成に関する詳細は、次の記事を参照してください: 並列ソフトウェアを最適化するための 3 つのステップ。
前述のツールセットには、基本的な解析の使用方法を紹介する詳細なチュートリアルが含まれています (これらのツールへのリンクは、「関連情報」セクションを参照してください)。
適切なワークロードとデータを収集するツールの準備ができたら、並列化候補の特定は簡単です。最も時間を費やしているコード領域を探すだけです。インテル® PBA を使ってサンプル・ワークロードでコードを実行した結果を図 1 に示します。
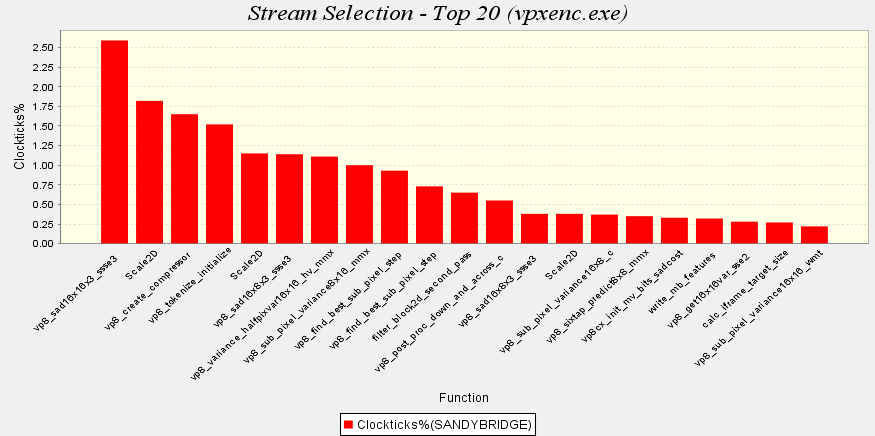
図 1. ホットコードの特定に使用されるインテル® PBA のストリーム・ブレークダウン・グラフ
ホットコードを特定したら、その領域に費やされた時間 (またはサイクル) とその領域に関連した関数別にホットコードを分類する必要があります。ここでも、通常、最適な候補は最も時間がかかったコードになります。一般に、ホットコードの上位 5 つから見てみると良いでしょう。通常、関連する親関数にそれらのホットコードをマップしたほうが開発は容易になります。図 2 を参照してください。
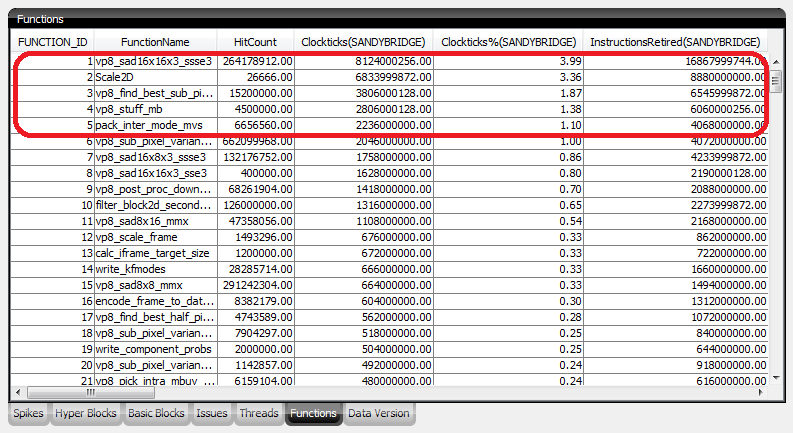
図 2. ホットな関数の特定に使用されるインテル® PBA の関数ブレークダウン・テーブル
いくつかの候補が見つかったら、次のステップではそれらが並列化可能かどうか判断します。
並列化可能な候補か?
シリアルコードを並列化する方法は色々あります。本来ループによる反復処理は、ほかの処理と比べて並列化に適しています。また、このホワイトペーパーでも取り上げているように、マルチスレッドの実装方法は多数あります。ここでは、説明を簡潔にするため、コンパイラーに並列化を指示する OpenMP* プラグマを使ったサンプルに絞って見ていきましょう。前述のように、OpenMP* は処理が軽く、移植性に優れ、必要に応じてシリアルコード中に簡単に記述できます。
ループ (for、do、while など)
シリアルコードを並列化するのに、ループが最適な候補であることは疑問の余地はありません。これは主に、ループの性質上 ‘ワークシェアリング‘ 構造を適用しやすいためです。ワークシェアリングとは、大きな既存の作業を複数の並列に実行されるスレッド間で分割し、それらのスレッド間で作業を分配することです。ループは (前述の) データ分割の一般的な例です。
単純な for ループ
次のループについて、並列化可能かどうか考えてみましょう。
for(i = 0; i < N; i++) c[i] = a[i] + b[i];
ループが並列化に適しているかどうか判断するため、最初にいくつかの項目を確認する必要があります。最も重要なのは、次の項目です。
現在の反復がその前の反復から独立しているか?
つまり、ある反復がその前の反復からの値に依存していてはなりません。上記の例では、ループ本体において、c[i] が代入されている反復以外で利用されることはありません。そのため、このコードの並列化を妨げるループの依存性はありません。
このループは、OpenMP* を使用して次のようにコードを変更することで並列化できます。
#pragma omp parallel for for(i = 0; i < N; i++) c[i] = a[i] + b[i];
omp parallel for 指示句は、このワークシェアリング構造に到達したスレッドのチーム間でループの反復を分配するようにコンパイラーに指示します。
N=12 で、並列領域のスレッドチームに 4 つのスレッドがある場合、上記のプラグマを追加し、OpenMP* に対応するコンパイラーでコンパイルすると、次のような動作になります。
- ループの反復回数 N をスレッド数 4 で割ると、スレッドごとの作業単位は 3 になります。
- 各スレッドには異なる反復のセットが割り当てられます。つまり、1 つ目のスレッドは反復 1 ~ 3、2 つ目のスレッドは反復 4 ~ 6 というようになります。
- 並列領域の最後に 4 つのスレッドは結合され、並列領域の終了時には 1 つのスレッドになります。
この簡単な変更により、実行時間が大幅に短縮されます。このループの並列実行時間は、シリアル実行時間の約 1/4 です。つまり、4 倍も性能が向上したことになります。OpenMP* に精通していなくても、プラグマベースの並列化はシリアルコードへの統合が非常に容易で、大きな利点が得られることが分かります。
より複雑なループ
もう少し複雑なループについて考えてみましょう。このループでは、並列化に伴いいくつかの問題に直面しますが、ここではそれらの問題を克服する手順を見ていきます。このループは、円周率 (Pi) の値を計算する数値積分の例です。ここでは、基本的な積分を求める一般的なコードを使用します。
このコードは、汎関数の 0 から 1 までの区間の積分を計算します。微分・積分の授業から、この積分の解を覚えている方もいるかもしれません。0 から 1 までの区間のこの積分は、Pi の近似値になります。
曲線の下の面積の近似値 (つまり、積分の近似値) を求めるには、多数の小さな長方形の面積 (many = num_steps) を集計します。それぞれの長方形の幅は “step” で、これは num_steps の逆数になります。小さな長方形の面積を計算し、結果をすでに集計済みの面積の合計に加算していきます。
以下にコードを示します。
static long num_steps=100000;
double step, pi;
void main(){
int I;
double x, sum = 0.0;
step = 1.0/(double) num_steps;
for (i=0; I < num_steps; i++){
x = (i +0.5) * step;
sum = sum + 4.0/(1.0 + x * x);
}
pi = step * sum;
}
最初に、並列化の問題を特定する必要があります。この例では、いくつかの問題がありますが、すべて解決可能なものです。
xは各反復で部分和の計算に一時的に使用されるため (上記の例の行 9)、xのプライベート (共有されない) コピーを保持する必要があります。- スレッドごとにそれぞれの
sumを集計しておき、後で最終的な Pi を計算するために渡す必要があります (上記の例の行 11)。ここでは、スレッドごとに個別のsumのプライベート・コピーを作成する、OpenMP* の reduction 節を使用します。 - ループの最後に、コードでそれぞれのスレッドの
sumの値に対して、何らかの処理を実行する必要があります。ここでは部分和を計算するため、reduction 節で “+” 演算子を指定し、各スレッドからの部分和を合計しています。
以下に、必要な omp プラグマを追加したコードを示します。
static long num_steps=100000;
double step, pi;
void main(){
int I;
double x, sum = 0.0;
step = 1.0/(double) num_steps;
#pragma omp parallel for private(x) reduction(+:sum)
for (i=0; I < num_steps; i++){
x = (i +0.5) * step;
sum = sum + 4.0/(1.0 + x * x);
}
pi = step * sum;
}
ここで使用されている OpenMP* の専門用語は分からなくてもかまいません。重要なのは、このループには深刻なループの依存性があるものの、その依存性を制御することで並列化が可能であるという点です。これは、OpenMP* を使用することで容易に行えます。また、従来の明示的なスレッド化モデルによって行うこともできます。
シーケンシャル・アルゴリズム (ハフマン・エンコーディング) の場合
シーケンシャル・アルゴリズムは、シリアルコードを並列化する上で最も大きな課題です。その名のとおり、シーケンシャル・アルゴリズムは正しい結果を得るために特定の順序で処理する必要があります。その典型的な例がハフマン・エンコーディングです。これはコーデックで一般的に使用されていて、エンコードされたコンテンツのビットレートを抑えるために、現在のフレームは前のフレームに依存します。コードを並列化する上で、これは深刻な問題となります。
特定のアルゴリズムではこれを克服する方法がありますが、ここでは本題から外れるため取り上げません。作業を容易にするために、シーケンシャル・アルゴリズムをスレッド化する場合は、アルゴリズムをより並列化しやすいものに変更するか、ほかの並列化手法を検討してみてください。
関数の場合
関数全体がホットコードということもよくあります。そのような関数が (ループ本体で) 繰り返し呼び出される場合、あるいはほかのホットな関数から独立している場合は、機能分割により並列化できる可能性があります。その場合 (その関数により実行されるタスクがループの継続実行を妨げないのであれば)、新しいスレッドをスポーン (起動) してその関数を実行させ、親スレッドは処理を継続します。この典型的な例が、ワープロの自動スペルチェック機能です。ワープロはユーザーからの入力を待機するためにループを実行します。入力を受け取ると、ループ内の別のスレッドが入力ワードのスキャンを開始し、親スレッドは継続して入力を受け付けます。
その他の場合
並列化に適した処理はその他にも多数あります。ここでは本題から外れるため詳しく取り上げませんが、1 つだけ知っておいたほうが良いことがあります。シリアルコードには、その必要がないのに、タスクがシーケンシャルに実行されている場所がよくあります。そこに注目してみると良いでしょう。
まとめ
多くの場合、シリアルコードには多数の並列処理の可能性があり、コードをスレッド化することでパフォーマンスが大幅に向上します。このような可能性を見つけて活用するには、並列化の概念、並列化を実装するためのさまざまなプログラミング手法、およびこれらの可能性を特定する方法を理解する必要があります。
インテル® Performance Bottleneck Analyzer やインテル® VTune Amplifier XE のようなプロファイリングおよびスレッド化ツールを使用することで、シリアルコードにあるスレッド処理の可能性を迅速に見つけることができます。そして、シリアル領域のスレッド化に伴う潜在的な課題を特定し、OpenMP* などのスレッド化手法により素早くコードを並列化できます。
シリアルコードの並列化には課題が伴いますが、それらは効率的な手法やスレッド化手法を用いて克服することができます。結果として、きめ細やかにチューニングされたハイパフォーマンスな並列アプリケーションが得られます。
関連情報
ここで紹介したツール詳細は、以下の Web サイトを参照してください。
インテル® VTune™ Amplifier XE
インテル® パフォーマンス・チューニング・ユーティリティー (http://software.intel.com/en-us/articles/intel-performance-tuning-utility/)
インテル® Performance Bottleneck Analyzer (http://software.intel.com/en-us/articles/intel-performance-bottleneck-analyzer/)
インテル® スレッディング・ビルディング・ブロック
コミュニティーへの参加
同じ課題に取り組んでいるほかの人々と情報を共有することは、何かを学ぶ上で最良の方法といえます。並列アプリケーションへの取り組み (成功したことや失敗したこと) を是非ほかの開発者と共有してください。業界のほかの開発者やインテル社のエキスパートが、あなたが直面している問題の解決を支援します (あるいは、あなたがほかの開発者を支援することができます)。
- コミュニティー・フォーラム: Threading on Intel® Parallel Architectures (http://software.intel.com/en-us/forums/threading-on-intel-parallel-architectures/) もしくは iSUS フォーラム (日本語)
- Intel® Parallel Programming and Multi-Core Developer Community (http://software.intel.com/en-us/parallel/ (英語)) は、最新のドキュメント、ツールに加えて、ソフトウェア業界のブログやフォーラムなどのコミュニティー・リソースを提供しています。
- インテル® ソフトウェア開発製品 は、ソフトウェア・ライフサイクル全体を通して効率的にスレッド化し、コーディングと最適化のプロセスを合理化します。
- マルチコア・ソフトウェア開発者向けの技術資料 (http://software.intel.com/en-us/articles/technical-books-for-multi-core-software-developers/) には、インテル® ソフトウェア・ネットワークにより厳選された技術文献のリストがあります。
- 並列プログラミングの技術用語集 は、インテル® ソフトウェア・ネットワークで公開されているウィキで、コミュニティーの情報共有を利用して語彙を強化できます。
著者紹介
 Erik Niemeyer は、インテル社のソフトウェア & ソリューション・グループのソフトウェア・エンジニアで、 10 年以上にわたってインテル® マイクロプロセッサーにおけるアプリケーション・パフォーマンスの最適化に取り組んでおり、特にラピッド並列開発とマイクロアーキテクチャーのチューニングを専門としています。趣味は山登りで、オフの時間はたいていどこかの山の上にいます。Erik の連絡先は erik.a.niemeyer@intel.com です。
Erik Niemeyer は、インテル社のソフトウェア & ソリューション・グループのソフトウェア・エンジニアで、 10 年以上にわたってインテル® マイクロプロセッサーにおけるアプリケーション・パフォーマンスの最適化に取り組んでおり、特にラピッド並列開発とマイクロアーキテクチャーのチューニングを専門としています。趣味は山登りで、オフの時間はたいていどこかの山の上にいます。Erik の連絡先は erik.a.niemeyer@intel.com です。
 Ken Strandberg 氏は、IT マーケティング・コミュニケーション会社 Catlow Communications* (www.catlowcommunications.com) の社長です。新興 の IT 企業から、Fortune 100 社にランキングされている企業、および多国籍企業向けに、広範囲な IT 関連のマーケティングおよびマーケティング以外のコンテンツ、ビデオ、インタラクティブ・スクリプト、教育プログラムを作成しており、ハードウェアおよびソフトウェア業界を幅広くカバーしています。Strandberg 氏の連絡先は ken@catlowcommunications.com です。
Ken Strandberg 氏は、IT マーケティング・コミュニケーション会社 Catlow Communications* (www.catlowcommunications.com) の社長です。新興 の IT 企業から、Fortune 100 社にランキングされている企業、および多国籍企業向けに、広範囲な IT 関連のマーケティングおよびマーケティング以外のコンテンツ、ビデオ、インタラクティブ・スクリプト、教育プログラムを作成しており、ハードウェアおよびソフトウェア業界を幅広くカバーしています。Strandberg 氏の連絡先は ken@catlowcommunications.com です。
編集部追加
本記事はいかがでしたか? 現在の、そして将来のプロセッサーに対しては、ますます処理を並列に実行することの重要性が高まっていくと予想されます。アプリケーション・レベルでの並列化では、開発者がコードにおける並列性を指示しなければなりませんが、そのためには本記事で紹介した OpenMP* のような、より容易な記述方法を選択できるようになっています。ホットコード(アプリケーションにおいて、より多くの時間が費やされている部分)の特定や、並列化における正当性の検証、およびパフォーマンスの確認には、専用のツールを使用できます。
インテルでは、並列アプリケーション開発者のために、このような機能やツールを1パッケージにて提供する「インテル® Parallel Studio XE」および「インテル® Cluster Studio XE」を販売しています。インテル® ソフトウェア開発製品についての詳細、および評価版のダウンロード方法は、エクセルソフト株式会社までお問い合わせください。
